FaithfulSAE: Towards Capturing Faithful Features with Sparse Autoencoders without External Dataset Dependencies
作者: Seonglae Cho, Harryn Oh, Donghyun Lee, Luis Eduardo Rodrigues Vieira, Andrew Bermingham, Ziad El Sayed
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-06-21
备注: 18 pages, 18 figures
💡 一句话要点
FaithfulSAE:利用模型自生成数据训练稀疏自编码器,提升特征忠实度
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 稀疏自编码器 可解释性 大型语言模型 分布外数据 伪特征
📋 核心要点
- 现有SAE方法依赖外部数据集,可能包含分布外数据,导致提取的特征不忠实于模型内部表示,产生“伪特征”。
- FaithfulSAE通过在模型自身生成的合成数据集上训练SAE,减少分布外数据的影响,从而更准确地捕获模型内部的真实特征。
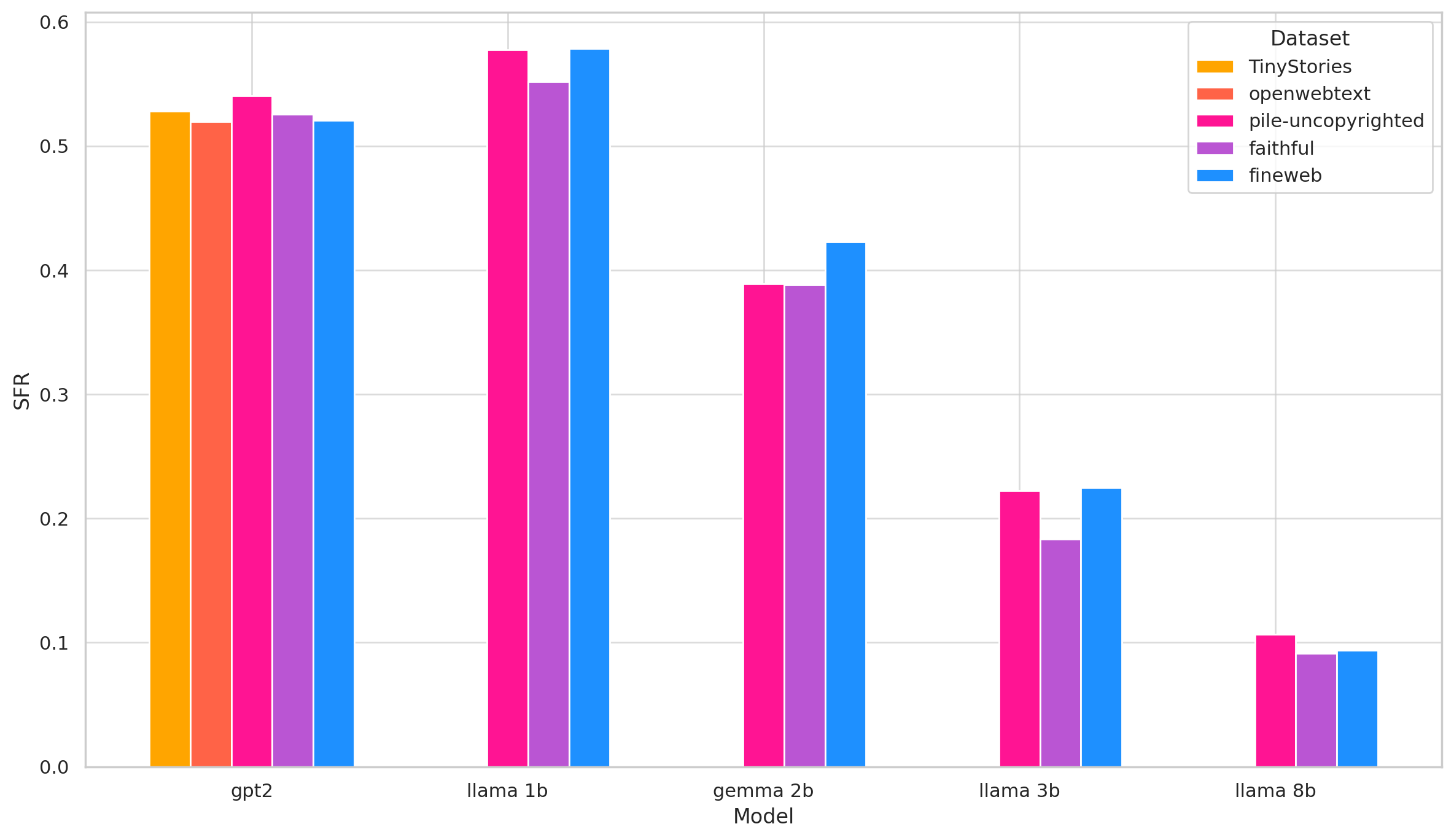
- 实验表明,FaithfulSAE在SAE探测任务中优于使用Web数据集训练的SAE,并在多个模型上降低了伪特征率,提升了特征的稳定性。
📝 摘要(中文)
稀疏自编码器(SAE)已成为将大型语言模型表示分解为可解释特征的有前景的解决方案。然而,Paulo和Belrose(2025)强调了不同初始化种子之间的不稳定性,Heap等人(2025)指出SAE可能无法捕获模型内部特征。这些问题可能源于在外部数据集上训练SAE,这些数据集可能包含超出模型泛化能力的分布外(OOD)数据。这可能导致虚假的SAE特征,我们称之为“伪特征”,从而错误地表示模型的内部激活。为了解决这些问题,我们提出了FaithfulSAE,一种在模型自身合成数据集上训练SAE的方法。使用FaithfulSAE,我们证明在较少OOD的指令数据集上训练SAE可以提高种子之间的稳定性。值得注意的是,FaithfulSAE在SAE探测任务中优于在基于Web的数据集上训练的SAE,并且在7个模型中的5个模型中表现出较低的伪特征率。总的来说,我们的方法消除了对外部数据集的依赖,通过更好地捕获模型内部特征来提高可解释性,同时突出了SAE训练数据集经常被忽视的重要性。
🔬 方法详解
问题定义:现有稀疏自编码器(SAE)在训练时依赖于外部数据集,这些数据集可能包含与目标模型所训练数据分布不同的样本(分布外数据,OOD)。这会导致SAE学习到一些虚假的、并非模型真正使用的特征(伪特征),从而影响模型的可解释性,并降低SAE的稳定性。因此,需要一种方法来减少OOD数据的影响,使SAE能够更忠实地捕获模型内部的真实特征。
核心思路:FaithfulSAE的核心思路是使用目标模型自身生成的数据来训练SAE。这样可以保证训练数据与模型内部表示的一致性,从而减少OOD数据的影响,避免学习到伪特征。通过让模型“自给自足”,可以更准确地提取模型真正使用的特征,提高SAE的稳定性和可解释性。
技术框架:FaithfulSAE的整体框架包括以下几个主要步骤:1. 数据生成:使用目标模型生成合成数据集。具体来说,可以利用模型的指令遵循能力,输入不同的指令,并记录模型的输出作为训练数据。2. SAE训练:使用生成的合成数据集训练SAE。SAE的目标是学习一个稀疏的编码器,能够将模型的内部表示压缩成一组稀疏的特征。3. 特征评估:评估SAE学习到的特征的质量。可以使用SAE探测任务和伪特征率等指标来评估特征的忠实度和稳定性。
关键创新:FaithfulSAE最重要的创新点在于使用模型自身生成的数据来训练SAE,从而消除了对外部数据集的依赖。与现有方法相比,FaithfulSAE能够更有效地减少OOD数据的影响,避免学习到伪特征,从而提高SAE的稳定性和可解释性。这种“自训练”的思想为SAE的训练提供了一种新的思路。
