RLAE: Reinforcement Learning-Assisted Ensemble for LLMs
作者: Yuqian Fu, Yuanheng Zhu, Jiajun Chai, Guojun Yin, Wei Lin, Qichao Zhang, Dongbin Zhao
分类: cs.LG, cs.AI
发布日期: 2025-05-31
💡 一句话要点
提出RLAE:强化学习辅助的大语言模型集成框架,提升模型性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型集成 强化学习 动态权重调整 马尔可夫决策过程 文本生成
📋 核心要点
- 现有LLM集成方法依赖固定权重策略,无法适应LLM能力动态变化的上下文。
- RLAE将LLM集成建模为MDP,利用RL智能体动态调整权重,优化最终输出质量。
- 实验表明,RLAE在多种任务上优于现有方法,且具有更好的泛化性和更低延迟。
📝 摘要(中文)
本文提出了一种名为RLAE(Reinforcement Learning-Assisted Ensemble for LLMs)的全新框架,用于大语言模型(LLMs)的集成。该方法将LLM集成重新定义为一个马尔可夫决策过程(MDP),引入一个强化学习(RL)智能体,通过考虑输入上下文和中间生成状态来动态调整集成权重。智能体通过与最终输出质量直接相关的奖励进行训练。RLAE分别使用单智能体和多智能体强化学习算法($ ext{RLAE} ext{PPO}$ 和 $ ext{RLAE} ext{MAPPO}$)实现,在传统集成方法上取得了显著改进。在各种任务上的大量评估表明,RLAE的性能优于现有方法,准确率提高了高达3.3%,为LLM集成提供了一个更有效的框架。此外,该方法在不同任务中表现出卓越的泛化能力,无需重新训练,同时实现了更低的时间延迟。
🔬 方法详解
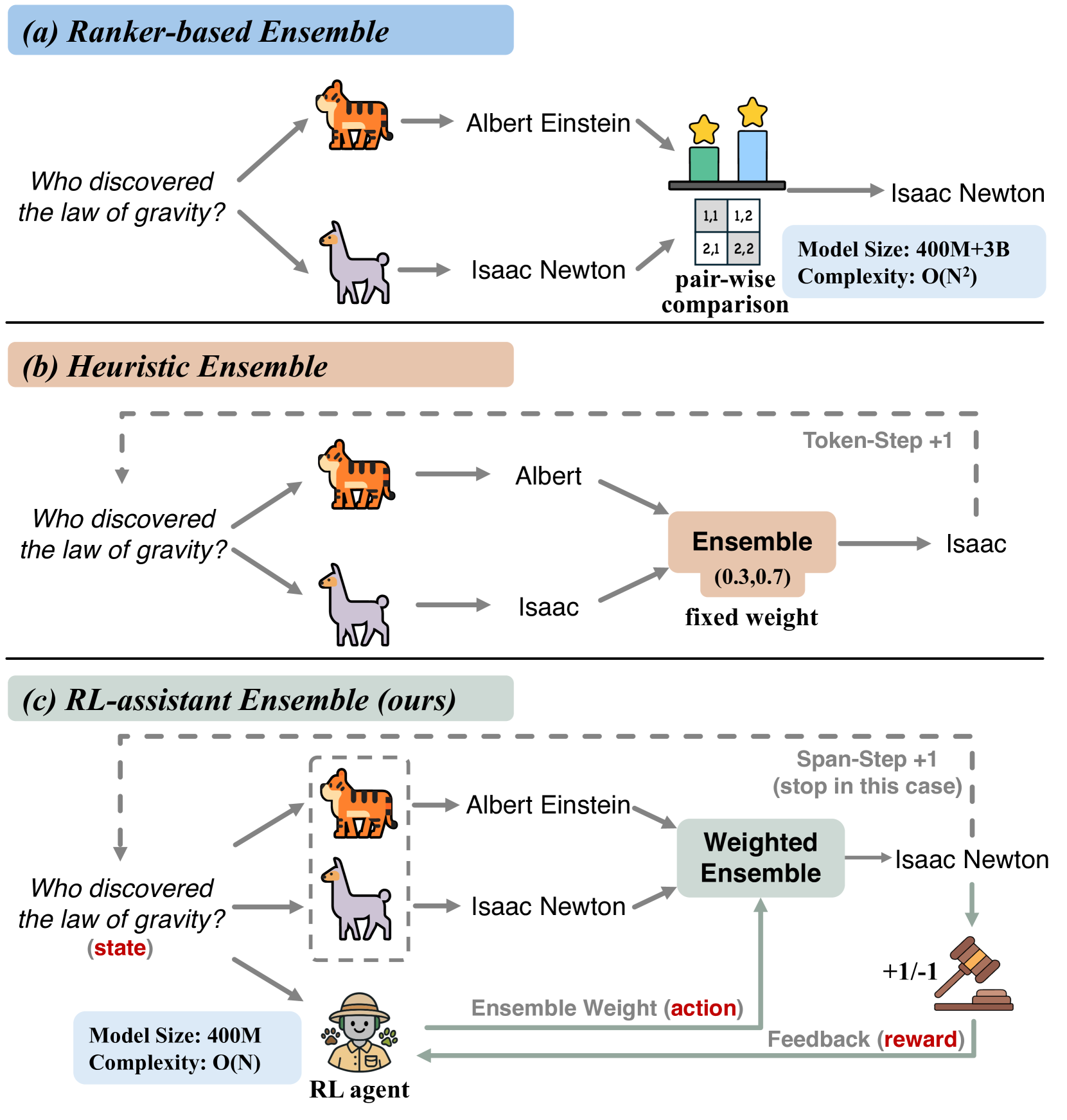
