It Takes a Good Model to Train a Good Model: Generalized Gaussian Priors for Optimized LLMs
作者: Jun Wu, Yirong Xiong, Jiangtao Wen, Yuxing Han
分类: cs.LG, cs.AI, stat.ML
发布日期: 2025-05-31 (更新: 2025-06-04)
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
基于广义高斯先验的LLM优化框架,实现高效、可扩展和硬件友好的AI系统
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型优化 广义高斯分布 模型压缩 量化 硬件效率 初始化方法 正则化
📋 核心要点
- 现有LLM研究较少关注模型参数的统计分布及其对训练和效率的影响,导致优化潜力未被充分挖掘。
- 论文提出基于广义高斯分布(GGD)的LLM优化框架,包括GG初始化、DeepShape正则化和RF8量化,旨在提升模型效率。
- 实验表明,该框架能生成更小、更快的模型,性能与标准基线持平或更优,验证了统计建模在LLM优化中的有效性。
📝 摘要(中文)
尽管大型语言模型(LLM)的研究和部署取得了快速进展,但模型参数的统计分布及其对初始化、训练动态和下游效率的影响却受到的关注相对较少。最近的一项工作BackSlash表明,预训练LLM参数更符合广义高斯分布(GGD)。通过在训练期间优化GG先验,BackSlash可以将参数减少高达90%,而性能损失极小。基于这一基础性见解,我们提出了一个统一的、端到端的基于GG模型的LLM优化框架。我们的贡献有三方面:(1)基于GG的初始化方案,与训练模型的统计结构对齐,从而加快收敛速度并提高准确性;(2)DeepShape,一种后训练正则化方法,可重塑权重分布以匹配GG轮廓,从而提高可压缩性,同时最大限度地减少性能下降;(3)RF8,一种紧凑且硬件高效的8位浮点格式,专为GG分布初始化的BackSlash训练而设计,可在不影响准确性的情况下实现低成本推理。在各种模型架构上的实验表明,我们的框架始终产生更小、更快的模型,这些模型与标准训练基线相匹配或优于标准训练基线。通过将LLM开发建立在有原则的统计建模基础上,这项工作为高效、可扩展和硬件感知的AI系统开辟了一条新道路。
