Prompt-Tuned LLM-Augmented DRL for Dynamic O-RAN Network Slicing
作者: Fatemeh Lotfi, Hossein Rajoli, Fatemeh Afghah
分类: cs.LG, cs.AI
发布日期: 2025-05-31
💡 一句话要点
提出Prompt-Tuned LLM增强DRL方法,用于动态O-RAN网络切片资源分配。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: O-RAN切片 深度强化学习 大型语言模型 Prompt Tuning 多智能体强化学习 资源分配 动态网络
📋 核心要点
- 传统DRL在动态无线网络资源分配中面临挑战,原因是反馈分散且不断变化,难以做出最优决策。
- 该论文提出一种基于Prompt-Tuned LLM增强的DRL框架,利用LLM对网络反馈进行语义聚类,提升DRL智能体的决策能力。
- 实验结果表明,该方法加速了收敛,并在O-RAN切片资源分配任务中优于其他基线方法。
📝 摘要(中文)
现代无线网络需要适应动态变化的环境,并高效管理多样化的服务需求。传统的深度强化学习(DRL)在这些环境中表现不佳,因为分散且不断变化的反馈使得优化决策变得困难。大型语言模型(LLM)通过将无组织的网络反馈构建成有意义的潜在表示来提供解决方案,帮助RL智能体更有效地识别模式。例如,在O-RAN切片中,信噪比(SNR)、功率水平和吞吐量等概念在语义上是相关的,LLM可以自然地将它们聚类,从而提供更易于理解的状态表示。为了利用这种能力,我们引入了一种基于上下文的自适应方法,该方法将可学习的提示集成到LLM增强的DRL框架中。我们通过特定于任务的提示来优化状态表示,而不是依赖于完整的模型微调,这些提示可以动态地适应网络条件。利用在O-RAN知识上训练的ORANSight,我们开发了Prompt增强的多智能体RL(PA-MRL)框架。可学习的提示优化了语义聚类和RL目标,使RL智能体能够在更少的迭代中获得更高的奖励并更有效地适应。通过结合提示增强学习,我们的方法能够在O-RAN切片中实现更快、更可扩展和更自适应的资源分配。实验结果表明,它加速了收敛并优于其他基线。
🔬 方法详解
问题定义:论文旨在解决动态O-RAN网络切片中的资源分配问题。现有DRL方法难以有效处理动态变化的网络环境,因为反馈信号分散且时变,导致学习效率低下,难以快速适应新的网络状态。
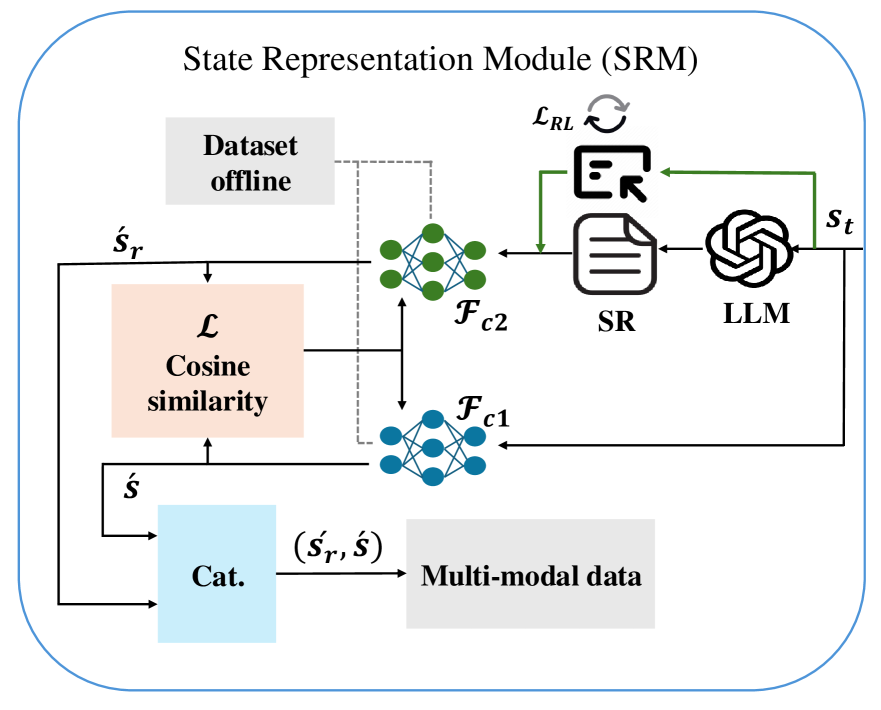
核心思路:核心思路是利用LLM的语义理解能力,将原始的网络状态信息(如SNR、功率水平、吞吐量等)映射到更具语义信息的潜在空间,从而帮助DRL智能体更好地理解网络状态,并做出更有效的资源分配决策。通过引入可学习的Prompt,进一步引导LLM提取与当前任务相关的特征,提升DRL的性能。
技术框架:整体框架为Prompt-Augmented Multi-agent RL (PA-MRL)。首先,利用LLM(ORANSight)对原始网络状态进行编码,生成状态表示。然后,通过可学习的Prompt对LLM的输出进行调整,提取与资源分配任务相关的特征。最后,将Prompt调整后的状态表示输入到多智能体RL算法中,进行资源分配决策。整个框架通过联合优化Prompt和RL目标,实现端到端的学习。
关键创新:关键创新在于将Prompt Tuning技术引入到LLM增强的DRL框架中。与传统的微调LLM方法相比,Prompt Tuning只需要训练少量的Prompt参数,大大降低了计算成本和存储成本,更易于部署到实际的网络环境中。此外,可学习的Prompt能够动态地适应网络条件,提升了DRL智能体的泛化能力。
关键设计:论文使用ORANSight作为LLM,该模型在O-RAN相关知识上进行了预训练。Prompt被设计为可学习的向量,通过梯度下降法进行优化。损失函数包括RL奖励和语义聚类损失,用于同时优化资源分配性能和状态表示的语义一致性。多智能体RL算法采用Actor-Critic结构,每个智能体负责控制一个或多个网络切片的资源分配。
