MarginSel : Max-Margin Demonstration Selection for LLMs
作者: Rajeev Bhatt Ambati, James Lester, Shashank Srivastava, Snigdha Chaturvedi
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-06-07
💡 一句话要点
MarginSel:面向大语言模型的最大间隔示范选择方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 上下文学习 少样本学习 示范选择 最大间隔 文本分类
📋 核心要点
- 上下文学习(ICL)依赖高质量的示范示例,但如何为每个测试实例选择最佳示例仍然是一个挑战。
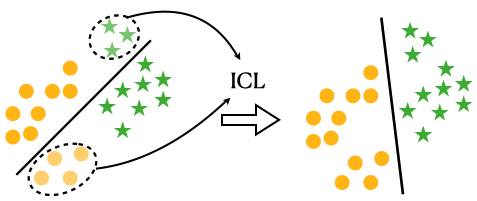
- MarginSel通过选择“困难”的示范示例,使LLM学习到更鲁棒的决策边界,类似于支持向量机的最大间隔思想。
- 实验表明,MarginSel在多个分类任务上显著优于随机选择策略,F1分数提升高达7%。
📝 摘要(中文)
大语言模型(LLMs)通过上下文学习(ICL)在少样本学习方面表现出色。然而,ICL的有效性通常对示范示例的选择和排序非常敏感。为了解决这个问题,我们提出了MarginSel:面向LLMs的最大间隔示范选择方法,这是一种两步法,它为ICL提示选择困难的示范示例,并适应每个测试实例。与随机选择示例相比,我们的方法在分类任务中实现了2-7%的F1分数绝对提升。我们还提供了理论见解和经验证据,表明MarginSel通过有效地增加困难示例的间隔,类似于支持向量,从而在LLMs中诱导最大间隔行为,从而在有利的方向上移动决策边界。
🔬 方法详解
问题定义:论文旨在解决大语言模型上下文学习(ICL)中,示范示例选择对模型性能影响大的问题。现有方法,如随机选择,无法保证选择的示例对模型学习有益,导致性能不稳定。选择不当的示例会误导模型,降低泛化能力。
核心思路:论文借鉴支持向量机(SVM)的最大间隔思想,认为选择“困难”的示例,即那些接近决策边界的示例,可以有效地扩大决策间隔,从而提高模型的鲁棒性和泛化能力。MarginSel旨在选择那些能够最大程度影响模型决策边界的示范示例。
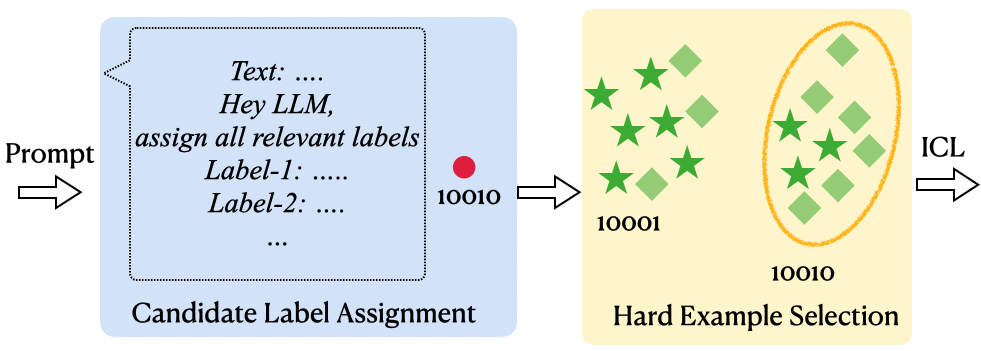
技术框架:MarginSel是一个两步方法:1) 候选集生成:首先,从所有可用的示范示例中,选择一部分作为候选集。这一步可以使用一些简单的启发式方法,例如选择与测试样本语义相似的示例。2) 最大间隔选择:然后,从候选集中选择最终的示范示例。这一步通过最大化模型在这些示例上的“间隔”来实现。具体来说,对于每个候选示例,计算其对模型决策边界的影响,选择那些能够最大程度扩大间隔的示例。
关键创新:MarginSel的关键创新在于将最大间隔学习的思想引入到大语言模型的上下文学习中。与传统的随机选择或基于相似度选择的方法不同,MarginSel关注的是示例对模型决策边界的影响,而不是示例本身的属性。这种方法能够更有效地选择对模型学习有益的示例。
