PLD: A Choice-Theoretic List-Wise Knowledge Distillation
作者: Ejafa Bassam, Dawei Zhu, Kaigui Bian
分类: cs.LG, cs.AI, cs.CV, stat.ML
发布日期: 2025-06-14 (更新: 2025-10-23)
💡 一句话要点
提出基于选择理论的列表式知识蒸馏方法PLD,提升模型压缩性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 知识蒸馏 模型压缩 Plackett-Luce模型 排序学习 深度学习 模型优化 列表式损失 选择理论
📋 核心要点
- 现有基于logits的知识蒸馏方法通常需要手动调整蒸馏损失的权重,过程繁琐且效果不稳定。
- PLD方法将教师模型的logits视为“价值”分数,并利用Plackett-Luce模型构建列表式排序损失,直接优化教师最优排序。
- 实验结果表明,PLD在多个数据集和模型架构上,相较于现有蒸馏方法,均取得了显著的性能提升。
📝 摘要(中文)
知识蒸馏是一种模型压缩技术,其中训练一个紧凑的“学生”网络来复制一个更大的“教师”网络的预测行为。在基于logits的知识蒸馏中,将交叉熵与蒸馏项结合已成为事实上的方法。通常,这个蒸馏项要么是匹配边缘概率的KL散度,要么是捕获类内和类间关系的基于相关的损失。在任何情况下,它都作为交叉熵的附加项存在,并且具有需要仔细调整的权重。本文采用选择理论的视角,通过将教师logits解释为“价值”分数,在Plackett-Luce模型下重新构建知识蒸馏。我们引入了“Plackett-Luce Distillation (PLD)”,这是一种加权列表式排序损失。在PLD中,教师模型传递其完整类别排序的知识,并根据其自身的置信度对每个排序的选择进行加权。PLD直接优化单个“教师最优”排序:首先放置真实标签,然后按照教师置信度降序排列其余类别。这个过程产生了一个凸且平移不变的替代项,它包含了加权交叉熵。在CIFAR-100、ImageNet-1K和MS-COCO上的实验表明,PLD在同构和异构的师生对中,跨不同的架构和蒸馏目标(包括基于散度、基于相关性和基于特征的方法)都实现了持续的提升。
🔬 方法详解
问题定义:现有的知识蒸馏方法,特别是基于logits的方法,通常将蒸馏损失作为交叉熵损失的附加项。这个附加项的权重需要手动调整,这使得训练过程变得复杂且耗时。此外,这些方法通常关注于匹配边缘概率或类间的关系,而忽略了教师模型提供的更丰富的排序信息。
核心思路:PLD的核心思路是将教师模型的logits视为每个类别的“价值”或“吸引力”,并利用Plackett-Luce模型来构建一个基于排序的损失函数。通过优化这个损失函数,学生模型可以学习到教师模型对所有类别的排序,而不仅仅是概率最高的类别。这种方法能够更有效地利用教师模型的知识,并避免了手动调整蒸馏损失权重的需要。
技术框架:PLD方法的整体框架如下:首先,使用教师模型对输入样本进行预测,得到logits。然后,将这些logits视为每个类别的“价值”分数。接下来,根据Plackett-Luce模型,构建一个列表式排序损失函数,该函数的目标是使学生模型的预测结果尽可能接近教师模型的排序。最后,使用梯度下降等优化算法来训练学生模型,使其最小化这个损失函数。
关键创新:PLD的关键创新在于它将知识蒸馏问题重新定义为一个排序问题,并利用Plackett-Luce模型来构建损失函数。与传统的基于散度或相关的蒸馏方法不同,PLD直接优化教师模型提供的排序信息,从而更有效地传递知识。此外,PLD方法不需要手动调整蒸馏损失的权重,这使得训练过程更加简单和稳定。
关键设计:PLD的关键设计包括:1) 使用教师模型的logits作为Plackett-Luce模型的“价值”分数。2) 构建一个列表式排序损失函数,该函数的目标是使学生模型的预测结果尽可能接近教师模型的排序。具体来说,该损失函数将真实标签放在第一位,然后按照教师置信度降序排列其余类别。3) 使用凸优化算法来最小化该损失函数,从而训练学生模型。
🖼️ 关键图片
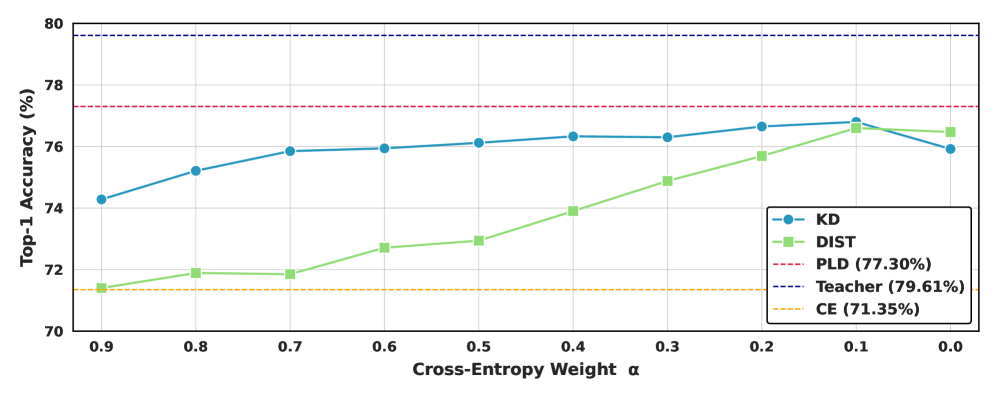
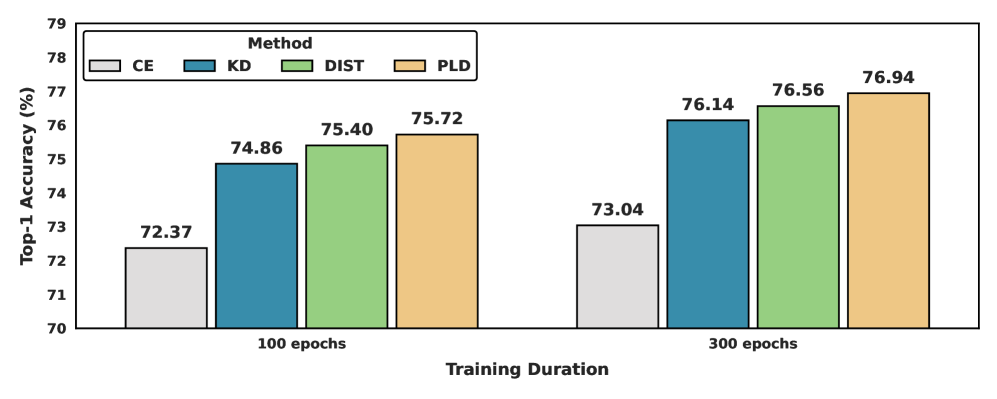

