QoQ-Med: Building Multimodal Clinical Foundation Models with Domain-Aware GRPO Training
作者: Wei Dai, Peilin Chen, Chanakya Ekbote, Paul Pu Liang
分类: cs.LG, cs.AI, cs.CV
发布日期: 2025-05-31 (更新: 2025-10-22)
备注: Accepted as Oral at NeurIPS 2025. Revision after camera ready
🔗 代码/项目: GITHUB
💡 一句话要点
提出QoQ-Med以解决临床多模态数据推理问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态模型 临床决策 强化学习 领域感知 医学图像处理 时间序列分析 文本理解 模型训练
📋 核心要点
- 现有的多模态语言模型主要集中于视觉数据,难以有效处理异构临床数据,导致在不同专业中的推广性不足。
- 本文提出QoQ-Med模型,结合医学图像、时间序列信号和文本报告,通过领域感知相对策略优化(DRPO)进行训练,提升模型的推理能力。
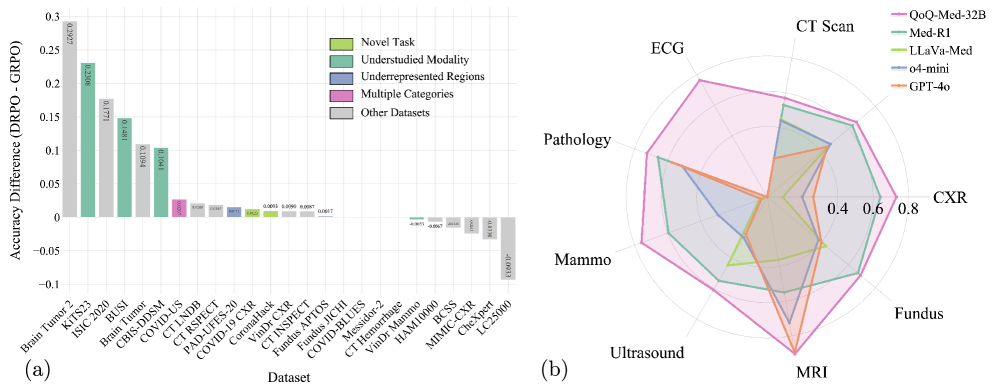
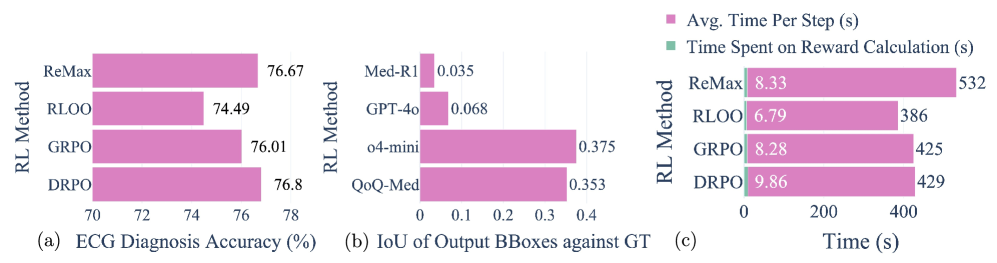
- 实验结果表明,QoQ-Med在所有视觉领域的宏F1诊断性能平均提升了43%,并在显著区域突出方面表现优异,IoU比开放模型高出10倍。
📝 摘要(中文)
临床决策通常需要对异构数据进行推理,但现有的多模态语言模型(MLLMs)主要集中于视觉数据,难以在不同临床专业中进行有效推广。为此,本文提出了QoQ-Med-7B/32B,这是首个开放的通用临床基础模型,能够同时对医学图像、时间序列信号和文本报告进行推理。QoQ-Med采用了一种新颖的强化学习目标——领域感知相对策略优化(DRPO),通过根据领域稀缺性和模态难度分层缩放归一化奖励,从而缓解因临床数据分布偏斜造成的性能不平衡。经过261万对跨9个临床领域的指令调优训练,DRPO训练使所有视觉领域的宏F1诊断性能平均提升了43%。此外,QoQ-Med在密集分割数据上训练后,能够突出与诊断相关的显著区域,其IoU比开放模型高出10倍,同时达到了OpenAI o4-mini的性能。
🔬 方法详解
问题定义:本文旨在解决现有多模态语言模型在临床数据推理中的不足,尤其是对异构数据的处理能力差,导致在不同临床专业中的应用受限。
核心思路:提出QoQ-Med模型,通过领域感知相对策略优化(DRPO)进行训练,旨在提升模型在不同模态和领域中的推理能力,缓解数据分布不均带来的性能不平衡。
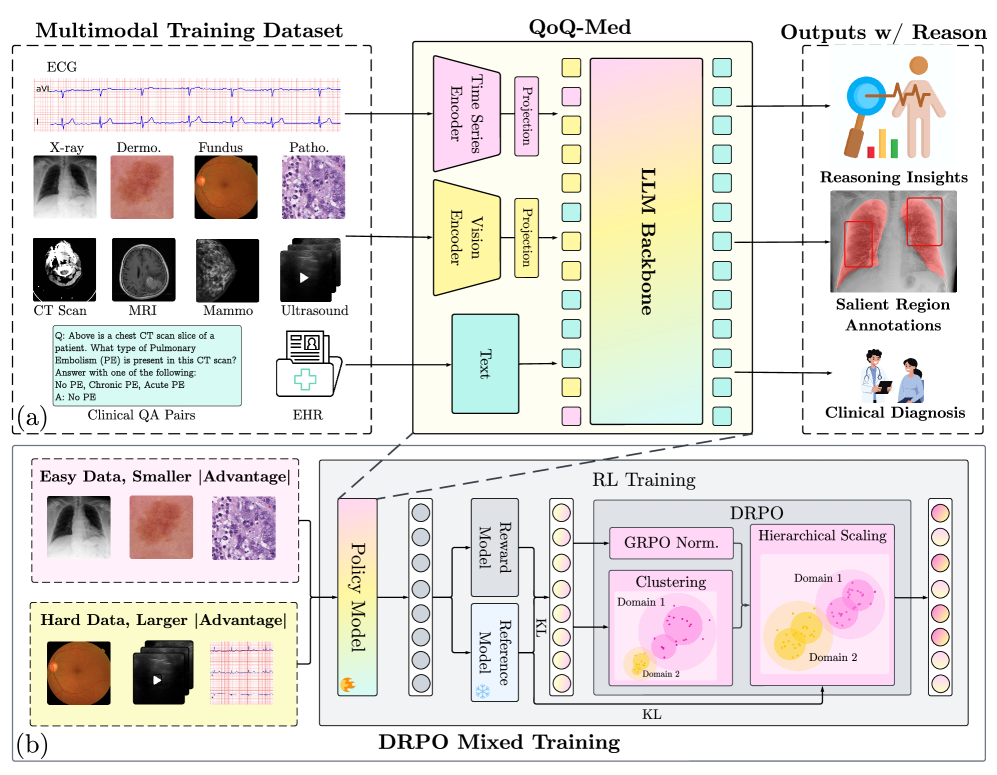
技术框架:QoQ-Med的整体架构包括医学图像处理模块、时间序列信号分析模块和文本报告理解模块,采用DRPO作为训练目标,通过层次化的奖励机制优化模型性能。
关键创新:DRPO是本文的核心创新,通过根据领域稀缺性和模态难度调整奖励,显著提升了模型在多模态推理中的表现,与传统的无评论训练方法相比,效果更为显著。
关键设计:在训练过程中,QoQ-Med使用了261万对跨9个临床领域的指令调优数据,采用了特定的损失函数和网络结构设计,以确保模型在不同模态下的有效学习和推理能力。
🖼️ 关键图片
📊 实验亮点