关键设计:在数据生成阶段,需要仔细设计指令,以确保生成的数据能够覆盖模型内部表示的各个方面。在SAE训练阶段,可以使用不同的稀疏性约束来控制特征的稀疏程度。在特征评估阶段,可以使用不同的指标来评估特征的质量,例如SAE探测任务的准确率和伪特征率。具体的损失函数和网络结构的选择可以根据具体的应用场景进行调整。
🖼️ 关键图片


📊 实验亮点
实验结果表明,FaithfulSAE在SAE探测任务中优于使用Web数据集训练的SAE,证明了其能够更准确地捕获模型内部的真实特征。此外,FaithfulSAE在7个模型中的5个模型中表现出较低的伪特征率,表明其能够有效地减少OOD数据的影响,提高SAE的稳定性。这些结果验证了FaithfulSAE的有效性和优越性。
🎯 应用场景
FaithfulSAE可应用于大型语言模型的可解释性研究,帮助研究人员理解模型的内部工作机制,发现模型可能存在的偏见或漏洞。此外,该方法还可以用于模型的压缩和优化,通过提取模型最重要的特征,减少模型的参数量,提高模型的效率。该方法在安全攸关的应用中具有重要价值,例如自动驾驶、医疗诊断等。
📄 摘要(原文)
Sparse Autoencoders (SAEs) have emerged as a promising solution for decomposing large language model representations into interpretable features. However, Paulo and Belrose (2025) have highlighted instability across different initialization seeds, and Heap et al. (2025) have pointed out that SAEs may not capture model-internal features. These problems likely stem from training SAEs on external datasets - either collected from the Web or generated by another model - which may contain out-of-distribution (OOD) data beyond the model's generalisation capabilities. This can result in hallucinated SAE features, which we term "Fake Features", that misrepresent the model's internal activations. To address these issues, we propose FaithfulSAE, a method that trains SAEs on the model's own synthetic dataset. Using FaithfulSAEs, we demonstrate that training SAEs on less-OOD instruction datasets results in SAEs being more stable across seeds. Notably, FaithfulSAEs outperform SAEs trained on web-based datasets in the SAE probing task and exhibit a lower Fake Feature Ratio in 5 out of 7 models. Overall, our approach eliminates the dependency on external datasets, advancing interpretability by better capturing model-internal features while highlighting the often neglected importance of SAE training datasets.