Existing Large Language Model Unlearning Evaluations Are Inconclusive
作者: Zhili Feng, Yixuan Even Xu, Alexander Robey, Robert Kirk, Xander Davies, Yarin Gal, Avi Schwarzschild, J. Zico Kolter
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-05-31
💡 一句话要点
揭示大语言模型卸载评估的局限性,提出更可靠的评估原则
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 机器学习卸载 评估方法 信息注入 下游任务 数据隐私 模型安全
📋 核心要点
- 现有大语言模型卸载评估方法存在缺陷,可能无法准确反映卸载效果,导致对卸载能力的误判。
- 论文提出最小信息注入和下游任务感知的评估原则,旨在避免评估过程中引入偏差,更真实地评估卸载性能。
- 实验表明,违反提出的评估原则会导致误导性结论,验证了新原则的有效性,并为未来卸载评估提供了指导。
📝 摘要(中文)
机器学习卸载旨在从大型语言模型中移除敏感或不需要的数据。然而,最近的研究表明,卸载通常是浅层的,移除的知识很容易被恢复。本文批判性地考察了标准的卸载评估实践,并揭示了关键的局限性,这些局限性动摇了我们对这些发现的信任。首先,我们表明一些评估引入了大量的新信息到模型中,可能通过在测试期间重新训练模型来掩盖真实的卸载性能。其次,我们证明了评估结果在不同任务中差异显著,破坏了当前评估程序的通用性。最后,我们发现许多评估依赖于虚假的相关性,使得它们的结果难以信任和解释。总而言之,这些问题表明,当前的评估协议可能既高估又低估了卸载的成功。为了解决这个问题,我们为未来的卸载评估提出了两个原则:最小信息注入和下游任务感知。我们通过一系列有针对性的实验验证了这些原则,展示了违反每一项原则如何导致误导性的结论。
🔬 方法详解
问题定义:现有的大语言模型卸载评估方法存在三个主要问题。一是评估过程中引入了过多的新信息,导致模型在测试时被重新训练,掩盖了真实的卸载效果。二是评估结果在不同任务之间差异很大,缺乏通用性。三是许多评估依赖于虚假的相关性,使得结果难以解释和信任。这些问题导致我们无法准确评估现有卸载技术的有效性。