🔬 方法详解
问题定义:现有大型语言模型(LLM)的优化方法通常忽略了模型参数的统计分布特性,导致初始化效率低下、模型压缩困难以及硬件部署成本高昂。现有方法未能充分利用模型参数的内在统计结构,限制了模型的性能和效率。
核心思路:论文的核心思路是基于广义高斯分布(GGD)对LLM参数进行建模,并利用GGD的特性来指导模型的初始化、训练和量化。通过使模型参数的分布与GGD对齐,可以提高模型的收敛速度、可压缩性和硬件效率。这种方法的核心在于将统计建模作为LLM优化的基础。
技术框架:该框架包含三个主要模块:1) GG初始化:使用基于GGD的初始化方案,使模型参数的初始分布与训练后的分布更接近,从而加快收敛速度。2) DeepShape正则化:在后训练阶段,通过正则化方法重塑权重分布,使其更符合GGD轮廓,提高模型的可压缩性。3) RF8量化:设计了一种新的8位浮点格式(RF8),专为GGD分布初始化的BackSlash训练而设计,以实现低成本的推理。
关键创新:该论文的关键创新在于将广义高斯分布(GGD)作为LLM优化的核心指导原则。与传统的优化方法不同,该方法充分利用了模型参数的统计特性,从而实现了更高效的初始化、训练和量化。此外,RF8量化格式的设计也针对GGD分布进行了优化,进一步提高了硬件效率。
关键设计:GG初始化方案的关键在于确定GGD的参数(如均值、方差和形状参数),使其与训练后的模型参数分布相匹配。DeepShape正则化方法通过添加一个正则化项到损失函数中,该正则化项惩罚权重分布与GGD的偏差。RF8量化格式的设计考虑了GGD分布的动态范围,并优化了指数和尾数的分配,以最大限度地减少量化误差。
🖼️ 关键图片
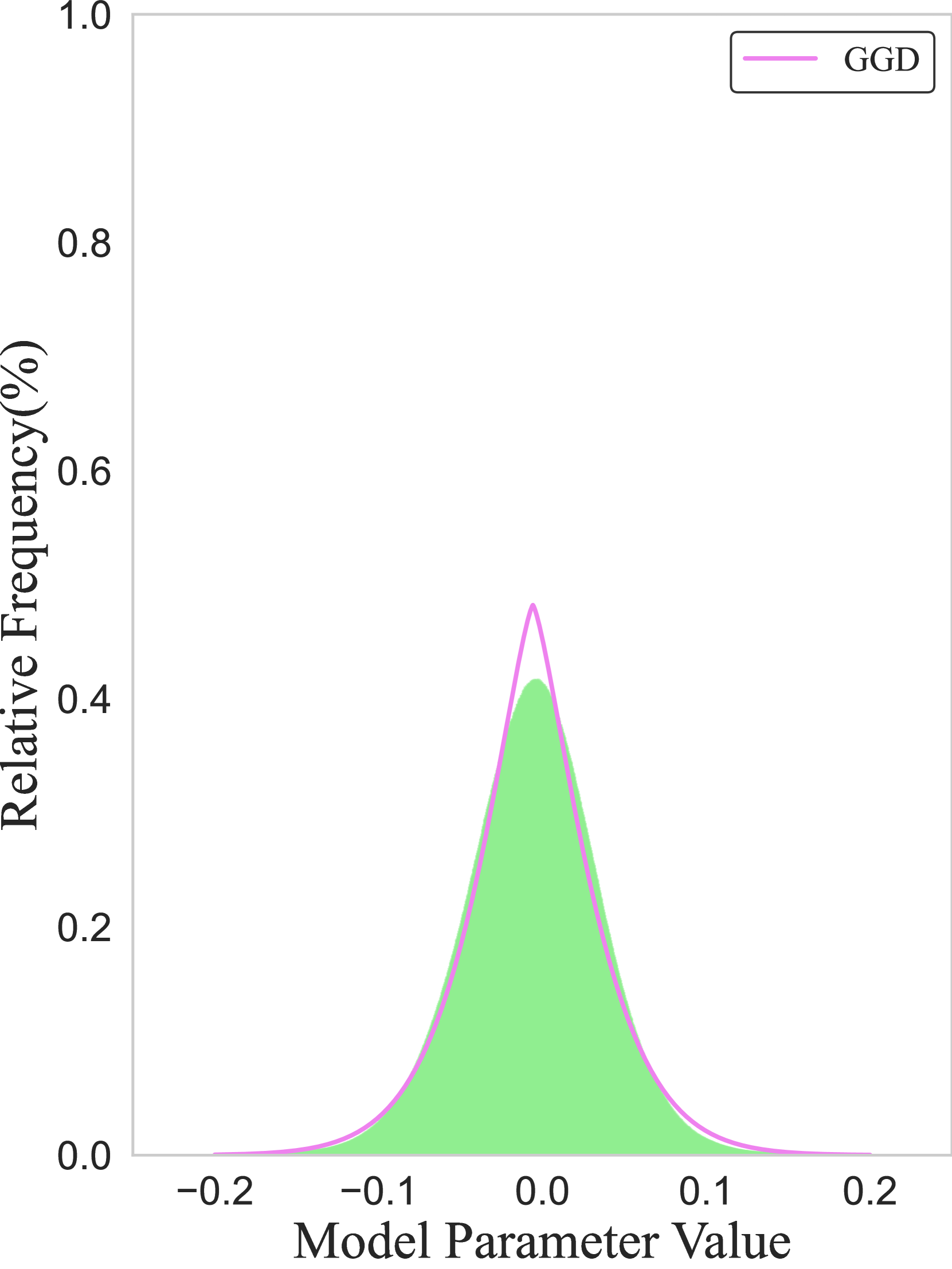
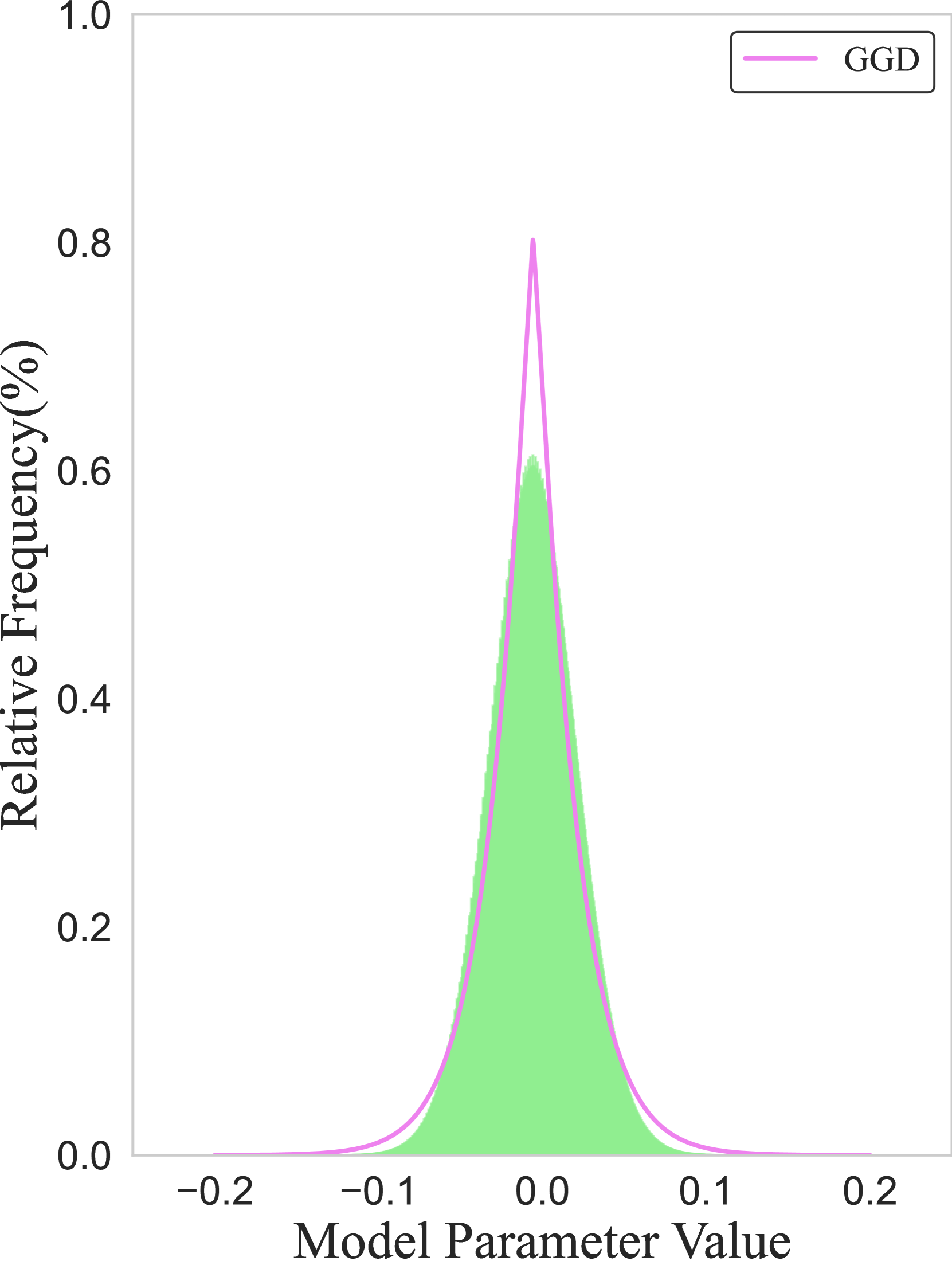
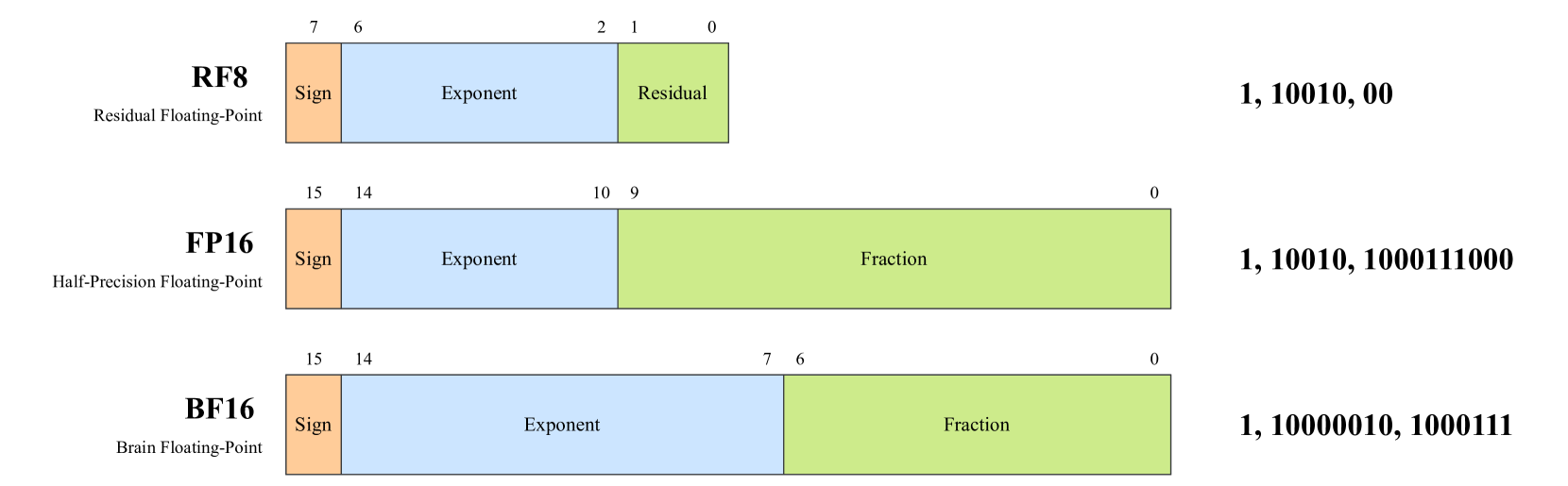
📊 实验亮点
