MMedAgent-RL: Optimizing Multi-Agent Collaboration for Multimodal Medical Reasoning
作者: Peng Xia, Jinglu Wang, Yibo Peng, Kaide Zeng, Zihan Dong, Xian Wu, Xiangru Tang, Hongtu Zhu, Yun Li, Linjun Zhang, Shujie Liu, Yan Lu, Huaxiu Yao
分类: cs.LG, cs.AI, cs.CL, cs.CV
发布日期: 2025-05-31 (更新: 2026-01-26)
备注: ICLR 2026
💡 一句话要点
MMedAgent-RL:基于强化学习的多智能体协作优化多模态医学推理
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多智能体协作 强化学习 医学视觉-语言模型 多模态医学推理 课程学习 动态熵正则化 智能诊断 医学VQA
📋 核心要点
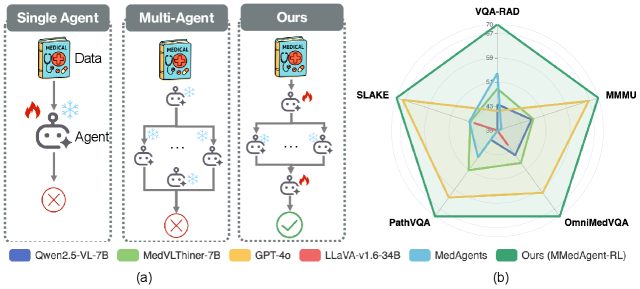
- 现有医学视觉-语言模型难以跨医学专科泛化,且多智能体协作框架缺乏灵活性和适应性。
- 提出MMedAgent-RL,利用强化学习实现医学智能体间动态协作,优化诊断流程。
- 实验表明,MMedAgent-RL在多个医学VQA基准上显著优于现有模型,平均性能提升23.6%。
📝 摘要(中文)
医学大型视觉-语言模型(Med-LVLMs)在多模态诊断任务中展现出强大的潜力。然而,现有的单智能体模型难以泛化到不同的医学专科,限制了其性能。最近的研究引入了受临床工作流程启发的的多智能体协作框架,其中全科医生(GPs)和专家以固定的顺序进行交互。尽管有所改进,但这些静态流程缺乏推理的灵活性和适应性。为了解决这个问题,我们提出了MMedAgent-RL,一个基于强化学习(RL)的多智能体框架,它能够实现医学智能体之间动态、优化的协作。具体来说,我们通过RL训练了两个基于Qwen2.5-VL的GP智能体:分诊医生学习将患者分配到合适的专科,而主治医生整合来自多专家的判断和自身的知识来做出最终决策。为了解决专家输出的不一致性,我们引入了一种课程学习(CL)引导的RL策略,并结合动态熵正则化,逐步教导主治医生在模仿专家和纠正他们的错误之间取得平衡。在五个医学VQA基准上的实验表明,MMedAgent-RL优于开源和专有的Med-LVLMs,平均性能提升了23.6%。
🔬 方法详解
问题定义:论文旨在解决医学大型视觉-语言模型(Med-LVLMs)在多模态医学推理中,由于单智能体模型泛化能力不足以及现有固定流程多智能体协作框架缺乏灵活性和适应性而导致性能受限的问题。现有方法的痛点在于无法根据具体病例动态调整专家协作方式,导致诊断效率和准确性降低。