问题定义:现有的大语言模型集成方法通常采用固定的权重策略,无法根据不同的输入上下文和模型的中间生成状态动态调整各个模型的权重。这种静态的集成方式无法充分利用各个模型的优势,导致集成性能受限。因此,需要一种能够自适应调整权重的集成方法,以提升LLM集成的整体性能。
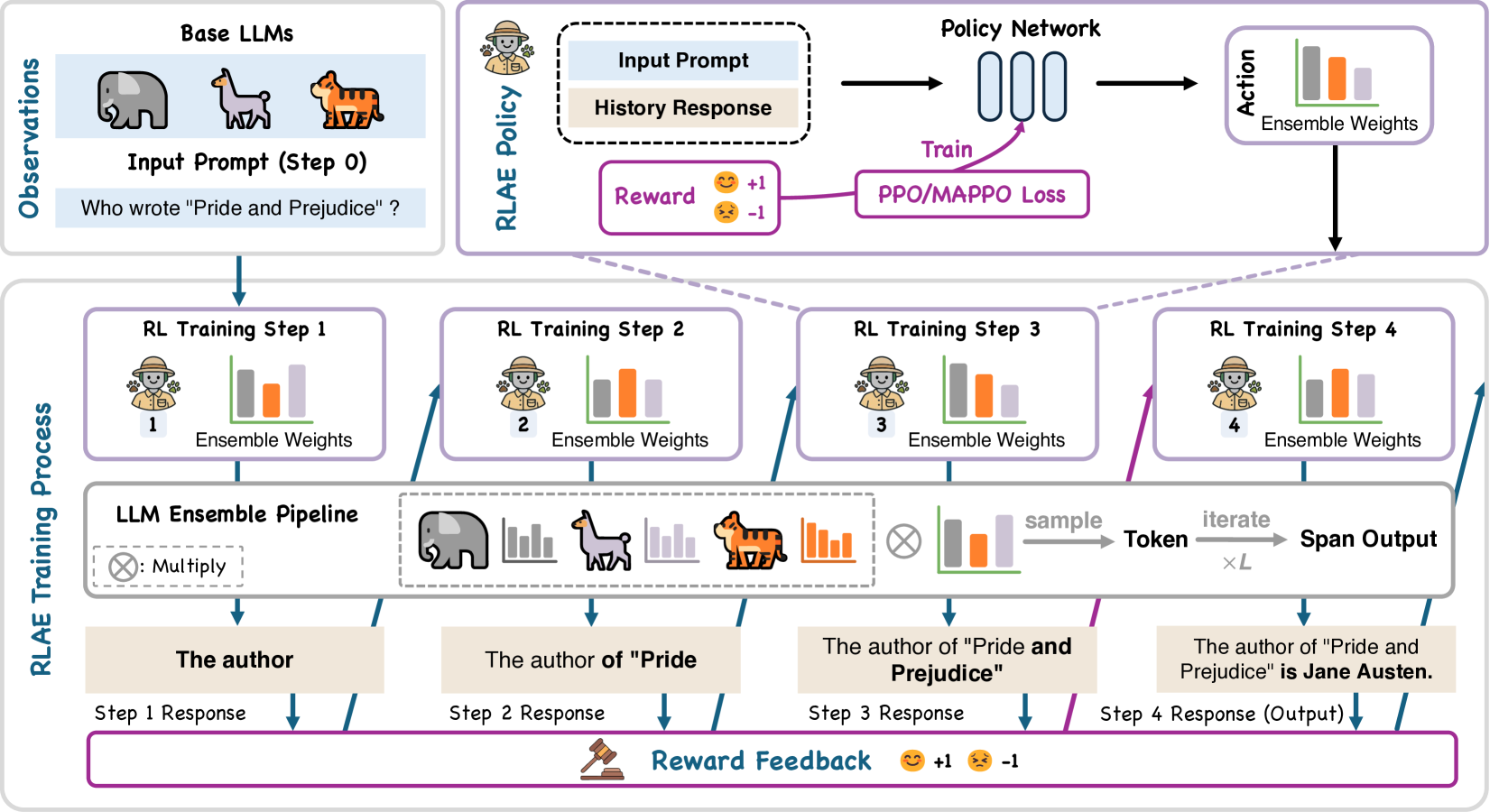
核心思路:RLAE的核心思路是将LLM集成问题建模为一个马尔可夫决策过程(MDP),并引入一个强化学习(RL)智能体来动态调整集成权重。智能体通过观察输入上下文和中间生成状态,学习如何为不同的模型分配合适的权重,从而优化最终的输出质量。这种动态调整权重的策略能够更好地适应LLM能力的变化,提升集成性能。
技术框架:RLAE的整体框架包括以下几个主要模块:1) LLM集合:包含多个预训练的LLM模型。2) 状态表示:将输入上下文和LLM的中间生成状态编码为状态向量。3) 强化学习智能体:根据状态向量,输出各个LLM的权重。4) 集成模块:根据智能体输出的权重,对各个LLM的输出进行加权平均,得到最终的集成结果。5) 奖励函数:根据最终集成结果的质量,计算奖励值,用于训练强化学习智能体。
关键创新:RLAE最重要的技术创新点在于将强化学习引入LLM集成,实现了权重的动态调整。与传统的固定权重集成方法相比,RLAE能够根据输入上下文和模型状态自适应地调整权重,从而更好地利用各个模型的优势。此外,RLAE还支持单智能体和多智能体强化学习算法,进一步提升了集成的灵活性和性能。
关键设计:RLAE的关键设计包括:1) 状态表示:如何有效地编码输入上下文和LLM的中间生成状态,以便智能体能够准确地判断各个模型的优势。2) 奖励函数:如何设计一个能够准确反映集成结果质量的奖励函数,以便智能体能够有效地学习。3) 强化学习算法:选择合适的强化学习算法,例如PPO或MAPPO,以训练智能体。4) 权重归一化:对智能体输出的权重进行归一化处理,以保证权重的合理性。
