Self-Guided Process Reward Optimization with Redefined Step-wise Advantage for Process Reinforcement Learning
作者: Wu Fei, Hao Kong, Shuxian Liang, Yang Lin, Yibo Yang, Jing Tang, Lei Chen, Xiansheng Hua
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-07-02 (更新: 2025-07-03)
💡 一句话要点
SPRO:通过自引导过程奖励优化和重定义的步进优势提升过程强化学习效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 过程强化学习 自引导学习 奖励优化 优势估计 大型语言模型 策略梯度 掩码步进优势
📋 核心要点
- 过程强化学习面临计算开销大和缺乏统一的过程级别优势估计理论框架的挑战。
- SPRO通过从策略模型本身导出过程奖励,并引入掩码步进优势估计来解决这些问题。
- 实验表明,SPRO在训练效率和测试精度上均优于现有方法,并能有效防止奖励黑客行为。
📝 摘要(中文)
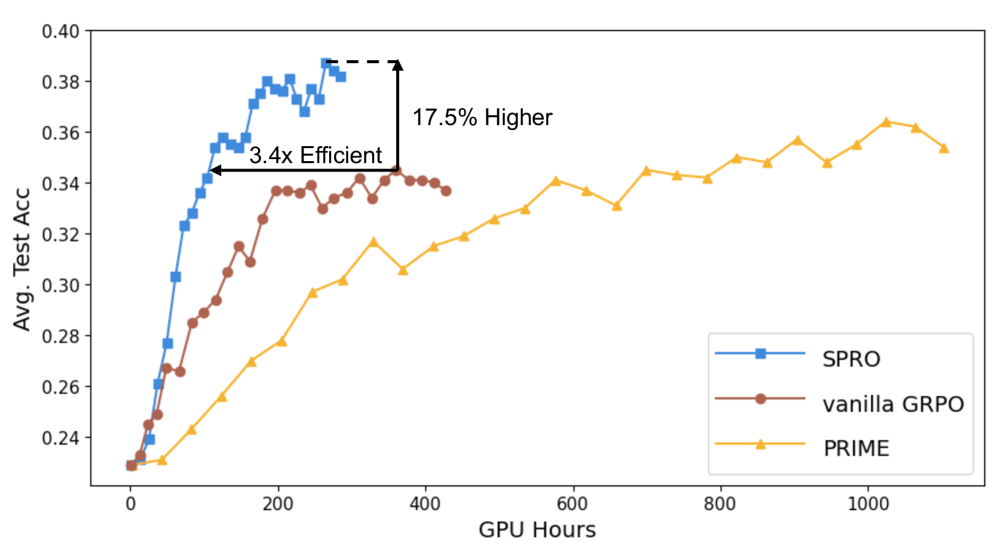
过程强化学习(PRL)在增强大型语言模型(LLM)的推理能力方面展现了巨大潜力。然而,引入额外的过程奖励模型会带来巨大的计算开销,并且缺乏过程级别优势估计的统一理论框架。为了弥合这一差距,我们提出了自引导过程奖励优化(SPRO),这是一个新颖的框架,通过两个关键创新实现过程感知的RL:(1) 我们首先从理论上证明了过程奖励可以从策略模型本身内在地导出;(2) 我们引入了明确定义的累积过程奖励和掩码步进优势(MSA),这有助于在共享提示采样组内进行严格的步进动作优势估计。实验结果表明,SPRO优于vanilla GRPO,训练效率提高了3.4倍,测试精度提高了17.5%。此外,SPRO在整个训练过程中保持稳定和较高的策略熵,同时将平均响应长度减少约1/3,证明了充分的探索和防止奖励黑客行为。值得注意的是,与GRPO等结果监督的RL方法相比,SPRO没有产生额外的计算开销,这有利于工业实施。
🔬 方法详解
问题定义:过程强化学习旨在提升大型语言模型在复杂任务中的推理能力,但现有方法如GRPO依赖额外的过程奖励模型,导致计算开销显著增加。此外,缺乏统一的理论框架来有效估计过程级别的优势函数,限制了算法的性能和可解释性。
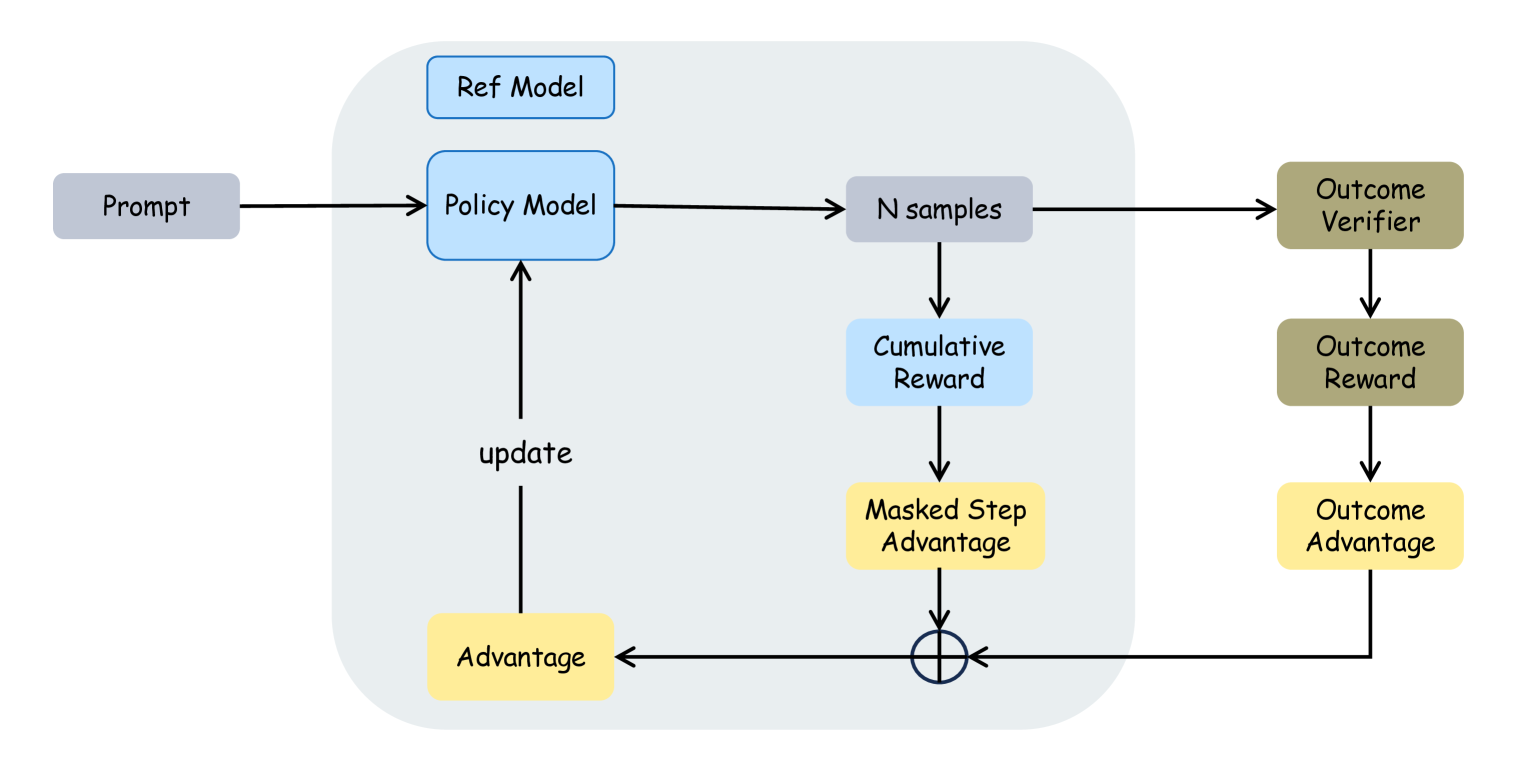
核心思路:SPRO的核心思想是从策略模型本身内在地导出过程奖励,避免引入额外的奖励模型。通过这种方式,可以显著降低计算成本,并建立一个更简洁、高效的训练框架。此外,SPRO引入了掩码步进优势(MSA)的概念,用于更精确地估计每一步动作的优势,从而指导策略的优化。
技术框架:SPRO框架主要包含以下几个关键步骤:首先,利用策略模型生成一系列动作序列。然后,基于这些动作序列,计算累积过程奖励,该奖励直接从策略模型的输出中导出。接下来,使用MSA来估计每个动作的优势,并利用这些优势来更新策略模型。整个过程是自引导的,无需额外的奖励模型。
关键创新:SPRO最重要的创新在于其自引导的过程奖励机制,它避免了对额外奖励模型的依赖,从而显著降低了计算开销。此外,MSA的引入使得能够更精确地估计每一步动作的优势,从而更有效地指导策略的优化。与现有方法相比,SPRO在效率和性能上都具有显著优势。
关键设计:SPRO的关键设计包括:1) 从策略模型导出过程奖励的具体方法,例如,可以使用策略模型的置信度或概率分布来衡量动作的质量。2) MSA的计算方式,需要仔细设计掩码策略,以确保优势估计的准确性。3) 策略模型的选择和训练方式,需要选择合适的模型架构和优化算法,以确保模型的性能和稳定性。
🖼️ 关键图片

📊 实验亮点
