Blending Supervised and Reinforcement Fine-Tuning with Prefix Sampling
作者: Zeyu Huang, Tianhao Cheng, Zihan Qiu, Zili Wang, Yinghui Xu, Edoardo M. Ponti, Ivan Titov
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-07-02 (更新: 2025-09-24)
备注: Work in progress
💡 一句话要点
提出Prefix-RFT,融合监督微调与强化微调,提升LLM在数学推理问题上的性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 监督学习 大型语言模型 微调 数学推理
📋 核心要点
- 现有SFT易于行为克隆,泛化能力受限;RFT性能虽高,但易学到不良行为,且对初始策略敏感。
- Prefix-RFT融合SFT和RFT,从演示数据和探索中学习,协调两种范式,提升模型性能。
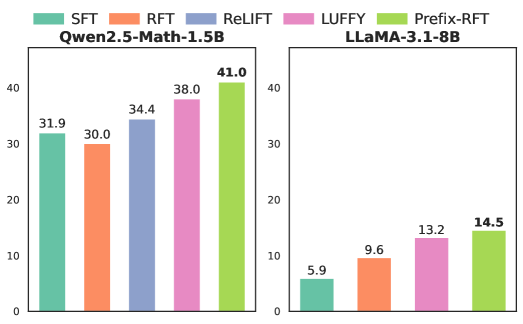
- 实验表明Prefix-RFT在数学推理问题上优于SFT、RFT及混合策略RFT,且易于集成到现有框架。
📝 摘要(中文)
本文提出了一种统一的视角来审视大型语言模型的监督微调(SFT)和强化微调(RFT)两种后训练技术,并提出了一种混合方法Prefix-RFT,它协同地从演示数据和探索中学习。SFT擅长模仿演示数据,但可能导致有问题的泛化,成为一种行为克隆。RFT可以显著提高模型的性能,但容易学习到意想不到的行为,并且其性能对初始策略高度敏感。在数学推理问题上进行的实验表明,Prefix-RFT既简单又有效,不仅超越了单独的SFT和RFT,而且优于并行的混合策略RFT方法。它的一个关键优势是可以无缝集成到现有的开源框架中,只需要对标准的RFT流程进行最小的修改。分析强调了SFT和RFT的互补性,并验证了Prefix-RFT有效地协调了这两种学习范式。消融研究证实了该方法对演示数据质量和数量变化的鲁棒性。这项工作为LLM后训练提供了一个新的视角,表明统一的范式,即明智地整合演示和探索,可能是未来研究的一个有希望的方向。
🔬 方法详解
问题定义:现有的大型语言模型后训练方法,如监督微调(SFT)和强化微调(RFT),各有优缺点。SFT擅长模仿训练数据,但容易陷入行为克隆,泛化能力受限。RFT虽然能提升性能,但容易学习到不期望的行为,且对初始策略非常敏感。因此,如何有效地结合两者的优点,避免各自的缺点,是一个亟待解决的问题。
核心思路:Prefix-RFT的核心思路是将SFT和RFT结合起来,利用SFT提供良好的初始策略和模仿能力,同时利用RFT进行探索和优化,避免陷入局部最优。通过在RFT过程中引入SFT的先验知识,引导模型学习更期望的行为,提高模型的泛化能力和鲁棒性。
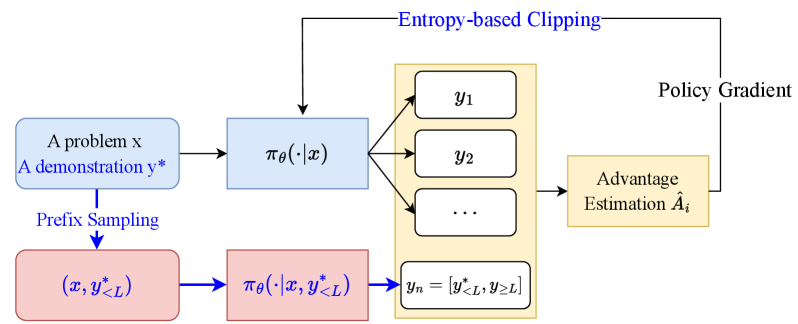
技术框架:Prefix-RFT的整体框架基于标准的RFT流程,主要包括以下几个阶段:1) 使用SFT对模型进行预训练,使其具备一定的模仿能力。2) 在RFT阶段,使用SFT预训练的模型作为初始策略。3) 在RFT过程中,引入一个前缀采样机制,即在生成token时,以一定的概率从SFT模型中采样,以一定的概率从RFT模型中采样。4) 使用标准的强化学习算法(如PPO)对模型进行训练。
关键创新:Prefix-RFT的关键创新在于提出了前缀采样机制,它允许模型在RFT过程中动态地选择从SFT模型或RFT模型中采样,从而有效地结合了SFT和RFT的优点。与传统的混合策略RFT方法不同,Prefix-RFT不需要训练多个模型,而是通过一个模型来实现SFT和RFT的融合。
关键设计:Prefix-RFT的关键设计包括:1) 前缀采样概率的设置,需要根据具体任务进行调整,以平衡SFT和RFT的影响。2) 强化学习算法的选择,可以选择PPO等常用的算法。3) 奖励函数的设计,需要根据具体任务进行设计,以引导模型学习期望的行为。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Prefix-RFT在数学推理问题上取得了显著的性能提升,超越了单独的SFT和RFT方法,以及并行的混合策略RFT方法。消融研究表明,Prefix-RFT对演示数据的质量和数量具有较强的鲁棒性,即使在演示数据质量较低或数量较少的情况下,也能取得较好的性能。
🎯 应用场景
Prefix-RFT方法具有广泛的应用前景,可以应用于各种需要结合模仿学习和强化学习的场景,例如机器人控制、对话生成、文本摘要等。该方法可以提高模型的性能、泛化能力和鲁棒性,使其能够更好地适应复杂的环境和任务。
📄 摘要(原文)
Existing post-training techniques for large language models are broadly categorized into Supervised Fine-Tuning (SFT) and Reinforcement Fine-Tuning (RFT). Each paradigm presents a distinct trade-off: SFT excels at mimicking demonstration data but can lead to problematic generalization as a form of behavior cloning. Conversely, RFT can significantly enhance a model's performance but is prone to learn unexpected behaviors, and its performance is highly sensitive to the initial policy. In this paper, we propose a unified view of these methods and introduce Prefix-RFT, a hybrid approach that synergizes learning from both demonstration and exploration. Using mathematical reasoning problems as a testbed, we empirically demonstrate that Prefix-RFT is both simple and effective. It not only surpasses the performance of standalone SFT and RFT but also outperforms parallel mixed-policy RFT methods. A key advantage is its seamless integration into existing open-source frameworks, requiring only minimal modifications to the standard RFT pipeline. Our analysis highlights the complementary nature of SFT and RFT, and validates that Prefix-RFT effectively harmonizes these two learning paradigms. Furthermore, ablation studies confirm the method's robustness to variations in the quality and quantity of demonstration data. We hope this work offers a new perspective on LLM post-training, suggesting that a unified paradigm that judiciously integrates demonstration and exploration could be a promising direction for future research.