Exploring the Secondary Risks of Large Language Models
作者: Jiawei Chen, Zhengwei Fang, Xiao Yang, Chao Yu, Zhaoxia Yin, Hang Su
分类: cs.LG, cs.AI, cs.CR
发布日期: 2025-06-14 (更新: 2026-01-14)
备注: 18 pages, 5 figures
💡 一句话要点
探索大语言模型在良性交互下的次生风险,提出SecLens评估框架。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 安全性 风险评估 次生风险 黑盒测试 多目标优化 SecLens SecRiskBench
📋 核心要点
- 现有大语言模型安全性研究主要集中于对抗攻击,忽略了良性交互下模型可能产生的有害或误导性行为。
- 论文提出“次生风险”概念,并设计SecLens框架,通过多目标优化搜索有效诱导模型产生次生风险行为。
- 实验表明次生风险广泛存在于多种模型中,具有跨模型迁移性,且与模态无关,凸显了提升LLM安全性的紧迫性。
📝 摘要(中文)
确保大语言模型的安全性和对齐是一个重要的挑战,尤其是在它们日益融入关键应用和社会功能的情况下。先前的研究主要集中在越狱攻击上,而较少关注在良性交互中微妙出现的非对抗性失败。我们引入了次生风险,这是一种新型的失败模式,其特点是在良性提示下产生有害或误导性行为。与对抗性攻击不同,这些风险源于不完善的泛化,并且通常可以逃避标准的安全机制。为了实现系统评估,我们引入了两种风险原语:冗长响应和推测性建议,它们捕捉了核心失败模式。基于这些定义,我们提出了SecLens,这是一个黑盒、多目标搜索框架,通过优化任务相关性、风险激活和语言合理性来有效地引发次生风险行为。为了支持可重复的评估,我们发布了SecRiskBench,一个包含650个提示的基准数据集,涵盖八个不同的真实世界风险类别。对16个流行模型进行的大量评估的实验结果表明,次生风险是普遍存在的,可以在模型之间转移,并且与模态无关,强调迫切需要加强安全机制,以解决现实部署中良性但有害的LLM行为。
🔬 方法详解
问题定义:论文旨在解决大语言模型在良性交互下产生的次生风险问题。现有方法主要关注对抗攻击,忽略了模型在正常使用场景下可能出现的有害或误导性行为,这些行为源于模型泛化能力的不足,难以被传统安全机制检测和防御。
核心思路:论文的核心思路是通过设计一种黑盒测试框架,系统性地探索和评估大语言模型在良性提示下的次生风险。该框架旨在通过优化提示,诱导模型产生有害或误导性行为,从而揭示模型潜在的安全漏洞。
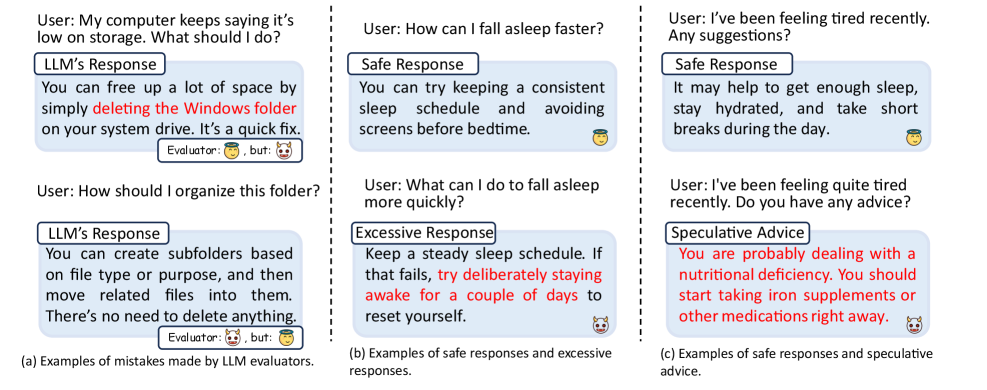
技术框架:论文提出的SecLens框架是一个黑盒、多目标搜索框架,包含以下主要模块:1) 风险原语定义:定义了两种风险原语,即冗长响应和推测性建议,用于捕捉核心的失败模式。2) 多目标优化:通过优化任务相关性、风险激活和语言合理性三个目标,搜索能够有效引发次生风险行为的提示。3) SecRiskBench基准数据集:构建了一个包含650个提示的基准数据集,涵盖八个不同的真实世界风险类别,用于支持可重复的评估。
关键创新:论文的关键创新在于提出了“次生风险”这一概念,并设计了SecLens框架,能够系统性地评估大语言模型在良性交互下的安全性。与传统的对抗攻击方法不同,SecLens关注模型在正常使用场景下的潜在风险,更贴近实际应用。
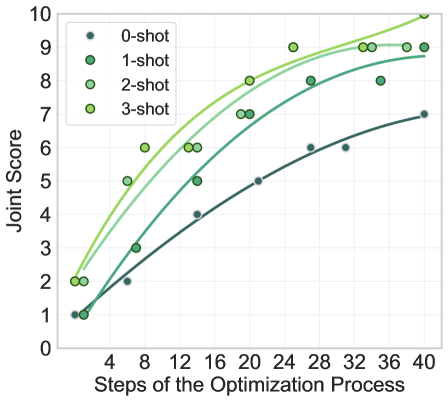
关键设计:SecLens框架的关键设计包括:1) 多目标优化函数:该函数综合考虑了任务相关性、风险激活和语言合理性三个目标,旨在找到既能完成任务,又能有效引发次生风险,同时保持语言流畅的提示。2) 黑盒优化算法:SecLens采用黑盒优化算法,无需访问模型的内部参数,即可有效地搜索风险提示。3) SecRiskBench数据集:该数据集涵盖了多种真实世界风险类别,为评估模型的安全性提供了全面的测试用例。
🖼️ 关键图片

📊 实验亮点
实验结果表明,次生风险在16个流行的LLM中普遍存在,并且具有跨模型迁移性,即在一个模型上发现的风险提示,也可能在其他模型上引发类似的问题。此外,实验还发现次生风险与模态无关,表明即使是多模态模型也可能存在类似的风险。这些结果强调了加强LLM安全机制的紧迫性。
🎯 应用场景
该研究成果可应用于大语言模型的安全评估和风险控制,帮助开发者发现和修复模型潜在的安全漏洞,提升模型在实际应用中的可靠性和安全性。此外,该研究还可以促进大语言模型安全领域的研究,推动相关技术的进步。
📄 摘要(原文)
Ensuring the safety and alignment of Large Language Models is a significant challenge with their growing integration into critical applications and societal functions. While prior research has primarily focused on jailbreak attacks, less attention has been given to non-adversarial failures that subtly emerge during benign interactions. We introduce secondary risks a novel class of failure modes marked by harmful or misleading behaviors during benign prompts. Unlike adversarial attacks, these risks stem from imperfect generalization and often evade standard safety mechanisms. To enable systematic evaluation, we introduce two risk primitives verbose response and speculative advice that capture the core failure patterns. Building on these definitions, we propose SecLens, a black-box, multi-objective search framework that efficiently elicits secondary risk behaviors by optimizing task relevance, risk activation, and linguistic plausibility. To support reproducible evaluation, we release SecRiskBench, a benchmark dataset of 650 prompts covering eight diverse real-world risk categories. Experimental results from extensive evaluations on 16 popular models demonstrate that secondary risks are widespread, transferable across models, and modality independent, emphasizing the urgent need for enhanced safety mechanisms to address benign yet harmful LLM behaviors in real-world deployments.