A Brain Graph Foundation Model: Pre-Training and Prompt-Tuning for Any Atlas and Disorder
作者: Xinxu Wei, Kanhao Zhao, Yong Jiao, Lifang He, Yu Zhang
分类: q-bio.NC, cs.LG
发布日期: 2025-05-31 (更新: 2025-08-03)
备注: 30pages
🔗 代码/项目: GITHUB
💡 一句话要点
提出BrainGFM:基于图的脑图谱基础模型,用于多种脑疾病诊断与脑区划分。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 脑图谱 基础模型 图神经网络 对比学习 自编码器 fMRI 神经影像 迁移学习
📋 核心要点
- 现有脑基础模型主要依赖时间序列或连接组特征,缺乏对异构脑图谱数据的有效整合与泛化能力。
- BrainGFM通过图对比学习和图掩码自编码器进行预训练,并结合图提示和语言提示,实现跨图谱和疾病的泛化。
- BrainGFM在包含25种疾病的27个数据集上预训练,显著提升了模型在少样本和零样本学习条件下的性能。
📝 摘要(中文)
随着大型语言模型(LLMs)不断革新人工智能研究,构建大规模脑基础模型以推进神经科学发展日益受到关注。现有脑基础模型主要基于时间序列信号或连接组特征进行预训练,本文提出一种新颖的基于图的预训练范式,用于构建脑图基础模型。我们介绍了Brain Graph Foundation Model,简称BrainGFM,这是一个统一的框架,利用图对比学习和图掩码自编码器进行大规模基于fMRI的预训练。BrainGFM在具有不同分割方式的多种脑图谱的混合数据上进行预训练,显著扩展了预训练语料库,并增强了模型在异构fMRI脑表示上的泛化能力。为了支持高效且通用的下游迁移,我们将图提示和语言提示集成到模型设计中,使BrainGFM能够灵活地适应各种图谱、神经和精神疾病以及任务设置。此外,我们采用元学习来优化图提示,通过语言引导提示,促进对先前未见过的疾病在少样本和零样本学习条件下的强大泛化能力。BrainGFM在涵盖25种常见神经和精神疾病的27个神经影像数据集上进行预训练,包括2种脑图谱类型(功能性和解剖性),跨越8种广泛使用的分割方式,覆盖超过25,000名受试者、60,000次fMRI扫描,以及总共400,000个图样本。
🔬 方法详解
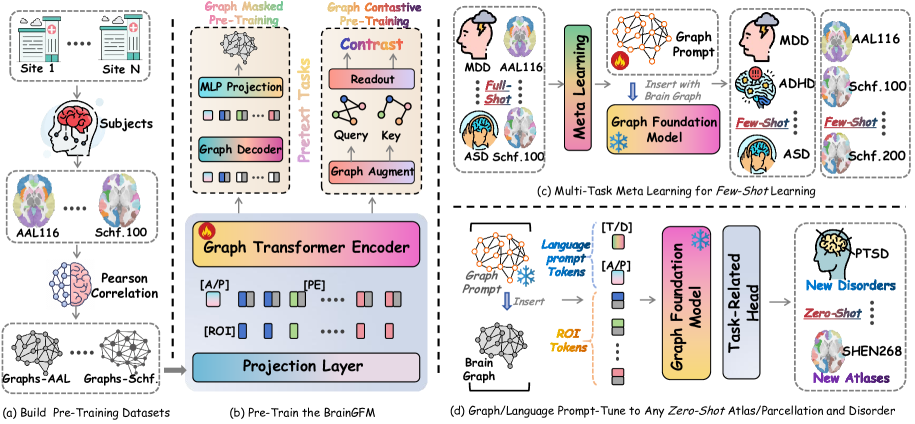
问题定义:现有脑基础模型在处理来自不同脑图谱(atlas)和不同脑区划分(parcellation)的数据时,泛化能力不足。它们通常针对特定类型的脑活动数据(如时间序列或连接组)进行训练,难以适应异构的fMRI数据,限制了其在多种神经和精神疾病诊断中的应用。
核心思路:BrainGFM的核心思路是利用图神经网络(GNN)对fMRI数据进行建模,并通过图对比学习和图掩码自编码器进行预训练,从而学习到通用的脑图谱表示。通过结合图提示和语言提示,模型能够灵活地适应不同的脑图谱、疾病和任务设置,实现跨领域的知识迁移。
技术框架:BrainGFM的整体框架包括以下几个主要模块:1) 图构建模块:将fMRI数据转换为脑图,其中节点代表脑区,边代表脑区之间的功能连接。2) 图对比学习模块:通过对比不同脑图之间的相似性,学习脑图的通用表示。3) 图掩码自编码器模块:通过掩码部分脑图节点,并预测被掩码的节点特征,学习脑图的结构信息。4) 图提示和语言提示模块:通过图提示和语言提示,引导模型适应不同的下游任务。
关键创新:BrainGFM的关键创新在于:1) 提出了一种基于图的脑基础模型预训练范式,能够有效处理异构的fMRI数据。2) 结合了图对比学习和图掩码自编码器,学习到更鲁棒和通用的脑图谱表示。3) 引入了图提示和语言提示,实现了跨图谱、疾病和任务的灵活迁移。
关键设计:BrainGFM的关键设计包括:1) 使用GCN或GAT等图神经网络作为图编码器。2) 设计合适的图对比学习损失函数,例如InfoNCE loss。3) 设计图掩码策略,例如随机掩码或基于节点重要性的掩码。4) 使用元学习优化图提示,提高模型在少样本和零样本学习条件下的泛化能力。
🖼️ 关键图片
📊 实验亮点
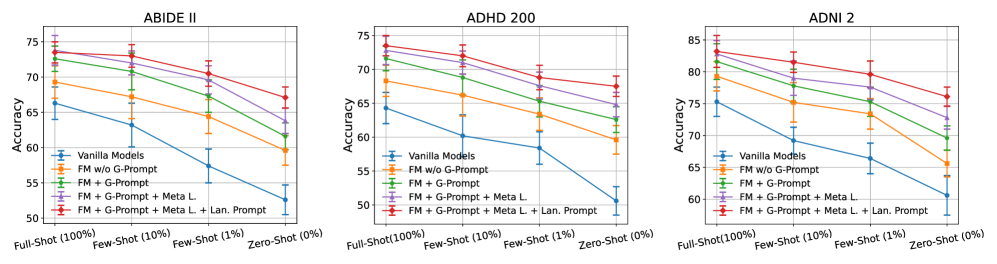
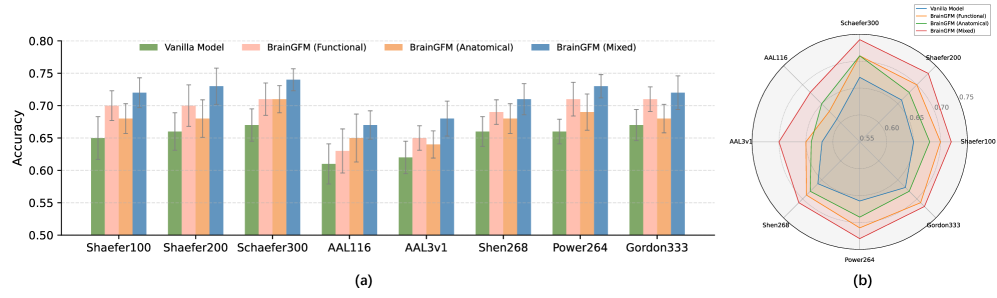
