Offline Reinforcement Learning with Penalized Action Noise Injection
作者: JunHyeok Oh, Byung-Jun Lee
分类: cs.LG, cs.AI
发布日期: 2025-07-03
💡 一句话要点
提出PANI:通过惩罚性动作噪声注入提升离线强化学习性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 动作噪声注入 策略泛化 惩罚机制 马尔可夫决策过程
📋 核心要点
- 离线强化学习依赖固定数据集,泛化能力至关重要,但现有方法(如扩散模型)计算成本高昂。
- PANI通过注入噪声动作并施加惩罚来扩展动作空间,提升策略泛化能力,灵感来源于扩散模型。
- PANI具有理论基础,兼容多种离线RL算法,并在多个benchmark上取得了显著的性能提升。
📝 摘要(中文)
离线强化学习(RL)仅使用固定的数据集优化策略,使其成为与环境交互成本高昂的场景中的一种实用方法。由于这种限制,泛化能力是提高离线RL算法性能的关键,正如最近扩散模型在离线RL中的成功所证明的那样。然而,考虑到扩散模型在推理过程中显著的计算需求,这种模型对于高性能离线RL算法是否是必要的仍然值得怀疑。在本文中,我们提出了一种惩罚性动作噪声注入(PANI)方法,该方法通过利用噪声注入的动作来覆盖整个动作空间,并根据注入的噪声量进行惩罚,从而简单地增强离线学习。这种方法的灵感来自于扩散模型在离线RL算法中的工作方式。我们为该方法提供了理论基础,表明具有这种噪声注入动作的离线RL算法解决了修改后的马尔可夫决策过程(MDP),我们称之为噪声动作MDP。PANI与各种现有的离策略和离线RL算法兼容,并且尽管其简单性,但在各种基准测试中都表现出显著的性能改进。
🔬 方法详解
问题定义:离线强化学习面临泛化性挑战,现有方法如扩散模型虽然有效,但计算成本高昂,限制了其应用。如何在不引入过多计算负担的前提下,提升离线RL算法的性能是本文要解决的核心问题。
核心思路:PANI的核心思路是通过向动作中注入噪声来扩展策略的覆盖范围,从而提高泛化能力。同时,为了避免过度探索导致策略偏离数据集,PANI对注入的噪声进行惩罚,引导策略学习更安全、更有效的行为。这种方法借鉴了扩散模型扩展动作空间的思想,但避免了复杂的生成过程。
技术框架:PANI可以作为一个模块嵌入到现有的离策略和离线RL算法中。其主要流程如下:1) 从离线数据集中采样状态;2) 使用策略网络生成动作;3) 向动作中注入噪声,生成噪声动作;4) 使用噪声动作和原始动作计算惩罚项;5) 将噪声动作、状态、奖励和惩罚项输入到RL算法中进行训练。
关键创新:PANI的关键创新在于将噪声注入和惩罚机制相结合,在扩展动作空间的同时,保证了策略学习的安全性。与直接使用扩散模型相比,PANI更加简单高效,易于实现和部署。此外,论文还提供了理论分析,证明了PANI实际上是在解决一个修改后的MDP问题,即噪声动作MDP。
关键设计:PANI的关键设计包括:1) 噪声注入方式:可以使用高斯噪声或其他类型的噪声;2) 惩罚函数:惩罚函数的设计需要平衡探索和利用,避免过度探索或欠探索;3) 噪声水平的控制:需要根据具体任务调整噪声水平,以获得最佳性能。论文中具体使用的噪声类型和惩罚函数等细节未知。
🖼️ 关键图片
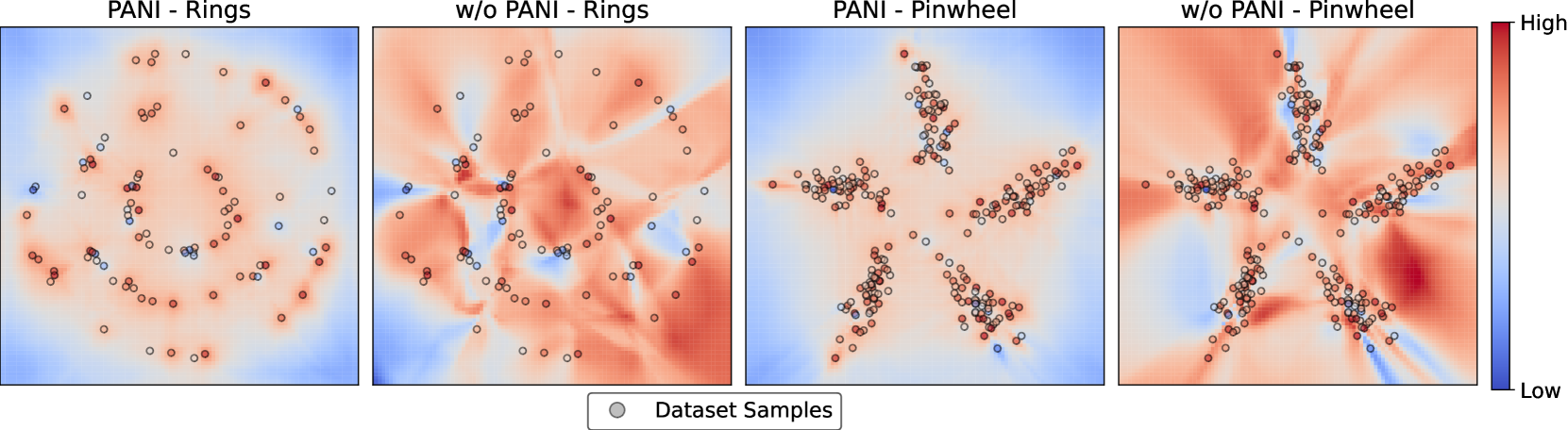
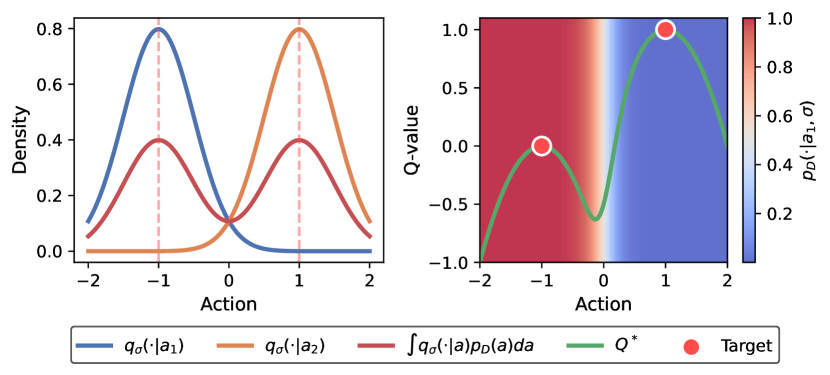
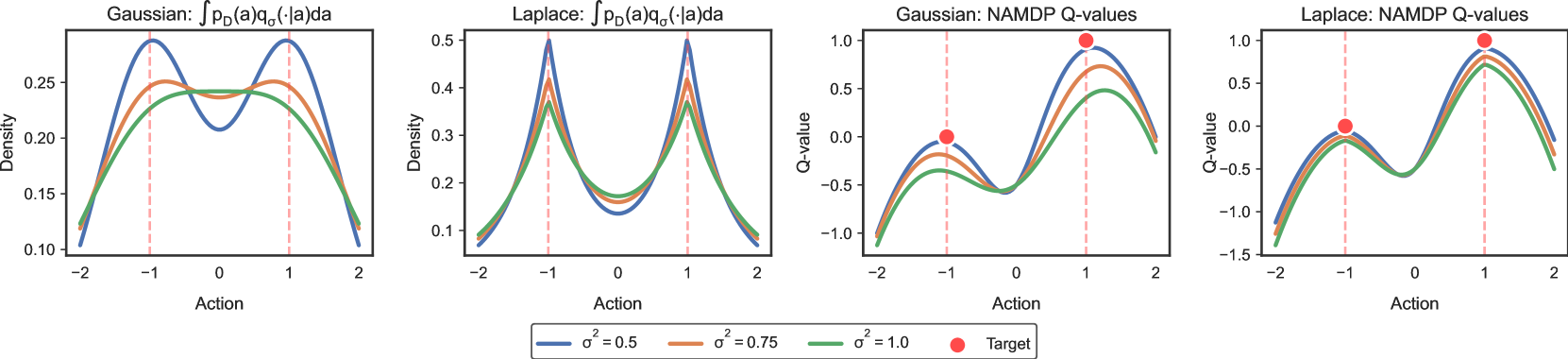
📊 实验亮点