实验结果显示,QoQ-Med在所有视觉领域的宏F1诊断性能平均提升了43%,并且在密集分割任务中,其IoU比开放模型高出10倍,达到了OpenAI o4-mini的性能水平,展示了其在多模态推理中的卓越能力。
🎯 应用场景
QoQ-Med模型在临床决策支持系统中具有广泛的应用潜力,能够帮助医生在处理复杂的异构数据时做出更为准确的诊断。同时,该模型的开放性和可重现性将促进后续研究和开发,推动临床人工智能的进步。
📄 摘要(原文)
Clinical decision-making routinely demands reasoning over heterogeneous data, yet existing multimodal language models (MLLMs) remain largely vision-centric and fail to generalize across clinical specialties. To bridge this gap, we introduce QoQ-Med-7B/32B, the first open generalist clinical foundation model that jointly reasons across medical images, time-series signals, and text reports. QoQ-Med is trained with Domain-aware Relative Policy Optimization (DRPO), a novel reinforcement-learning objective that hierarchically scales normalized rewards according to domain rarity and modality difficulty, mitigating performance imbalance caused by skewed clinical data distributions. Trained on 2.61 million instruction tuning pairs spanning 9 clinical domains, we show that DRPO training boosts diagnostic performance by 43% in macro-F1 on average across all visual domains as compared to other critic-free training methods like GRPO. Furthermore, with QoQ-Med trained on intensive segmentation data, it is able to highlight salient regions related to the diagnosis, with an IoU 10x higher than open models while reaching the performance of OpenAI o4-mini. To foster reproducibility and downstream research, we release (i) the full model weights, (ii) the modular training pipeline, and (iii) all intermediate reasoning traces at https://github.com/DDVD233/QoQ_Med.