Reinforcement Learning for Hanabi
作者: Nina Cohen, Kordel K. France
分类: cs.LG, cs.AI, cs.GT, cs.MA
发布日期: 2025-05-31
💡 一句话要点
探索强化学习算法在花火游戏中智能体协作策略
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 花火游戏 多智能体协作 时序差分学习 深度Q学习
📋 核心要点
- 花火游戏信息不完全的特性对强化学习智能体提出了挑战,现有方法难以有效建模智能体之间的协作。
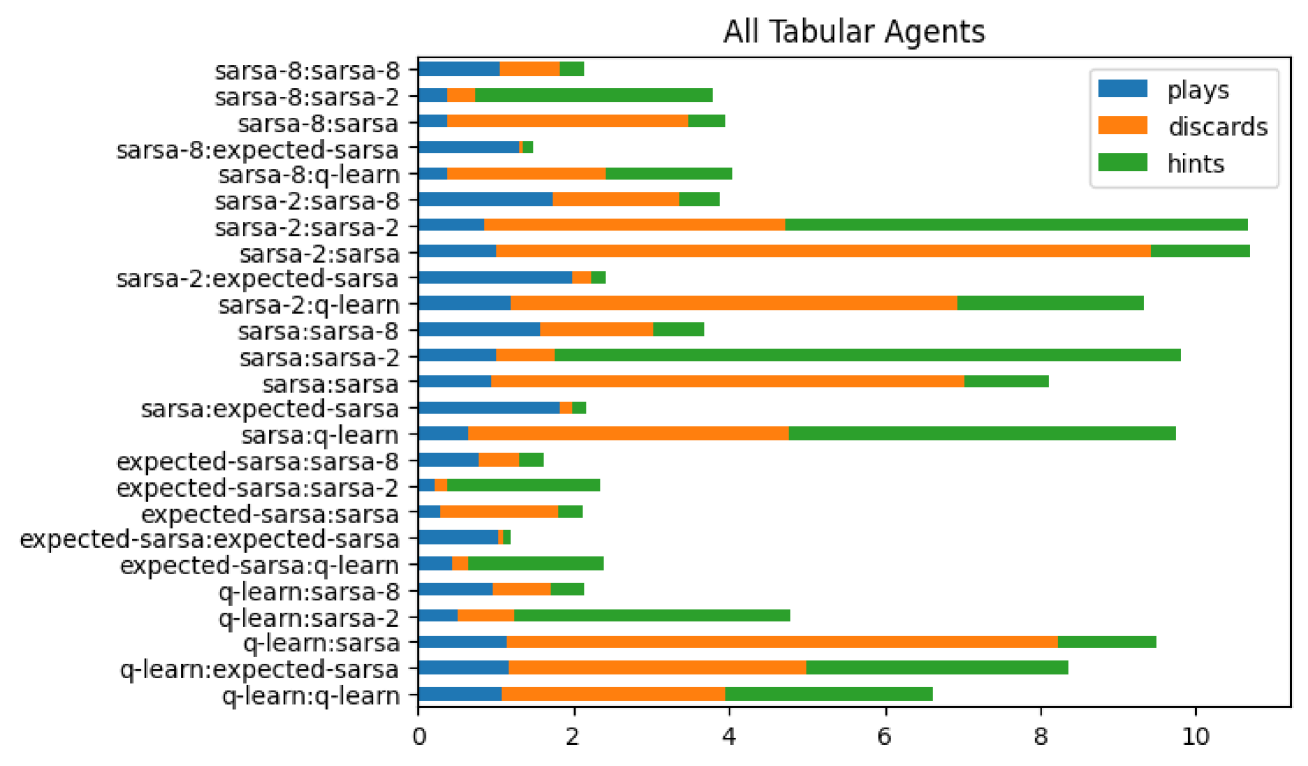
- 本文探索了表格型和深度强化学习算法,通过智能体之间的博弈,研究不同算法的适应性和协作能力。
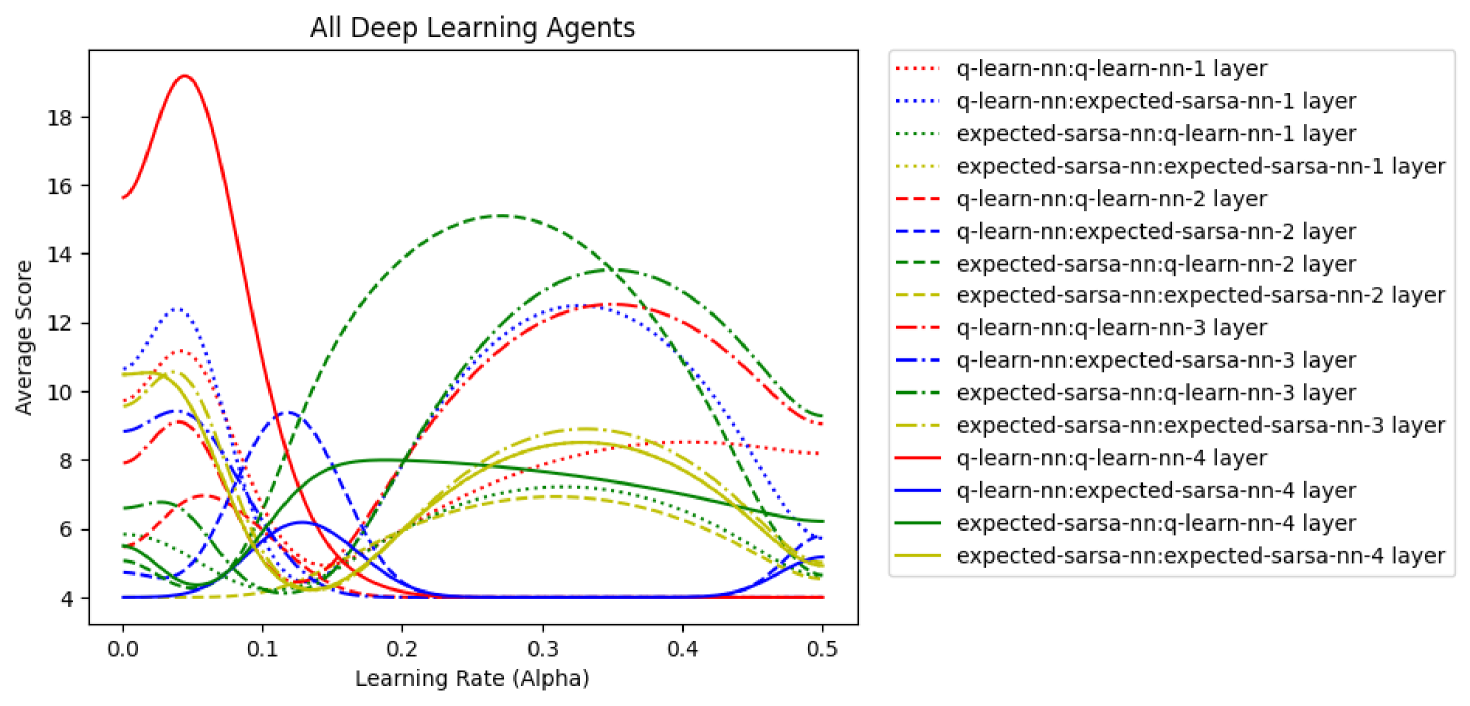
- 实验结果表明,时序差分算法(特别是期望SARSA和深度Q学习)在花火游戏中表现出更好的性能和适应性。
📝 摘要(中文)
花火(Hanabi)作为一种合作纸牌游戏,因其环境信息不完全的特性,已成为强化学习(RL)研究的热门选择,对RL智能体提出了挑战。本文探索了不同的表格型和深度强化学习算法,以评估它们在与同类型智能体以及其他类型智能体对战时的性能。研究表明,某些智能体在与特定智能体对战时表现出最高得分,而另一些智能体则通过适应对手的行为来获得更高的平均分。我们试图量化每种算法提供最佳优势的条件,并识别不同类型智能体之间最有趣的交互。最终发现,与表格型智能体相比,时序差分(TD)算法在整体性能和游戏类型平衡方面表现更好。特别是,表格型期望SARSA和深度Q学习智能体表现出最佳性能。
🔬 方法详解
问题定义:花火游戏是一个合作纸牌游戏,玩家需要合作打出正确的牌,但每个玩家只能看到其他玩家的手牌,而看不到自己的手牌。这导致了信息不对称,使得智能体需要通过观察其他玩家的行为和接收到的信息来推断自己的手牌,并做出最佳决策。现有方法在处理这种不完全信息和智能体之间的协作方面存在挑战。