核心思路:论文的核心思路是提出两个新的评估原则:最小信息注入和下游任务感知。最小信息注入原则要求在评估过程中尽可能减少引入的新信息,避免重新训练模型。下游任务感知原则要求评估应该关注卸载对下游任务的影响,而不是仅仅关注模型是否忘记了特定的数据。
技术框架:论文没有提出新的卸载算法,而是专注于评估框架的改进。其核心在于对现有评估流程的分析和改进建议。具体来说,论文分析了现有评估方法中存在的问题,并提出了相应的解决方案。例如,针对信息注入问题,建议使用更少的测试数据或采用更严格的测试方法。针对任务泛化问题,建议在多个不同的下游任务上进行评估。
关键创新:论文的关键创新在于提出了两个新的评估原则,并证明了这些原则的重要性。这两个原则为未来的卸载评估提供了指导,有助于更准确地评估卸载技术的有效性。此外,论文还对现有评估方法进行了深入的分析,揭示了其中存在的问题。
关键设计:论文的关键设计在于如何量化和控制信息注入,以及如何选择合适的下游任务进行评估。对于信息注入,论文建议使用信息论的方法来衡量。对于下游任务选择,论文建议选择与卸载数据相关的任务,并且任务的难度应该适中。
🖼️ 关键图片

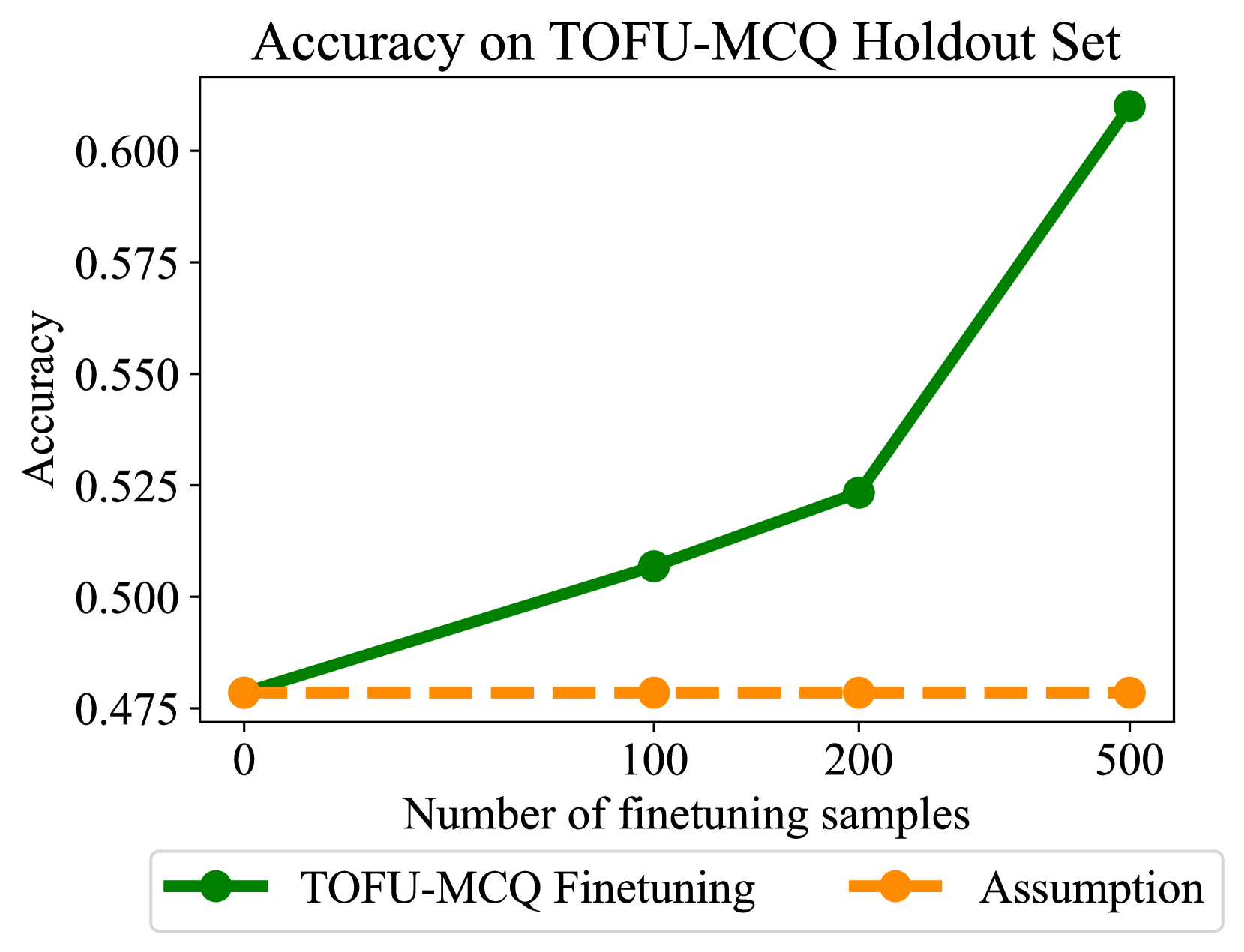
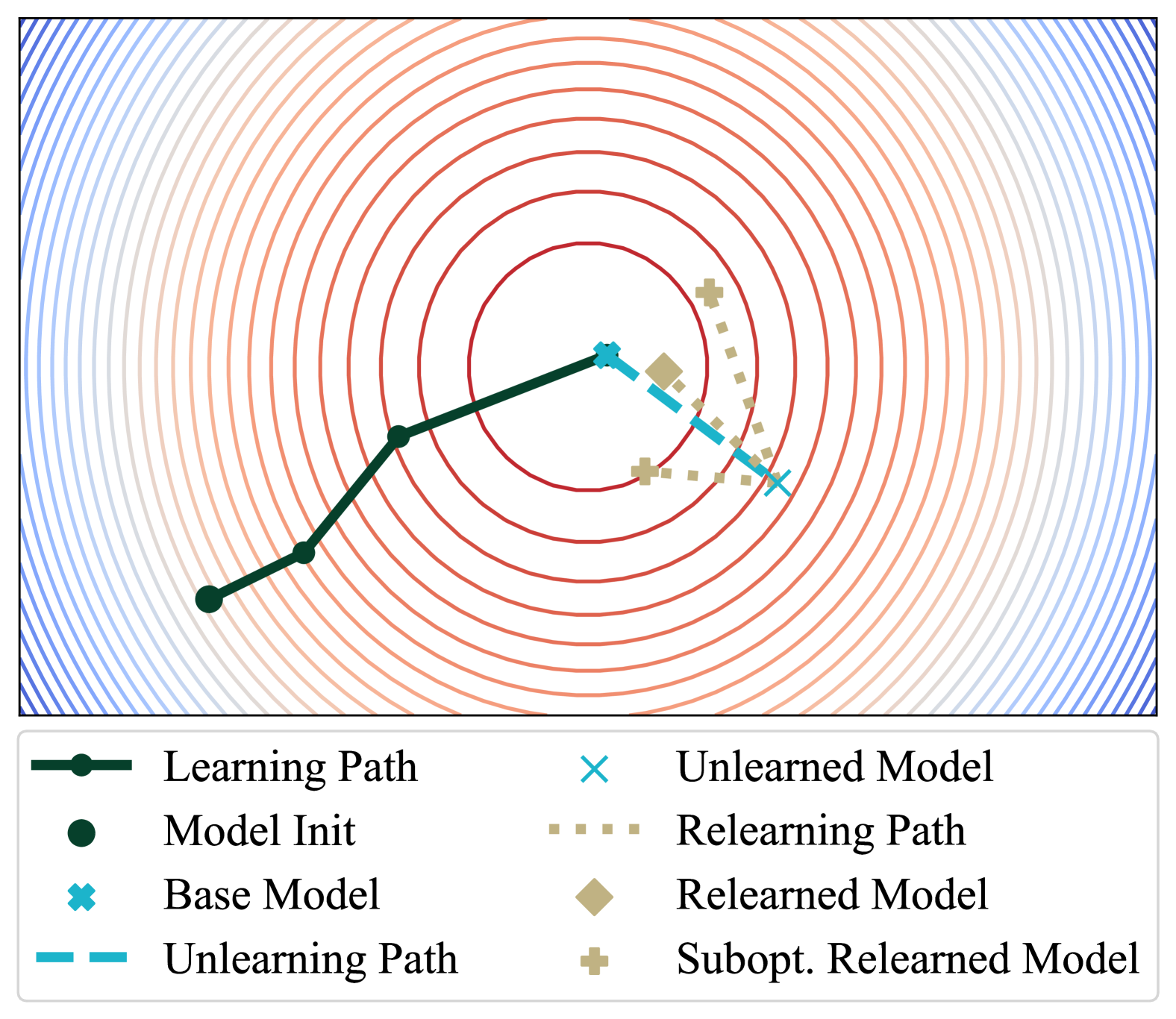
📊 实验亮点
论文通过实验验证了提出的评估原则的有效性。实验表明,违反最小信息注入原则会导致高估卸载效果,而忽略下游任务感知原则则可能低估卸载效果。通过遵循提出的原则,可以更准确地评估卸载技术的性能,并为未来的研究提供指导。
🎯 应用场景
该研究成果可应用于提升大语言模型的数据安全和隐私保护能力。通过更可靠的卸载评估,可以更好地评估和改进卸载算法,确保模型不再包含敏感或有害信息,从而降低模型被滥用的风险,并符合相关法律法规要求。这对于金融、医疗等对数据安全有严格要求的领域尤为重要。
📄 摘要(原文)
Machine unlearning aims to remove sensitive or undesired data from large language models. However, recent studies suggest that unlearning is often shallow, claiming that removed knowledge can easily be recovered. In this work, we critically examine standard unlearning evaluation practices and uncover key limitations that shake our trust in those findings. First, we show that some evaluations introduce substantial new information into the model, potentially masking true unlearning performance by re-teaching the model during testing. Second, we demonstrate that evaluation outcomes vary significantly across tasks, undermining the generalizability of current evaluation routines. Finally, we find that many evaluations rely on spurious correlations, making their results difficult to trust and interpret. Taken together, these issues suggest that current evaluation protocols may both overstate and understate unlearning success. To address this, we propose two principles for future unlearning evaluations: minimal information injection and downstream task awareness. We validate these principles through a series of targeted experiments, showing how violations of each can lead to misleading conclusions.