实验结果表明,基于GG先验的优化框架能够显著提高LLM的效率。例如,通过DeepShape正则化,模型可以在性能损失极小的情况下实现更高的压缩率。RF8量化格式能够在保持精度的前提下,显著降低模型的存储和计算需求。该框架在各种模型架构上都表现出一致的性能提升。
🎯 应用场景
该研究成果可广泛应用于各种需要高效LLM部署的场景,例如移动设备上的本地推理、边缘计算和资源受限的服务器。通过降低模型大小和计算复杂度,该方法可以降低部署成本,并使LLM能够应用于更广泛的领域,例如智能助手、自然语言处理和计算机视觉。
📄 摘要(原文)
Despite rapid advancements in the research and deployment of large language models (LLMs), the statistical distribution of model parameters, as well as their influence on initialization, training dynamics, and downstream efficiency, has received surprisingly little attention. A recent work introduced BackSlash, a training-time compression algorithm. It first demonstrated that pre-trained LLM parameters follow generalized Gaussian distributions (GGDs) better. By optimizing GG priors during training, BackSlash can reduce parameters by up to 90\% with minimal performance loss. Building on this foundational insight, we propose a unified, end-to-end framework for LLM optimization based on the GG model. Our contributions are threefold: (1) GG-based initialization scheme that aligns with the statistical structure of trained models, resulting in faster convergence and improved accuracy; (2) DeepShape, a post-training regularization method that reshapes weight distributions to match a GG profile, improving compressibility with minimized degradation in performance; and (3) RF8, a compact and hardware-efficient 8-bit floating-point format designed for GG-distributed-initialized BackSlash training, enabling low-cost inference without compromising accuracy. Experiments across diverse model architectures show that our framework consistently yields smaller and faster models that match or outperform standard training baselines. By grounding LLM development in principled statistical modeling, this work forges a new path toward efficient, scalable, and hardware-aware AI systems. The code is available on our project page: https://huggingface.co/spaces/shifeng3711/gg_prior.