关键设计:MarginSel的具体实现需要定义如何计算示例对模型决策边界的影响。论文中,作者使用模型预测概率的差异来衡量这种影响。具体来说,对于一个候选示例,计算模型在包含该示例和不包含该示例两种情况下的预测概率差异,差异越大,说明该示例对模型决策边界的影响越大。选择那些能够最大化平均预测概率差异的示例作为最终的示范示例。
🖼️ 关键图片
📊 实验亮点
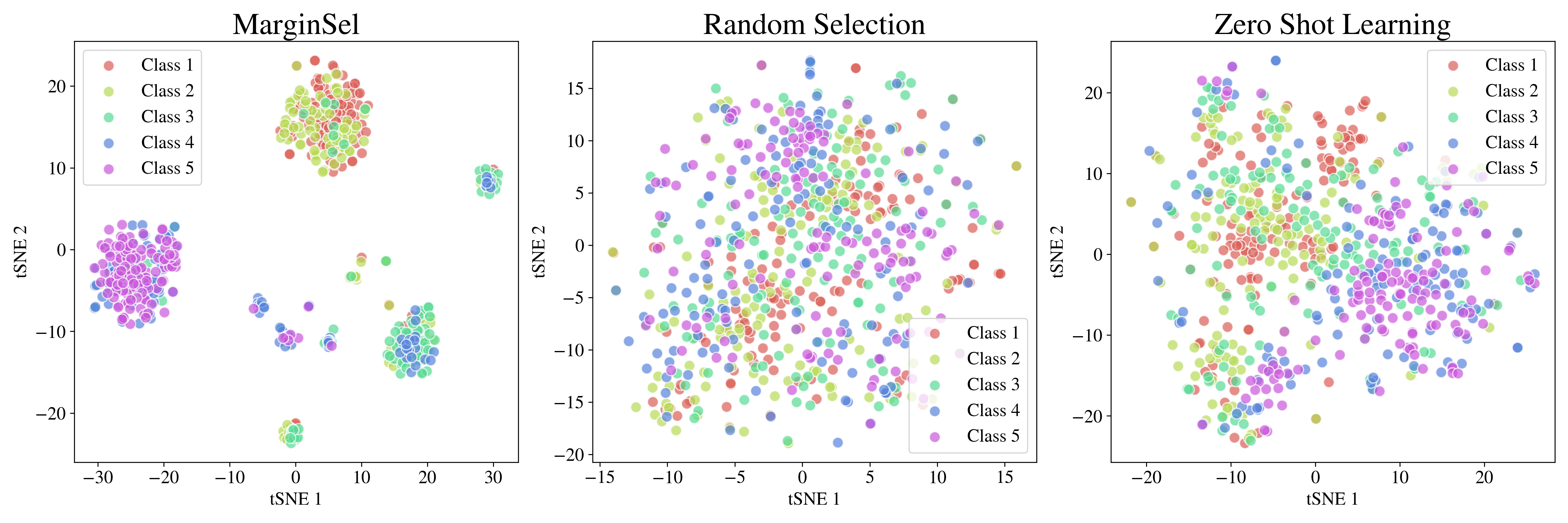
实验结果表明,MarginSel在多个文本分类任务上显著优于随机选择策略。例如,在某些任务上,MarginSel的F1分数比随机选择提高了2-7%。此外,实验还验证了MarginSel能够有效地扩大模型决策边界的间隔,从而提高模型的鲁棒性。
🎯 应用场景
MarginSel可应用于各种需要利用大语言模型进行少样本学习的场景,例如文本分类、情感分析、信息抽取等。通过更有效地选择示范示例,可以提高模型的准确性和鲁棒性,降低对大量标注数据的依赖,加速模型部署和应用。
📄 摘要(原文)
Large Language Models (LLMs) excel at few-shot learning via in-context learning (ICL). However, the effectiveness of ICL is often sensitive to the selection and ordering of demonstration examples. To address this, we present MarginSel: Max-Margin Demonstration Selection for LLMs, a two-step method that selects hard demonstration examples for the ICL prompt, adapting to each test instance. Our approach achieves 2-7% absolute improvement in F1-score across classification tasks, compared to a random selection of examples. We also provide theoretical insights and empirical evidence showing that MarginSel induces max-margin behavior in LLMs by effectively increasing the margin for hard examples, analogous to support vectors, thereby shifting the decision boundary in a beneficial direction.