ORAN-GUIDE: RAG-Driven Prompt Learning for LLM-Augmented Reinforcement Learning in O-RAN Network Slicing
作者: Fatemeh Lotfi, Hossein Rajoli, Fatemeh Afghah
分类: cs.LG, cs.AI
发布日期: 2025-05-31
💡 一句话要点
ORAN-GUIDE:基于RAG的提示学习,用于O-RAN网络切片中LLM增强的强化学习
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: O-RAN 网络切片 强化学习 大型语言模型 提示学习 检索增强生成 多智能体强化学习
📋 核心要点
- 深度强化学习(DRL)难以处理射频特征、QoS指标和流量趋势等原始非结构化输入,限制了策略泛化和决策效率。
- ORAN-GUIDE利用双LLM框架,通过领域知识预训练的ORANSight生成上下文感知的提示,提升DRL代理的状态表示。
- 实验表明,ORAN-GUIDE在样本效率、策略收敛和性能泛化方面优于标准MARL和单LLM基线方法。
📝 摘要(中文)
本文提出ORAN-GUIDE,一个双LLM框架,通过任务相关的、语义增强的状态表示来增强多智能体强化学习(MARL)。该架构采用领域特定语言模型ORANSight,该模型在O-RAN控制和配置数据上进行预训练,以生成结构化的、上下文感知的提示。这些提示与可学习的tokens融合,并传递给一个冻结的基于GPT的编码器,该编码器为DRL代理输出高级语义表示。这种设计采用了一种检索增强生成(RAG)风格的pipeline,专门为无线系统中的技术决策而定制。实验结果表明,与标准MARL和单LLM基线相比,ORAN-GUIDE提高了样本效率、策略收敛和性能泛化。
🔬 方法详解
问题定义:现有深度强化学习(DRL)方法在开放无线接入网络(O-RAN)网络切片场景中,难以有效处理原始、非结构化的输入数据(如射频特征、QoS指标、流量趋势),导致策略泛化能力差,决策效率低,尤其是在部分可观测和动态变化的环境中。
