Adaptive Plane Reformatting for 4D Flow MRI using Deep Reinforcement Learning
作者: Javier Bisbal, Julio Sotelo, Maria I Valdés, Pablo Irarrazaval, Marcelo E Andia, Julio García, José Rodriguez-Palomarez, Francesca Raimondi, Cristián Tejos, Sergio Uribe
分类: cs.LG, cs.CV
发布日期: 2025-05-31 (更新: 2025-12-01)
💡 一句话要点
提出AdaPR,一种基于深度强化学习的自适应平面重构方法,用于解决4D流MRI的通用性问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 四维流MRI 深度强化学习 平面重构 自适应学习 医学影像 局部坐标系 A3C算法
📋 核心要点
- 现有DRL方法在4D流MRI平面重构中缺乏跨设备和机构的泛化能力,因为它们依赖于全局坐标系。
- AdaPR采用局部坐标系,使智能体能够在任意位置和方向的体积数据中进行导航,从而实现自适应的平面重构。
- 实验结果表明,AdaPR在多个供应商的4D流MRI数据集上表现出色,其流量测量结果与专家观察者相当。
📝 摘要(中文)
背景与目的:四维相位对比MRI(4D flow MRI)的平面重构耗时且易受观察者间差异影响,限制了快速心血管血流评估。深度强化学习(DRL)训练智能体迭代调整平面位置和方向,实现精确的平面重构,无需详细的地标,适用于对比度和分辨率有限的图像,如4D flow MRI。然而,当前的DRL方法假设测试数据与训练数据具有相同的空间对齐方式,限制了跨扫描仪和机构的泛化能力。为了解决这个限制,我们引入了AdaPR(自适应平面重构),一个DRL框架,它使用局部坐标系来导航具有任意位置和方向的数据。
🔬 方法详解
问题定义:四维流MRI(4D flow MRI)的平面重构旨在确定最佳的平面位置和方向,以便准确测量血管内的血流。传统方法耗时且依赖人工操作,容易产生观察者间的差异。现有的基于深度强化学习(DRL)的方法虽然可以自动化这一过程,但通常依赖于全局坐标系,导致模型在训练数据和测试数据空间对齐方式不一致时性能下降,限制了其在不同扫描仪和机构间的泛化能力。
核心思路:AdaPR的核心思路是使用局部坐标系来表示智能体的状态和动作。通过将智能体置于一个与全局坐标系无关的局部环境中,AdaPR能够学习到与体积数据的绝对位置和方向无关的策略。这种方法使得智能体可以适应具有任意位置和方向的体积数据,从而提高了模型的泛化能力。
技术框架:AdaPR使用异步优势演员-评论家(A3C)算法作为其DRL框架。该框架包含以下主要模块:1) 状态表示:智能体观察到的局部环境信息,包括当前平面位置、方向和周围的图像特征。2) 动作空间:智能体可以执行的动作,例如平移和旋转平面。3) 奖励函数:用于指导智能体学习的信号,例如与目标平面的距离和角度误差。4) 策略网络:用于预测智能体在给定状态下应采取的动作。5) 价值网络:用于评估当前状态的价值。A3C算法通过异步更新策略网络和价值网络来优化智能体的策略。
关键创新:AdaPR最重要的技术创新在于使用局部坐标系进行平面重构。与现有方法依赖全局坐标系不同,AdaPR将智能体置于一个局部环境中,使其能够学习到与体积数据的绝对位置和方向无关的策略。这种方法显著提高了模型的泛化能力,使其能够适应具有任意位置和方向的体积数据。
关键设计:AdaPR的关键设计包括:1) 局部坐标系的定义:局部坐标系的原点位于当前平面的中心,坐标轴与平面的法向量和两个正交向量对齐。2) 状态表示:智能体的状态包括当前平面在局部坐标系中的位置和方向,以及从局部坐标系中提取的图像特征。3) 奖励函数:奖励函数的设计旨在引导智能体快速准确地找到目标平面。它包括与目标平面的距离和角度误差,以及一个用于鼓励智能体探索的探索奖励。4) 网络结构:策略网络和价值网络都采用卷积神经网络(CNN)结构,用于从图像特征中提取有用的信息。
🖼️ 关键图片

📊 实验亮点
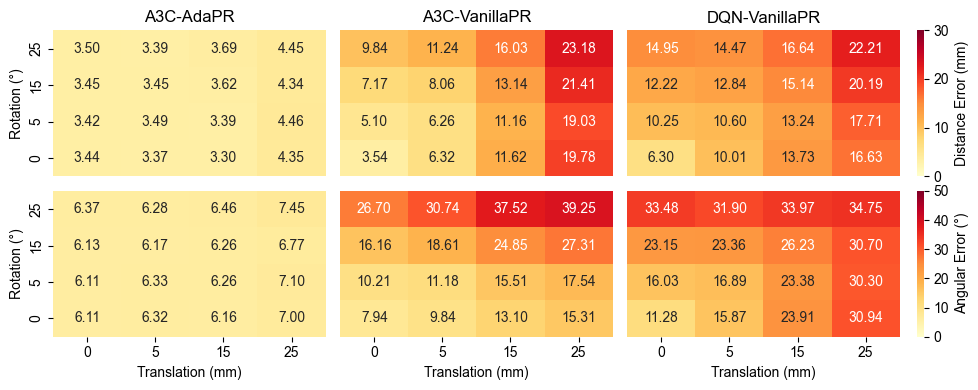
AdaPR在88个4D流MRI数据集上进行了验证,这些数据来自多个供应商,包括先天性心脏病患者。实验结果表明,AdaPR的平均角度误差为6.32 +/- 4.15度,距离误差为3.40 +/- 2.75毫米,优于基于全局坐标系的DRL方法和其他非DRL方法。AdaPR在不同体积方向和位置下保持了一致的准确性。AdaPR平面上的流量测量结果与两位手动观察者相比没有显著差异,具有极好的相关性(R^2 = 0.972和R^2 = 0.968),与观察者间的一致性相当(R^2 = 0.969)。