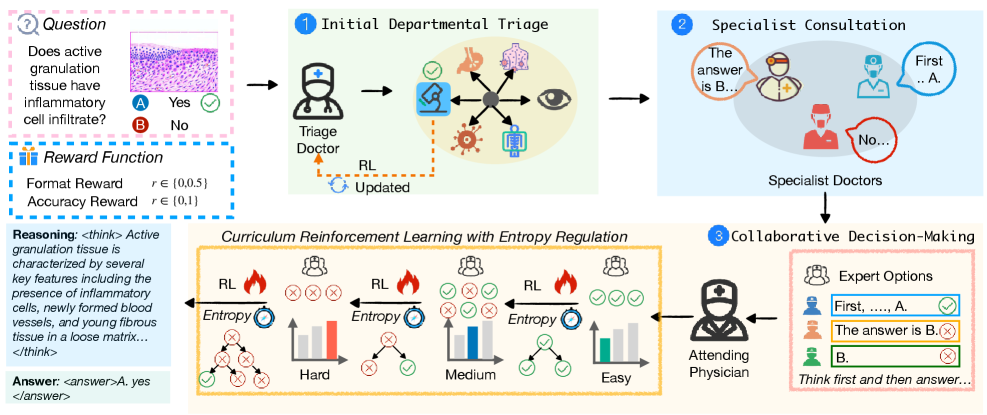
核心思路:论文的核心思路是利用强化学习(RL)训练多个医学智能体,使其能够动态地进行协作,从而优化多模态医学推理过程。通过RL,智能体可以学习在不同情况下选择合适的专家进行咨询,并整合专家的意见做出最终决策,从而提高诊断的准确性和效率。这种动态协作的方式能够更好地适应不同病例的复杂性和特殊性。
技术框架:MMedAgent-RL框架包含两个主要的全科医生(GP)智能体:分诊医生和主治医生。分诊医生负责将患者分配到合适的专科,主治医生负责整合来自多专家的判断和自身的知识来做出最终决策。整个流程如下:首先,分诊医生根据患者的病情将患者分配给多个专科专家;然后,主治医生收集各专家的诊断意见,并结合自身的知识进行综合分析;最后,主治医生做出最终的诊断决策。整个过程中,分诊医生和主治医生都通过强化学习进行训练,以优化其决策能力。
关键创新:论文最重要的技术创新点在于引入了基于强化学习的动态多智能体协作框架。与现有的固定流程多智能体框架相比,MMedAgent-RL能够根据具体病例动态调整专家协作方式,从而提高诊断的准确性和效率。此外,论文还提出了课程学习(CL)引导的RL策略,并结合动态熵正则化,以解决专家输出的不一致性问题,进一步提高了主治医生的决策能力。
关键设计:论文的关键设计包括:1) 使用Qwen2.5-VL作为基础模型;2) 设计了基于强化学习的奖励函数,以鼓励智能体做出正确的诊断决策;3) 引入了课程学习策略,逐步提高主治医生的决策能力;4) 使用动态熵正则化来平衡模仿专家和纠正专家错误之间的关系。具体的参数设置和网络结构等细节在论文中有详细描述。
🖼️ 关键图片
📊 实验亮点
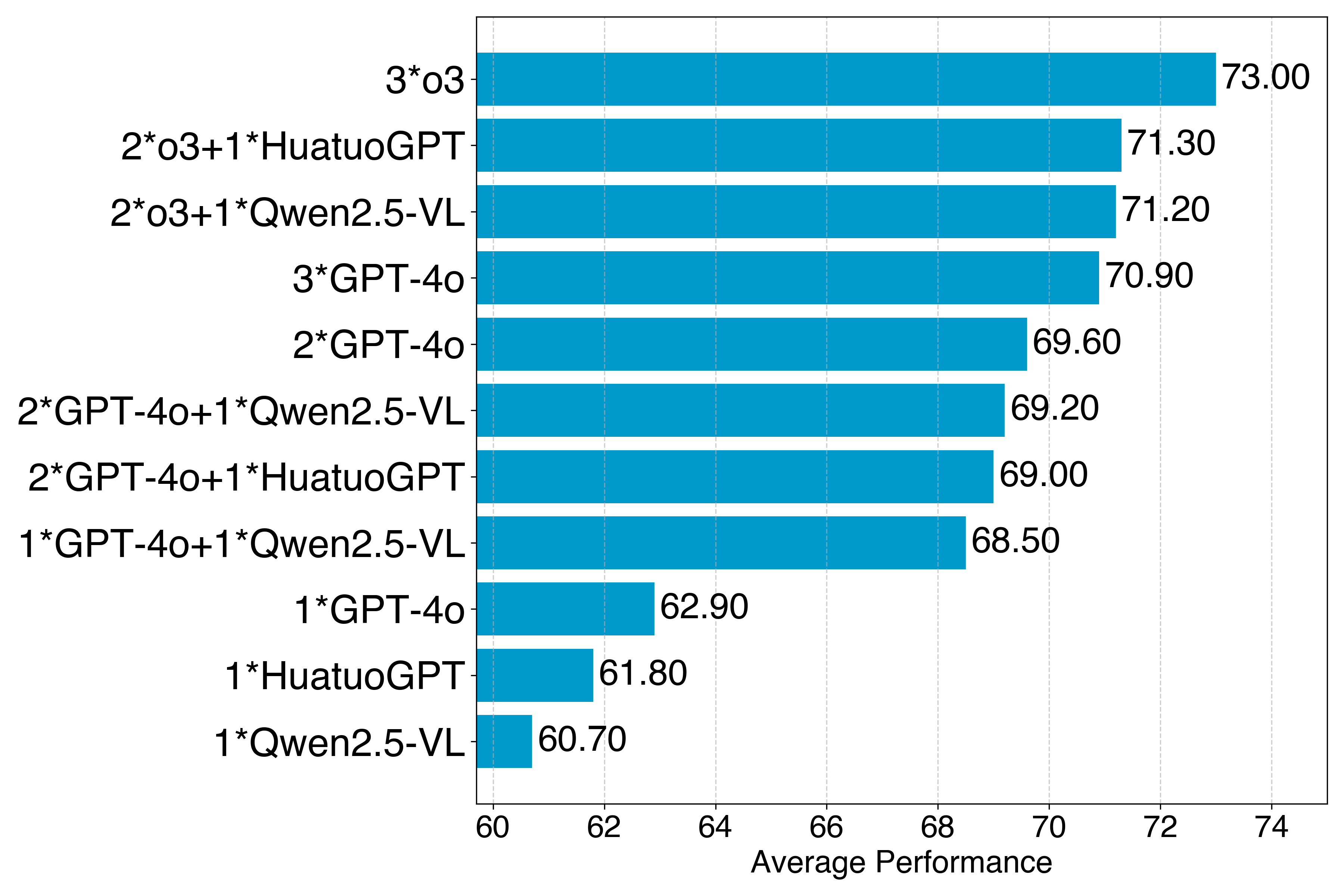
MMedAgent-RL在五个医学VQA基准上取得了显著的性能提升,平均性能增益达到23.6%,超越了现有的开源和专有Med-LVLMs模型。这一结果表明,基于强化学习的动态多智能体协作框架能够有效地提高医学推理的准确性和效率。特别是在处理复杂病例和整合多专家意见方面,MMedAgent-RL展现出强大的优势。
🎯 应用场景
该研究成果可应用于智能诊断系统、远程医疗、医学教育等领域。通过构建智能化的多智能体协作诊断平台,可以辅助医生进行诊断决策,提高诊断效率和准确性,尤其是在医疗资源匮乏的地区具有重要的应用价值。未来,该研究可以进一步扩展到更多医学专科和更复杂的病例,为实现精准医疗提供有力支持。
📄 摘要(原文)
Medical Large Vision-Language Models (Med-LVLMs) have shown strong potential in multimodal diagnostic tasks. However, existing single-agent models struggle to generalize across diverse medical specialties, limiting their performance. Recent efforts introduce multi-agent collaboration frameworks inspired by clinical workflows, where general practitioners (GPs) and specialists interact in a fixed sequence. Despite improvements, these static pipelines lack flexibility and adaptability in reasoning. To address this, we propose MMedAgent-RL, a reinforcement learning (RL)-based multi-agent framework that enables dynamic, optimized collaboration among medical agents. Specifically, we train two GP agents based on Qwen2.5-VL via RL: the triage doctor learns to assign patients to appropriate specialties, while the attending physician integrates the judgments from multi-specialists and its own knowledge to make final decisions. To address the inconsistency in specialist outputs, we introduce a curriculum learning (CL)-guided RL strategy with dynamic entropy regulation, progressively teaching the attending physician to balance between imitating specialists and correcting their mistakes. Experiments on five medical VQA benchmarks demonstrate that MMedAgent-RL outperforms both open-source and proprietary Med-LVLMs. Notably, it achieves an average performance gain of 23.6% over strong baselines.