QiMeng-Attention: SOTA Attention Operator is generated by SOTA Attention Algorithm
作者: Qirui Zhou, Shaohui Peng, Weiqiang Xiong, Haixin Chen, Yuanbo Wen, Haochen Li, Ling Li, Qi Guo, Yongwei Zhao, Ke Gao, Ruizhi Chen, Yanjun Wu, Chen Zhao, Yunji Chen
分类: cs.LG, cs.CL
发布日期: 2025-06-14
💡 一句话要点
提出QiMeng-Attention,通过LLM自动生成高性能Attention算子,解决长文本场景下的性能瓶颈。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Attention机制 大型语言模型 代码生成 GPU加速 自动优化 LLM-TL 长文本处理 高性能计算
📋 核心要点
- 现有Attention算子在长文本处理中面临性能瓶颈,FlashAttention虽有效但依赖人工实现,缺乏跨GPU架构的适应性。
- 提出LLM友好的思维语言(LLM-TL)和两阶段推理流程,解耦优化逻辑和底层实现,提升LLM对Attention算子的理解。
- 实验表明,该方法在多种GPU上显著优于原始LLM和人工优化库,实现高达35.16倍的加速,并缩短开发时间。
📝 摘要(中文)
Attention算子是大型语言模型(LLM)中的关键性能瓶颈,尤其是在长文本场景下。FlashAttention是目前最广泛使用且有效的GPU加速算法,但需要耗时且依赖硬件的手动实现,限制了其在不同GPU架构上的适应性。现有的LLM在代码生成任务中表现出潜力,但难以生成高性能的attention代码,关键在于它们无法理解attention算子的复杂数据流和计算过程,并利用底层原语来挖掘GPU性能。为了解决上述挑战,我们提出了一种LLM友好的思维语言(LLM-TL),以帮助LLM解耦高层优化逻辑和GPU上的底层实现,并增强LLM对attention算子的理解。通过一个两阶段的推理工作流程,即TL代码生成和翻译,LLM可以自动生成在各种GPU上的FlashAttention实现,从而为以attention为中心的算法建立一个自优化范式,以生成高性能的attention算子。在A100、RTX8000和T4 GPU上验证,我们的方法显著优于原始LLM,实现了高达35.16倍的加速。此外,我们的方法不仅在大多数场景中超越了人工优化的库(cuDNN和官方库),还将支持扩展到不支持的硬件和数据类型,与人工专家相比,将开发时间从数月缩短到数分钟。
🔬 方法详解
问题定义:论文旨在解决大型语言模型中Attention算子在长文本场景下的性能瓶颈问题。现有方法,特别是FlashAttention,虽然性能优秀,但需要人工针对特定GPU架构进行优化和实现,开发周期长,难以快速适配新的硬件平台和数据类型。这限制了Attention机制的广泛应用和发展。
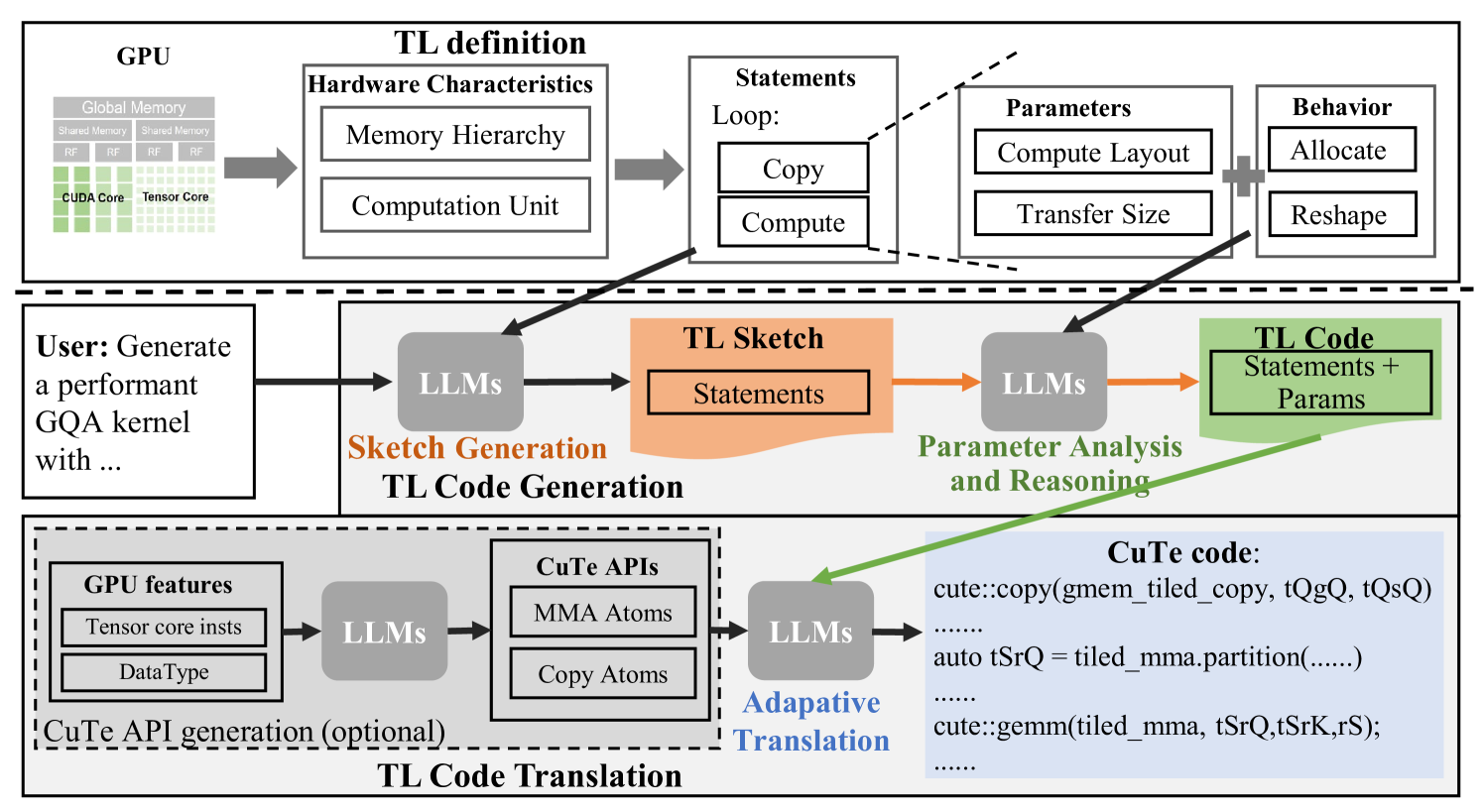
核心思路:论文的核心思路是利用大型语言模型(LLM)的代码生成能力,通过设计一种LLM友好的思维语言(LLM-TL),让LLM能够理解Attention算子的优化逻辑和底层实现细节,从而自动生成高性能的Attention算子代码。这种方法将人工优化过程自动化,降低了开发成本,并提高了Attention算子的可移植性和可扩展性。
技术框架:该方法采用一个两阶段的推理工作流程:首先,LLM根据LLM-TL生成Attention算子的优化代码;然后,将生成的代码翻译成可在特定GPU上执行的底层代码。整个框架包括LLM-TL的设计、代码生成模块和代码翻译模块。LLM-TL作为LLM理解和生成Attention算子代码的桥梁,起到了关键作用。
关键创新:该方法最重要的技术创新点在于LLM-TL的设计和两阶段推理流程。LLM-TL允许LLM在高层次上理解和优化Attention算子,而无需直接处理底层的硬件细节。两阶段推理流程将优化逻辑和底层实现解耦,使得LLM可以专注于优化算法本身,而将底层实现交给代码翻译模块。