核心思路:利用大型语言模型(LLM)的语义理解和生成能力,将原始的、非结构化的状态信息转化为结构化的、上下文感知的提示(prompt),从而为DRL代理提供更有效的状态表示。通过检索增强生成(RAG)的方式,结合领域知识,提升LLM在特定任务上的性能。
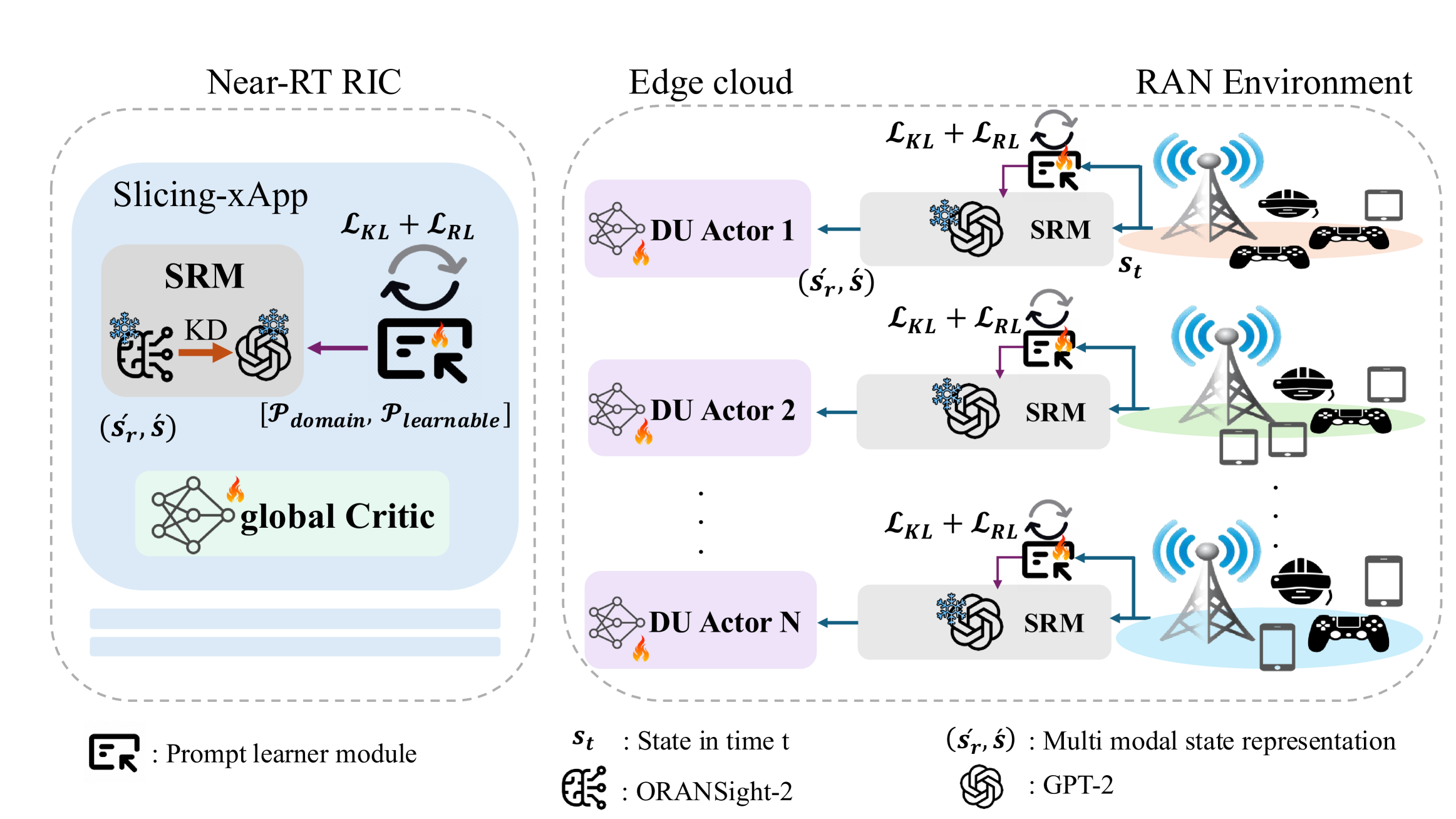
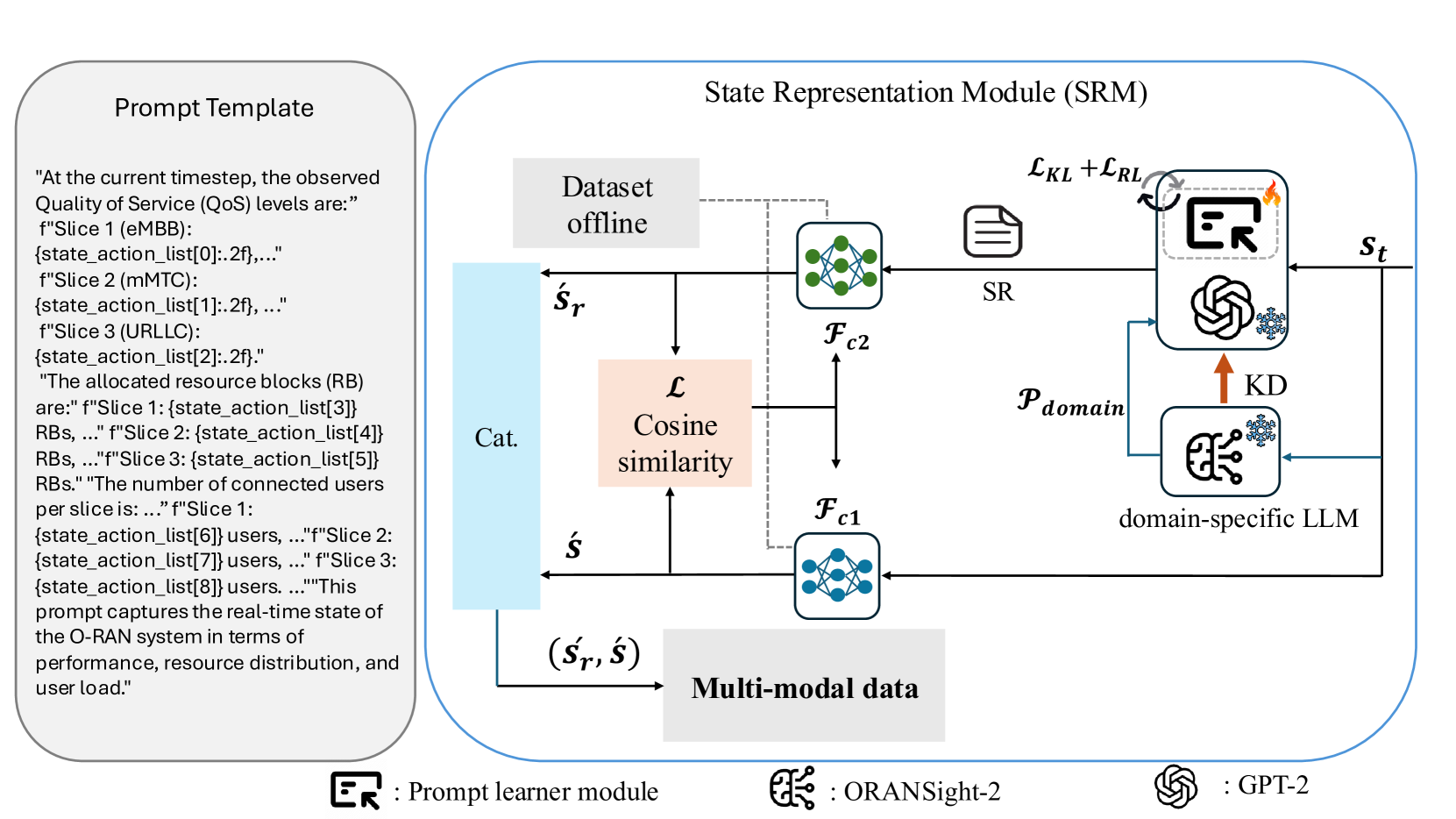
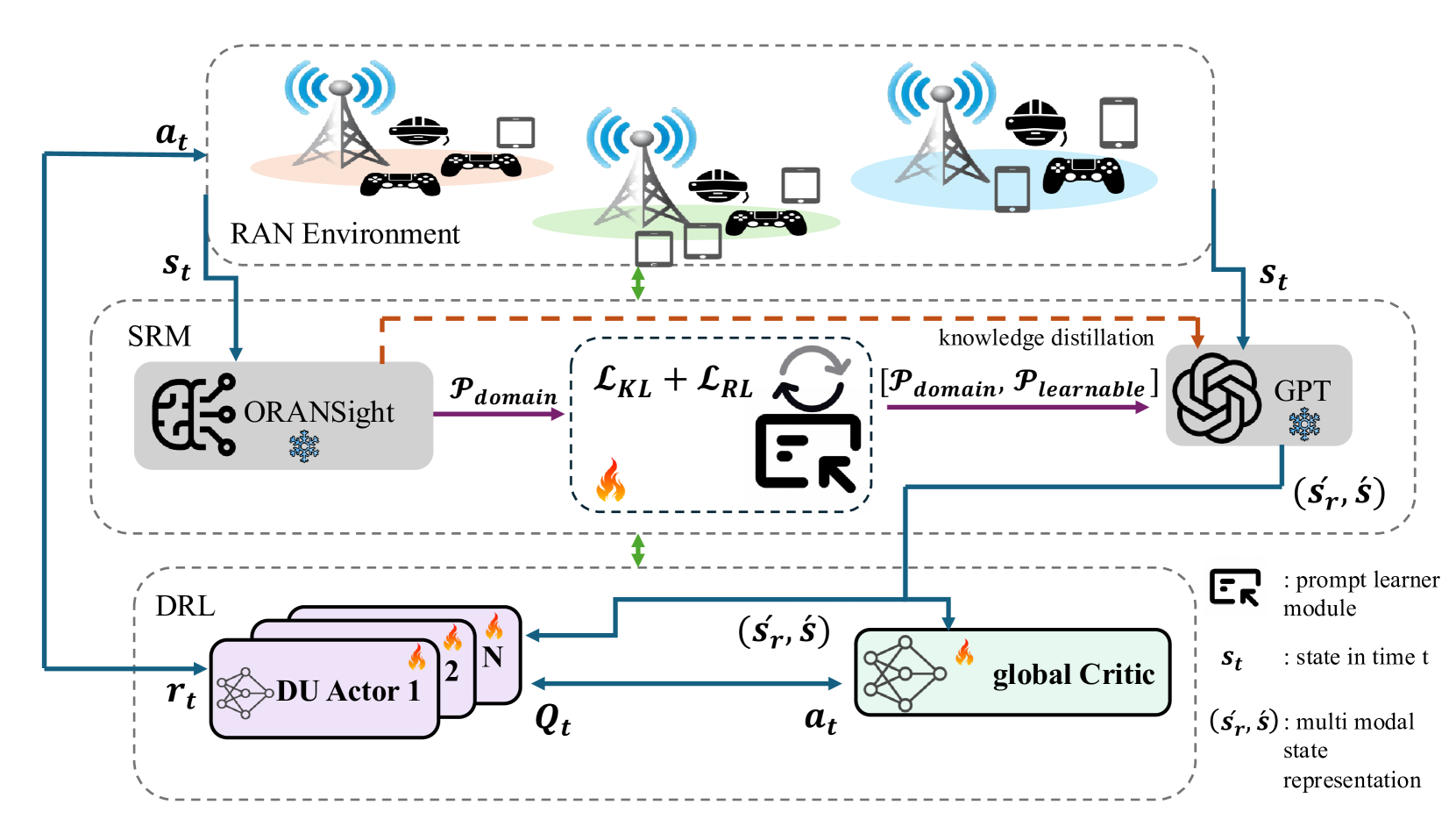
技术框架:ORAN-GUIDE框架包含两个主要的LLM模块:ORANSight和GPT-based Encoder。ORANSight是一个在O-RAN控制和配置数据上预训练的领域特定语言模型,负责生成结构化的提示。这些提示与可学习的tokens融合后,输入到冻结的GPT-based Encoder中,生成高层次的语义表示,供DRL代理使用。整个流程类似于RAG pipeline,但针对无线系统中的技术决策进行了定制。
关键创新:该方法的核心创新在于利用双LLM架构,将领域知识融入到DRL的状态表示中。与传统的MARL方法相比,ORAN-GUIDE能够更好地理解和利用原始输入数据中的语义信息,从而提高策略的泛化能力和决策效率。与单LLM方法相比,ORANSight的领域预训练使其能够生成更准确、更相关的提示。
关键设计:ORANSight的预训练数据包括O-RAN控制和配置数据,用于学习O-RAN领域的知识。可学习的tokens与LLM生成的提示进行融合,允许DRL代理学习特定任务相关的特征。GPT-based Encoder采用冻结的参数,以减少训练成本并提高泛化能力。损失函数的设计需要考虑DRL代理的奖励信号和LLM的提示生成质量。
🖼️ 关键图片
📊 实验亮点