核心思路:本文的核心思路是利用不同的强化学习算法训练智能体,并通过智能体之间的博弈来评估它们的性能和适应性。通过比较不同算法在不同对战情况下的表现,可以了解每种算法的优势和劣势,并找到最适合花火游戏的算法。同时,研究智能体之间的交互,可以揭示智能体如何学习协作,并为设计更好的协作策略提供指导。
技术框架:本文采用了表格型和深度强化学习两种类型的算法。表格型算法包括Q-Learning和Expected SARSA,它们使用表格来存储状态-动作值函数。深度强化学习算法采用了深度Q网络(DQN),使用神经网络来近似状态-动作值函数。整体流程包括:1. 初始化智能体;2. 智能体之间进行多轮游戏;3. 每轮游戏后,智能体根据游戏结果更新其策略;4. 评估智能体的性能。
关键创新:本文的关键创新在于对不同强化学习算法在花火游戏中的性能进行了全面的评估和比较。通过智能体之间的博弈,揭示了不同算法的适应性和协作能力。此外,本文还尝试量化每种算法提供最佳优势的条件,并识别不同类型智能体之间最有趣的交互。
关键设计:在表格型算法中,状态空间和动作空间需要进行离散化。在深度Q网络中,需要设计合适的网络结构和损失函数。具体的参数设置和网络结构在论文中可能没有详细说明,属于未知信息。损失函数通常采用均方误差损失函数,用于衡量预测的Q值与目标Q值之间的差距。
🖼️ 关键图片

📊 实验亮点
实验结果表明,时序差分算法(特别是表格型期望SARSA和深度Q学习)在花火游戏中表现出更好的性能和适应性。这些算法能够更好地适应对手的行为,并获得更高的平均得分。具体性能数据和提升幅度在论文中可能没有详细说明,属于未知信息。
🎯 应用场景
该研究成果可应用于其他需要智能体之间协作的场景,例如多智能体机器人系统、自动驾驶车辆编队以及分布式资源管理等。通过研究不同算法在花火游戏中的表现,可以为设计更有效的协作策略提供指导,从而提高智能体在复杂环境中的协作能力。
📄 摘要(原文)
Hanabi has become a popular game for research when it comes to reinforcement learning (RL) as it is one of the few cooperative card games where you have incomplete knowledge of the entire environment, thus presenting a challenge for a RL agent. We explored different tabular and deep reinforcement learning algorithms to see which had the best performance both against an agent of the same type and also against other types of agents. We establish that certain agents played their highest scoring games against specific agents while others exhibited higher scores on average by adapting to the opposing agent's behavior. We attempted to quantify the conditions under which each algorithm provides the best advantage and identified the most interesting interactions between agents of different types. In the end, we found that temporal difference (TD) algorithms had better overall performance and balancing of play types compared to tabular agents. Specifically, tabular Expected SARSA and deep Q-Learning agents showed the best performance.