SPRO在实验中表现出色,相较于vanilla GRPO,训练效率提升了3.4倍,测试精度提高了17.5%。此外,SPRO在训练过程中保持了稳定且较高的策略熵,表明其具有良好的探索能力,并有效避免了奖励黑客行为。同时,SPRO还将平均响应长度减少了约1/3,表明其生成的策略更加简洁高效。
🎯 应用场景
SPRO具有广泛的应用前景,例如可以应用于对话系统、机器人控制、自动驾驶等领域。通过提升大型语言模型的推理能力,SPRO可以帮助构建更智能、更高效的AI系统。由于其计算效率高,SPRO特别适合在资源受限的环境中部署,例如移动设备或嵌入式系统。未来,SPRO有望成为过程强化学习领域的重要基石。
📄 摘要(原文)
Process Reinforcement Learning~(PRL) has demonstrated considerable potential in enhancing the reasoning capabilities of Large Language Models~(LLMs). However, introducing additional process reward models incurs substantial computational overhead, and there is no unified theoretical framework for process-level advantage estimation. To bridge this gap, we propose \textbf{S}elf-Guided \textbf{P}rocess \textbf{R}eward \textbf{O}ptimization~(\textbf{SPRO}), a novel framework that enables process-aware RL through two key innovations: (1) we first theoretically demonstrate that process rewards can be derived intrinsically from the policy model itself, and (2) we introduce well-defined cumulative process rewards and \textbf{M}asked \textbf{S}tep \textbf{A}dvantage (\textbf{MSA}), which facilitates rigorous step-wise action advantage estimation within shared-prompt sampling groups. Our experimental results demonstrate that SPRO outperforms vaniila GRPO with 3.4x higher training efficiency and a 17.5\% test accuracy improvement. Furthermore, SPRO maintains a stable and elevated policy entropy throughout training while reducing the average response length by approximately $1/3$, evidencing sufficient exploration and prevention of reward hacking. Notably, SPRO incurs no additional computational overhead compared to outcome-supervised RL methods such as GRPO, which benefit industrial implementation.