🎯 应用场景
AdaPR在医学影像领域具有广泛的应用前景,尤其是在需要精确平面重构的场景中。除了4D流MRI,它还可以应用于其他模态的医学影像,如CT、MRI等,用于血管、器官等结构的定位和测量。该技术能够减少人工干预,提高诊断效率,并有望在临床决策支持系统中发挥重要作用。未来,AdaPR可以进一步扩展到三维重建、图像配准等任务,为医学影像分析提供更强大的工具。
📄 摘要(原文)
Background and Objective: Plane reformatting for four-dimensional phase contrast MRI (4D flow MRI) is time-consuming and prone to inter-observer variability, which limits fast cardiovascular flow assessment. Deep reinforcement learning (DRL) trains agents to iteratively adjust plane position and orientation, enabling accurate plane reformatting without the need for detailed landmarks, making it suitable for images with limited contrast and resolution such as 4D flow MRI. However, current DRL methods assume that test volumes share the same spatial alignment as the training data, limiting generalization across scanners and institutions. To address this limitation, we introduce AdaPR (Adaptive Plane Reformatting), a DRL framework that uses a local coordinate system to navigate volumes with arbitrary positions and orientations. Methods: We implemented AdaPR using the Asynchronous Advantage Actor-Critic (A3C) algorithm and validated it on 88 4D flow MRI datasets acquired from multiple vendors, including patients with congenital heart disease. Results: AdaPR achieved a mean angular error of 6.32 +/- 4.15 degrees and a distance error of 3.40 +/- 2.75 mm, outperforming global-coordinate DRL methods and alternative non-DRL methods. AdaPR maintained consistent accuracy under different volume orientations and positions. Flow measurements from AdaPR planes showed no significant differences compared to two manual observers, with excellent correlation (R^2 = 0.972 and R^2 = 0.968), comparable to inter-observer agreement (R^2 = 0.969). Conclusion: AdaPR provides robust, orientation-independent plane reformatting for 4D flow MRI, achieving flow quantification comparable to expert observers. Its adaptability across datasets and scanners makes it a promising candidate for medical imaging applications beyond 4D flow MRI.