📊 实验亮点
PLD在CIFAR-100、ImageNet-1K和MS-COCO等数据集上进行了广泛的实验,结果表明,PLD在各种架构和蒸馏目标下均取得了显著的性能提升。例如,在ImageNet-1K上,PLD相对于基线方法,Top-1准确率提升了1-2个百分点。此外,PLD在同构和异构的师生对中均表现出色,证明了其通用性和有效性。
🎯 应用场景
PLD方法可广泛应用于模型压缩领域,尤其适用于需要将大型模型部署到资源受限设备上的场景,如移动设备、嵌入式系统等。该方法能够有效提升小模型的性能,使其在精度上接近甚至超过大型模型,从而降低计算成本和存储需求。此外,PLD还可以应用于迁移学习和领域自适应等任务,提升模型在新领域的泛化能力。
📄 摘要(原文)
Knowledge distillation is a model compression technique in which a compact "student" network is trained to replicate the predictive behavior of a larger "teacher" network. In logit-based knowledge distillation, it has become the de facto approach to augment cross-entropy with a distillation term. Typically, this term is either a KL divergence that matches marginal probabilities or a correlation-based loss that captures intra- and inter-class relationships. In every case, it acts as an additional term to cross-entropy. This term has its own weight, which must be carefully tuned. In this paper, we adopt a choice-theoretic perspective and recast knowledge distillation under the Plackett-Luce model by interpreting teacher logits as "worth" scores. We introduce "Plackett-Luce Distillation (PLD)", a weighted list-wise ranking loss. In PLD, the teacher model transfers knowledge of its full ranking of classes, weighting each ranked choice by its own confidence. PLD directly optimizes a single "teacher-optimal" ranking. The true label is placed first, followed by the remaining classes in descending teacher confidence. This process yields a convex and translation-invariant surrogate that subsumes weighted cross-entropy. Empirically, across CIFAR-100, ImageNet-1K, and MS-COCO, PLD achieves consistent gains across diverse architectures and distillation objectives, including divergence-based, correlation-based, and feature-based methods, in both homogeneous and heterogeneous teacher-student pairs.