CLARIFY: Contrastive Preference Reinforcement Learning for Untangling Ambiguous Queries
作者: Ni Mu, Hao Hu, Xiao Hu, Yiqin Yang, Bo Xu, Qing-Shan Jia
分类: cs.LG
发布日期: 2025-05-31 (更新: 2025-06-10)
备注: ICML 2025
💡 一句话要点
提出CLARIFY,通过对比偏好学习解决强化学习中模糊查询问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 偏好强化学习 对比学习 模糊查询 轨迹嵌入 主动学习
📋 核心要点
- PbRL依赖人类偏好进行学习,但人类对相似片段的偏好标注存在模糊性,降低了学习效率。
- CLARIFY通过对比学习构建轨迹嵌入空间,将可区分的片段分离,从而选择更明确的查询。
- 实验表明,CLARIFY在模拟和真实人类反馈中均优于现有方法,并能学习到有意义的轨迹嵌入。
📝 摘要(中文)
基于偏好的强化学习(PbRL)通过从人类偏好比较中推断奖励函数,绕过了显式奖励工程,从而更好地与人类意图对齐。然而,人类常常难以标记相似片段之间的明确偏好,降低了标签效率并限制了PbRL的实际应用。为了解决这个问题,我们提出了一种离线PbRL方法:对比学习用于解决模糊反馈(CLARIFY),它学习一个包含偏好信息的轨迹嵌入空间,确保清晰区分的片段间隔开,从而促进更明确查询的选择。大量实验表明,在非理想教师和真实人类反馈设置中,CLARIFY优于基线方法。我们的方法不仅选择更明确的查询,而且学习有意义的轨迹嵌入。
🔬 方法详解
问题定义:论文旨在解决基于偏好的强化学习(PbRL)中,由于人类偏好标注的模糊性导致学习效率低下的问题。现有方法在面对相似轨迹片段时,难以获得明确的偏好标签,这使得奖励函数的学习变得困难,限制了PbRL在实际场景中的应用。
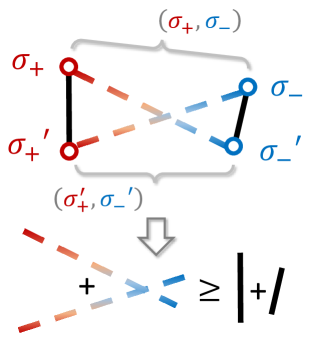
核心思路:CLARIFY的核心思路是通过对比学习,构建一个轨迹嵌入空间,使得具有明显偏好差异的轨迹片段在嵌入空间中距离较远,而相似的片段距离较近。这样,在选择查询时,可以选择那些在嵌入空间中距离其他片段较远的片段,从而获得更明确的偏好反馈。
技术框架:CLARIFY是一个离线PbRL方法,其整体框架包含以下几个主要步骤:1) 收集离线轨迹数据;2) 使用对比学习训练轨迹嵌入模型,该模型将轨迹片段映射到嵌入空间;3) 使用训练好的嵌入模型,选择信息量最大的轨迹片段进行偏好查询;4) 根据人类的偏好反馈,更新奖励函数;5) 使用更新后的奖励函数,训练强化学习策略。
关键创新:CLARIFY的关键创新在于使用对比学习来解决PbRL中的模糊查询问题。与传统的查询选择方法不同,CLARIFY不是直接基于轨迹的特征来选择查询,而是通过学习一个轨迹嵌入空间,将轨迹的偏好信息编码到嵌入向量中。这种方法能够更有效地识别出具有明确偏好的轨迹片段,从而提高学习效率。
关键设计:CLARIFY的关键设计包括:1) 对比损失函数的设计,用于训练轨迹嵌入模型。该损失函数的目标是使得具有相同偏好的轨迹片段在嵌入空间中距离较近,而具有不同偏好的轨迹片段距离较远;2) 查询选择策略的设计,用于选择信息量最大的轨迹片段进行偏好查询。该策略基于轨迹片段在嵌入空间中的距离,选择那些距离其他片段较远的片段。
🖼️ 关键图片

📊 实验亮点
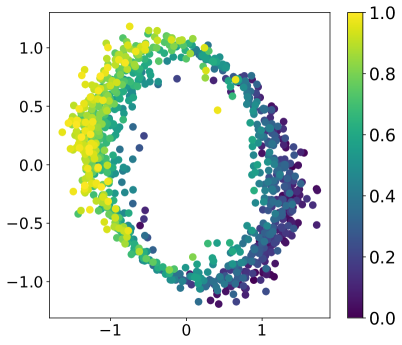
实验结果表明,CLARIFY在非理想教师和真实人类反馈设置中均优于基线方法。在模拟实验中,CLARIFY能够显著提高奖励函数的学习效率,并获得更高的策略性能。在真实人类反馈实验中,CLARIFY能够选择更明确的查询,并获得更准确的偏好标签。此外,实验还表明,CLARIFY学习到的轨迹嵌入具有良好的泛化能力,可以用于其他下游任务。
🎯 应用场景
CLARIFY方法可应用于各种需要人类偏好反馈的强化学习任务中,例如机器人控制、游戏AI、推荐系统等。通过减少对明确偏好标签的需求,该方法降低了人工标注成本,提高了学习效率,使得PbRL更容易应用于实际场景。未来,该方法可以扩展到在线学习场景,并与其他主动学习方法相结合,进一步提高学习效率。
📄 摘要(原文)
Preference-based reinforcement learning (PbRL) bypasses explicit reward engineering by inferring reward functions from human preference comparisons, enabling better alignment with human intentions. However, humans often struggle to label a clear preference between similar segments, reducing label efficiency and limiting PbRL's real-world applicability. To address this, we propose an offline PbRL method: Contrastive LeArning for ResolvIng Ambiguous Feedback (CLARIFY), which learns a trajectory embedding space that incorporates preference information, ensuring clearly distinguished segments are spaced apart, thus facilitating the selection of more unambiguous queries. Extensive experiments demonstrate that CLARIFY outperforms baselines in both non-ideal teachers and real human feedback settings. Our approach not only selects more distinguished queries but also learns meaningful trajectory embeddings.