🖼️ 关键图片
📊 实验亮点
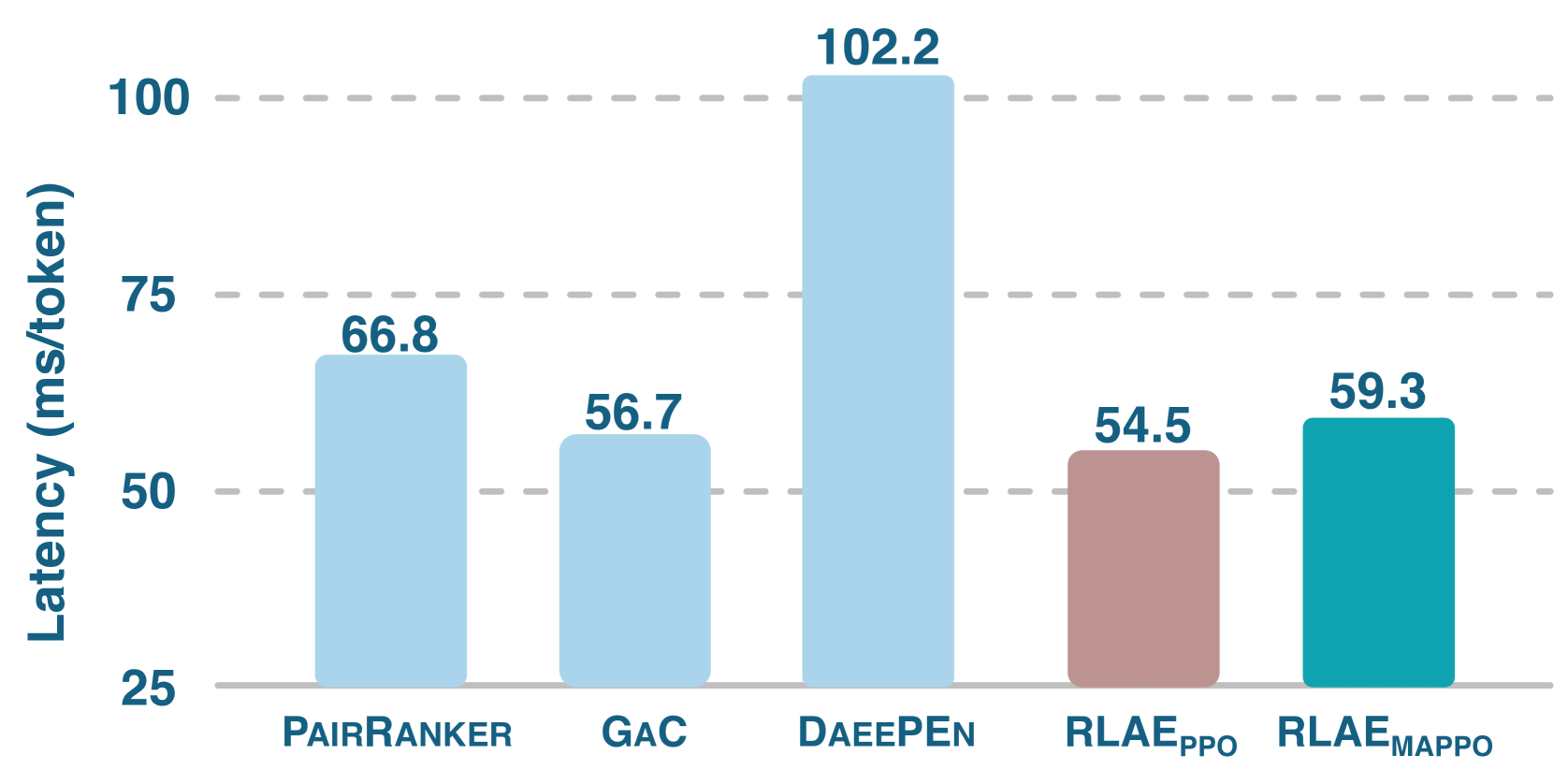
RLAE在多个任务上进行了广泛的评估,结果表明其性能显著优于现有的集成方法。例如,在某个文本生成任务上,RLAE的准确率比最佳基线提高了3.3%。此外,RLAE还表现出卓越的泛化能力,无需重新训练即可应用于不同的任务。同时,RLAE还实现了更低的时间延迟,使其更适用于实际应用。
🎯 应用场景
RLAE可广泛应用于各种需要利用LLM的任务中,例如文本生成、问答系统、机器翻译等。通过集成多个LLM的优势,RLAE能够提升任务的性能和鲁棒性。此外,RLAE的动态权重调整机制使其能够适应不同的应用场景和数据分布,具有很强的泛化能力。未来,RLAE有望成为LLM应用的重要组成部分,推动人工智能技术的发展。
📄 摘要(原文)
Ensembling large language models (LLMs) can effectively combine diverse strengths of different models, offering a promising approach to enhance performance across various tasks. However, existing methods typically rely on fixed weighting strategies that fail to adapt to the dynamic, context-dependent characteristics of LLM capabilities. In this work, we propose Reinforcement Learning-Assisted Ensemble for LLMs (RLAE), a novel framework that reformulates LLM ensemble through the lens of a Markov Decision Process (MDP). Our approach introduces a RL agent that dynamically adjusts ensemble weights by considering both input context and intermediate generation states, with the agent being trained using rewards that directly correspond to the quality of final outputs. We implement RLAE using both single-agent and multi-agent reinforcement learning algorithms ($\text{RLAE}\text{PPO}$ and $\text{RLAE}\text{MAPPO}$ ), demonstrating substantial improvements over conventional ensemble methods. Extensive evaluations on a diverse set of tasks show that RLAE outperforms existing approaches by up to $3.3\%$ accuracy points, offering a more effective framework for LLM ensembling. Furthermore, our method exhibits superior generalization capabilities across different tasks without the need for retraining, while simultaneously achieving lower time latency.