BrainGFM在27个神经影像数据集上进行了预训练,涵盖25种常见神经和精神疾病。实验结果表明,BrainGFM在少样本和零样本学习条件下,对先前未见过的疾病表现出强大的泛化能力。相较于传统方法,BrainGFM在多种脑疾病诊断任务中取得了显著的性能提升。
🎯 应用场景
BrainGFM可应用于多种神经和精神疾病的诊断、预后预测和治疗方案制定。通过对不同脑图谱和脑区划分数据的整合分析,有助于深入理解大脑功能和疾病机制。该模型还可用于开发个性化的脑疾病诊断和治疗方案,提升临床决策的准确性和效率。
📄 摘要(原文)
As large language models (LLMs) continue to revolutionize AI research, there is a growing interest in building large-scale brain foundation models to advance neuroscience. While most existing brain foundation models are pre-trained on time-series signals or connectome features, we propose a novel graph-based pre-training paradigm for constructing a brain graph foundation model. In this paper, we introduce the Brain Graph Foundation Model, termed BrainGFM, a unified framework that leverages graph contrastive learning and graph masked autoencoders for large-scale fMRI-based pre-training. BrainGFM is pre-trained on a diverse mixture of brain atlases with varying parcellations, significantly expanding the pre-training corpus and enhancing the model's ability to generalize across heterogeneous fMRI-derived brain representations. To support efficient and versatile downstream transfer, we integrate both graph prompts and language prompts into the model design, enabling BrainGFM to flexibly adapt to a wide range of atlases, neurological and psychiatric disorders, and task settings. Furthermore, we employ meta-learning to optimize the graph prompts, facilitating strong generalization to previously unseen disorders under both few-shot and zero-shot learning conditions via language-guided prompting. BrainGFM is pre-trained on 27 neuroimaging datasets spanning 25 common neurological and psychiatric disorders, encompassing 2 types of brain atlases (functional and anatomical) across 8 widely-used parcellations, and covering over 25,000 subjects, 60,000 fMRI scans, and a total of 400,000 graph samples aggregated across all atlases and parcellations. The code is available at: https://github.com/weixinxu666/BrainGFM