实验结果表明,ORAN-GUIDE在样本效率、策略收敛和性能泛化方面均优于标准MARL和单LLM基线。具体而言,ORAN-GUIDE能够更快地收敛到最优策略,并在不同的网络环境下表现出更好的泛化能力。这些结果验证了ORAN-GUIDE在O-RAN网络切片中的有效性。
🎯 应用场景
ORAN-GUIDE可应用于各种无线网络资源管理和切片场景,例如5G/6G网络、工业物联网、智能交通等。通过提升资源分配和网络切片的智能化水平,可以提高网络效率、降低运营成本,并为用户提供更好的服务质量。该研究为LLM在无线通信领域的应用提供了新的思路,具有重要的实际价值和未来影响。
📄 摘要(原文)
Advanced wireless networks must support highly dynamic and heterogeneous service demands. Open Radio Access Network (O-RAN) architecture enables this flexibility by adopting modular, disaggregated components, such as the RAN Intelligent Controller (RIC), Centralized Unit (CU), and Distributed Unit (DU), that can support intelligent control via machine learning (ML). While deep reinforcement learning (DRL) is a powerful tool for managing dynamic resource allocation and slicing, it often struggles to process raw, unstructured input like RF features, QoS metrics, and traffic trends. These limitations hinder policy generalization and decision efficiency in partially observable and evolving environments. To address this, we propose \textit{ORAN-GUIDE}, a dual-LLM framework that enhances multi-agent RL (MARL) with task-relevant, semantically enriched state representations. The architecture employs a domain-specific language model, ORANSight, pretrained on O-RAN control and configuration data, to generate structured, context-aware prompts. These prompts are fused with learnable tokens and passed to a frozen GPT-based encoder that outputs high-level semantic representations for DRL agents. This design adopts a retrieval-augmented generation (RAG) style pipeline tailored for technical decision-making in wireless systems. Experimental results show that ORAN-GUIDE improves sample efficiency, policy convergence, and performance generalization over standard MARL and single-LLM baselines.