🖼️ 关键图片


📊 实验亮点
实验结果表明,所提出的PA-MRL框架在O-RAN切片资源分配任务中表现出色,加速了收敛速度,并且优于其他基线方法。具体而言,PA-MRL在相同迭代次数下获得了更高的平均奖励,表明其学习效率更高。此外,PA-MRL在不同网络条件下表现出更强的泛化能力,能够适应动态变化的网络环境。
🎯 应用场景
该研究成果可应用于各种动态无线网络资源分配场景,例如5G/6G网络切片、边缘计算资源调度、物联网设备管理等。通过利用LLM的语义理解能力,可以实现更智能、更高效的资源分配,提升网络性能和服务质量,为用户提供更好的体验。未来,该方法还可以扩展到其他领域,例如智能交通、智能制造等。
📄 摘要(原文)
Modern wireless networks must adapt to dynamic conditions while efficiently managing diverse service demands. Traditional deep reinforcement learning (DRL) struggles in these environments, as scattered and evolving feedback makes optimal decision-making challenging. Large Language Models (LLMs) offer a solution by structuring unorganized network feedback into meaningful latent representations, helping RL agents recognize patterns more effectively. For example, in O-RAN slicing, concepts like SNR, power levels and throughput are semantically related, and LLMs can naturally cluster them, providing a more interpretable state representation. To leverage this capability, we introduce a contextualization-based adaptation method that integrates learnable prompts into an LLM-augmented DRL framework. Instead of relying on full model fine-tuning, we refine state representations through task-specific prompts that dynamically adjust to network conditions. Utilizing ORANSight, an LLM trained on O-RAN knowledge, we develop Prompt-Augmented Multi agent RL (PA-MRL) framework. Learnable prompts optimize both semantic clustering and RL objectives, allowing RL agents to achieve higher rewards in fewer iterations and adapt more efficiently. By incorporating prompt-augmented learning, our approach enables faster, more scalable, and adaptive resource allocation in O-RAN slicing. Experimental results show that it accelerates convergence and outperforms other baselines.