Curriculum Reinforcement Learning from Easy to Hard Tasks Improves LLM Reasoning
作者: Shubham Parashar, Shurui Gui, Xiner Li, Hongyi Ling, Sushil Vemuri, Blake Olson, Eric Li, Yu Zhang, James Caverlee, Dileep Kalathil, Shuiwang Ji
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-06-07 (更新: 2025-11-02)
🔗 代码/项目: GITHUB
💡 一句话要点
提出E2H Reasoner,通过课程强化学习提升LLM的推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 课程学习 语言模型 推理能力 任务调度 策略迭代 有限样本复杂度 E2H Reasoner
📋 核心要点
- 现有强化学习方法在直接训练LLM解决复杂推理任务时效果不佳,面临训练困难和收敛缓慢的问题。
- E2H Reasoner通过课程学习的思想,设计从易到难的任务序列,引导LLM逐步掌握推理能力,避免过早接触困难任务。
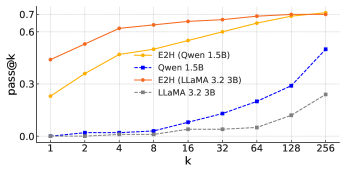
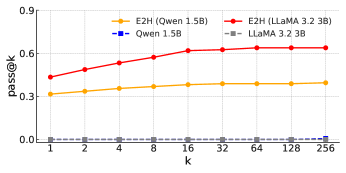
- 实验结果表明,E2H Reasoner能显著提升小型LLM在多个推理任务上的性能,优于直接使用强化学习训练的方法。
📝 摘要(中文)
本文旨在通过强化学习(RL)提升语言模型的推理能力。最近经过RL后训练的模型,如DeepSeek-R1,已展示出在数学和编码任务上的推理能力。然而,先前的研究表明,仅使用RL来提高在本质上困难的任务上的推理能力效果较差。受课程学习的启发,我们提出了一种将任务从易到难(E2H)进行安排的方法,使LLM能够逐步构建推理技能。我们的方法被称为E2H Reasoner。经验表明,虽然简单的任务最初很重要,但通过适当的调度逐渐减少它们对于防止过拟合至关重要。理论上,我们在近似策略迭代框架内建立了E2H Reasoner的收敛保证。我们推导了有限样本复杂度界限,并表明当任务被适当地分解和调节时,通过课程阶段进行学习比直接学习需要更少的总样本。跨多个领域的实验表明,E2H Reasoner显著提高了小型LLM(1.5B到3B)的推理能力,否则仅使用vanilla RL训练时会遇到困难,突出了我们方法的有效性。
🔬 方法详解
问题定义:论文旨在解决语言模型在复杂推理任务中,直接使用强化学习训练效果不佳的问题。现有方法难以有效探索策略空间,导致训练不稳定,收敛速度慢,最终性能提升有限。尤其对于小型LLM,这个问题更加突出。
核心思路:论文借鉴课程学习的思想,提出E2H Reasoner,核心在于设计一个从简单到困难的任务序列,让LLM逐步学习和掌握推理能力。通过先学习简单的任务,LLM可以更容易地探索策略空间,获得初步的推理能力,然后逐步过渡到更复杂的任务,从而提高训练效率和最终性能。
技术框架:E2H Reasoner的整体框架包含以下几个主要阶段:1) 任务难度排序:根据任务的复杂度对任务进行排序,构建从易到难的任务序列。2) 课程调度:设计一个课程调度策略,控制不同难度任务的采样频率,逐渐减少简单任务的采样,增加困难任务的采样。3) 强化学习训练:使用强化学习算法(如PPO)训练LLM,根据课程调度策略采样任务,并根据任务的奖励信号更新LLM的策略。
关键创新:E2H Reasoner的关键创新在于将课程学习的思想引入到LLM的强化学习训练中,通过设计从易到难的任务序列和课程调度策略,引导LLM逐步学习推理能力。与直接使用强化学习训练相比,E2H Reasoner能够更有效地探索策略空间,提高训练效率和最终性能。此外,论文还提供了E2H Reasoner的收敛性证明和有限样本复杂度分析。
关键设计:课程调度策略是E2H Reasoner的关键设计之一。论文中具体使用的课程调度策略未知,但强调了逐渐减少简单任务的采样,增加困难任务的采样,以防止过拟合简单任务。此外,任务的难度排序也至关重要,需要根据任务的特性进行合理的设计。奖励函数的设计也需要仔细考虑,以确保能够有效地引导LLM学习推理能力。
🖼️ 关键图片

📊 实验亮点
实验结果表明,E2H Reasoner能够显著提升小型LLM(1.5B到3B)的推理能力。在多个推理任务上,E2H Reasoner优于直接使用强化学习训练的方法。具体性能数据和提升幅度在论文中给出,但此处未提供。
🎯 应用场景
E2H Reasoner可应用于各种需要复杂推理能力的场景,例如数学问题求解、代码生成、知识图谱推理等。该方法能够提升小型LLM的推理能力,使其在资源受限的环境中也能发挥重要作用。未来,E2H Reasoner有望成为提升LLM推理能力的一种通用方法,推动LLM在更多领域的应用。
📄 摘要(原文)
We aim to improve the reasoning capabilities of language models via reinforcement learning (RL). Recent RL post-trained models like DeepSeek-R1 have demonstrated reasoning abilities on mathematical and coding tasks. However, prior studies suggest that using RL alone to improve reasoning on inherently difficult tasks is less effective. Here, we draw inspiration from curriculum learning and propose to schedule tasks from easy to hard (E2H), allowing LLMs to build reasoning skills gradually. Our method is termed E2H Reasoner. Empirically, we observe that, although easy tasks are important initially, fading them out through appropriate scheduling is essential in preventing overfitting. Theoretically, we establish convergence guarantees for E2H Reasoner within an approximate policy iteration framework. We derive finite-sample complexity bounds and show that when tasks are appropriately decomposed and conditioned, learning through curriculum stages requires fewer total samples than direct learning. Experiments across multiple domains show that E2H Reasoner significantly improves the reasoning ability of small LLMs (1.5B to 3B), which otherwise struggle when trained with vanilla RL alone, highlighting the effectiveness of our method. Our code can be found on https://github.com/divelab/E2H-Reasoning.