PANI在多个离线强化学习benchmark上取得了显著的性能提升,证明了其有效性。具体提升幅度未知,但论文强调PANI在各种benchmark上均优于现有方法,并且与现有离策略和离线RL算法兼容,易于集成。PANI的性能提升表明,通过简单的噪声注入和惩罚机制,可以有效地提高离线强化学习的泛化能力。
🎯 应用场景
PANI可应用于各种需要离线强化学习的场景,例如机器人控制、自动驾驶、推荐系统和金融交易等。在这些场景中,与环境交互的成本很高,因此离线强化学习是一种很有吸引力的选择。PANI的简单性和有效性使其成为一种很有前景的解决方案,可以帮助提高这些应用的性能和安全性。
📄 摘要(原文)
Offline reinforcement learning (RL) optimizes a policy using only a fixed dataset, making it a practical approach in scenarios where interaction with the environment is costly. Due to this limitation, generalization ability is key to improving the performance of offline RL algorithms, as demonstrated by recent successes of offline RL with diffusion models. However, it remains questionable whether such diffusion models are necessary for highly performing offline RL algorithms, given their significant computational requirements during inference. In this paper, we propose Penalized Action Noise Injection (PANI), a method that simply enhances offline learning by utilizing noise-injected actions to cover the entire action space, while penalizing according to the amount of noise injected. This approach is inspired by how diffusion models have worked in offline RL algorithms. We provide a theoretical foundation for this method, showing that offline RL algorithms with such noise-injected actions solve a modified Markov Decision Process (MDP), which we call the noisy action MDP. PANI is compatible with a wide range of existing off-policy and offline RL algorithms, and despite its simplicity, it demonstrates significant performance improvements across various benchmarks.