关键设计:LLM-TL的具体设计细节未知,但可以推测其包含描述Attention算子数据流、计算过程和优化策略的语法和语义。代码生成模块可能采用prompt engineering等技术,引导LLM生成高质量的代码。代码翻译模块可能依赖于编译器技术,将LLM生成的代码转换成特定GPU架构上的可执行代码。具体的损失函数和网络结构未知,但可能涉及到代码质量评估和优化反馈机制。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在A100、RTX8000和T4 GPU上显著优于原始LLM,实现了高达35.16倍的加速。此外,该方法在大多数场景中超越了人工优化的库(cuDNN和官方库),并将支持扩展到不支持的硬件和数据类型,与人工专家相比,将开发时间从数月缩短到数分钟。这些结果表明该方法具有很强的实用价值和竞争力。
🎯 应用场景
该研究成果可广泛应用于各种需要高性能Attention机制的场景,如大型语言模型、机器翻译、图像识别等。通过自动生成高性能Attention算子,可以显著提升这些应用的性能和效率,降低开发成本,并加速新硬件平台的适配。未来,该方法有望推广到其他计算密集型算子的自动优化,推动人工智能技术的快速发展。
📄 摘要(原文)
The attention operator remains a critical performance bottleneck in large language models (LLMs), particularly for long-context scenarios. While FlashAttention is the most widely used and effective GPU-aware acceleration algorithm, it must require time-consuming and hardware-specific manual implementation, limiting adaptability across GPU architectures. Existing LLMs have shown a lot of promise in code generation tasks, but struggle to generate high-performance attention code. The key challenge is it cannot comprehend the complex data flow and computation process of the attention operator and utilize low-level primitive to exploit GPU performance. To address the above challenge, we propose an LLM-friendly Thinking Language (LLM-TL) to help LLMs decouple the generation of high-level optimization logic and low-level implementation on GPU, and enhance LLMs' understanding of attention operator. Along with a 2-stage reasoning workflow, TL-Code generation and translation, the LLMs can automatically generate FlashAttention implementation on diverse GPUs, establishing a self-optimizing paradigm for generating high-performance attention operators in attention-centric algorithms. Verified on A100, RTX8000, and T4 GPUs, the performance of our methods significantly outshines that of vanilla LLMs, achieving a speed-up of up to 35.16x. Besides, our method not only surpasses human-optimized libraries (cuDNN and official library) in most scenarios but also extends support to unsupported hardware and data types, reducing development time from months to minutes compared with human experts.