Closing the Gap between TD Learning and Supervised Learning with $Q$-Conditioned Maximization
作者: Xing Lei, Zifeng Zhuang, Shentao Yang, Sheng Xu, Yunhao Luo, Fei Shen, Wenyan Yang, Xuetao Zhang, Donglin Wang
分类: cs.LG
发布日期: 2025-06-01 (更新: 2025-09-11)
💡 一句话要点
提出GCReinSL,通过Q值条件最大化弥合TD学习与监督学习在离线强化学习中的差距
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 监督学习 Q值条件最大化 轨迹拼接 归一化流
📋 核心要点
- 监督学习在离线强化学习中表现出优势,但缺乏时序差分学习的轨迹拼接能力。
- 论文提出GCReinSL,通过Q值条件策略和Q值条件最大化,赋予监督学习轨迹拼接能力。
- 实验结果表明,GCReinSL在离线强化学习数据集上优于现有的监督学习方法,尤其是在轨迹拼接方面。
📝 摘要(中文)
最近,监督学习(SL)方法因其简单性、稳定性和高效性,已成为离线强化学习(RL)的一种有效方法。然而,最近的研究表明,SL方法缺乏通常与基于时序差分(TD)的方法相关的轨迹拼接能力。由此产生一个自然的问题:我们如何赋予SL方法拼接能力,并缩小其与TD学习的性能差距?为了回答这个问题,我们引入了Q值条件最大化监督学习,用于离线目标条件强化学习,它通过Q值条件策略和Q值条件最大化来增强SL的拼接能力。具体来说,我们提出了目标条件强化监督学习(GCReinSL),它包括(1)通过离线数据集使用归一化流估计Q函数,以及(2)通过将Q函数最大化与期望回归相结合,在数据支持范围内找到最大Q值。在推理时,我们的策略基于这样的最大Q值选择最优动作。来自离线RL数据集上的拼接评估的实验结果表明,我们的方法优于先前具有拼接能力和目标数据增强技术的SL方法。
🔬 方法详解
问题定义:离线强化学习旨在利用静态数据集训练策略,而无需与环境交互。监督学习方法虽然简单高效,但缺乏时序差分学习的轨迹拼接能力,导致策略无法有效利用数据集中蕴含的长期依赖关系。现有方法难以在保证策略稳定性的同时,实现有效的轨迹拼接。
核心思路:论文的核心思路是通过Q值来引导监督学习,使其具备轨迹拼接能力。具体来说,通过Q值条件策略和Q值条件最大化,使得策略能够选择在给定状态下,能够达到更高Q值的动作,从而实现更好的长期回报。
技术框架:GCReinSL包含两个主要阶段:1) Q函数估计阶段:使用归一化流(Normalizing Flows)从离线数据集中学习Q函数。归一化流能够提供灵活且准确的Q函数估计。2) 策略学习阶段:通过将Q函数最大化与期望回归相结合,在数据集支持范围内找到最大Q值。策略根据最大Q值选择最优动作。
关键创新:GCReinSL的关键创新在于将Q函数引入到监督学习框架中,通过Q值条件最大化来增强策略的轨迹拼接能力。与传统的监督学习方法不同,GCReinSL不仅仅是模仿数据集中的行为,而是学习如何选择能够获得更高回报的动作序列。
关键设计:Q函数使用归一化流进行建模,能够捕捉复杂的状态-动作空间中的Q值分布。策略学习阶段,通过期望回归来约束策略的学习,避免策略偏离数据集太远。Q值最大化过程与期望回归相结合,保证了策略的探索能力和稳定性。具体参数设置和网络结构在论文中有详细描述,此处未知。
🖼️ 关键图片
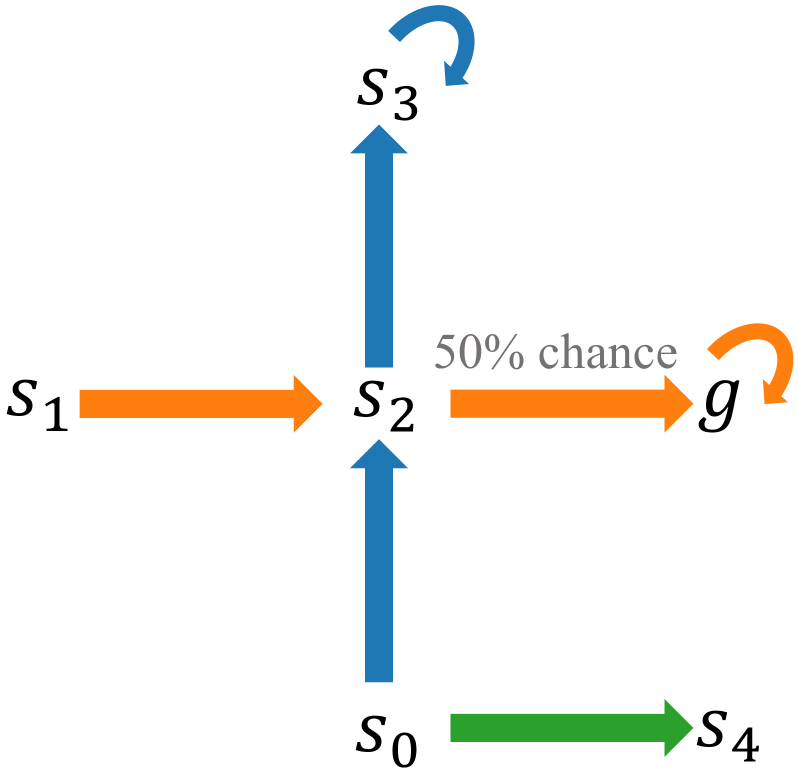


📊 实验亮点
实验结果表明,GCReinSL在离线强化学习数据集上取得了显著的性能提升,尤其是在轨迹拼接方面。与现有的监督学习方法和目标数据增强技术相比,GCReinSL能够更有效地利用离线数据,学习到更优的策略。具体的性能数据和提升幅度在论文中有详细展示,此处未知。
🎯 应用场景
该研究成果可应用于各种离线强化学习场景,例如机器人控制、自动驾驶、推荐系统和医疗决策等。通过利用离线数据学习策略,可以降低试错成本,提高学习效率。该方法尤其适用于那些难以进行在线交互或试错成本较高的场景,具有重要的实际应用价值和潜力。
📄 摘要(原文)
Recently, supervised learning (SL) methodology has emerged as an effective approach for offline reinforcement learning (RL) due to their simplicity, stability, and efficiency. However, recent studies show that SL methods lack the trajectory stitching capability, typically associated with temporal difference (TD)-based approaches. A question naturally surfaces: \textit{How can we endow SL methods with stitching capability and close its performance gap with TD learning?} To answer this question, we introduce $Q$-conditioned maximization supervised learning for offline goal-conditioned RL, which enhances SL with the stitching capability through $Q$-conditioned policy and $Q$-conditioned maximization. Concretely, we propose \textbf{G}oal-\textbf{C}onditioned \textbf{\textit{Rein}}forced \textbf{S}upervised \textbf{L}earning (\textbf{GC\textit{Rein}SL}), which consists of (1) estimating the $Q$-function by Normalizing Flows from the offline dataset and (2) finding the maximum $Q$-value within the data support by integrating $Q$-function maximization with Expectile Regression. In inference time, our policy chooses optimal actions based on such a maximum $Q$-value. Experimental results from stitching evaluations on offline RL datasets demonstrate that our method outperforms prior SL approaches with stitching capabilities and goal data augmentation techniques.