Power-of-Two (PoT) Weights in Large Language Models (LLMs)
作者: Mahmoud Elgenedy
分类: eess.SP, cs.LG
发布日期: 2025-05-31
💡 一句话要点
提出基于二次幂量化的LLM压缩方法,降低计算复杂度
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 量化 二次幂 模型压缩 边缘计算
📋 核心要点
- 大型语言模型参数规模急剧增长,给边缘设备的部署带来巨大挑战,存储和计算资源受限。
- 论文提出使用二次幂(PoT)量化方法,将权重和Transformer表量化为2的幂次,从而将乘法运算转化为位移运算。
- 实验结果表明,在Nano-GPT和GPT-2模型上,使用4-6位PoT量化,交叉熵损失仅有轻微下降,验证了该方法的可行性。
📝 摘要(中文)
由于模型参数的大量增加,神经网络的复杂度正在迅速增加。特别是在大型语言模型(LLM)中,模型参数的数量在过去几年中呈指数增长,例如,从GPT2的15亿个参数到GPT3的1750亿个参数。这对实现提出了重大挑战,特别是对于内存和处理能力非常有限的边缘设备。在这项工作中,我们研究了使用特殊类型的量化(二次幂(PoT))来降低LLM的复杂度,用于线性层权重和Transformer表。PoT不仅提供了内存减少,更重要的是通过将乘法转换为位移来提供显著的计算减少。我们获得了在莎士比亚数据集上使用Nano-GPT实现的PoT量化的初步结果。然后,我们将结果扩展到1.24亿参数的GPT-2模型。PoT量化结果显示出非常有希望的结果,交叉熵损失的降低约为[1.3-0.88],用[4-6]位来表示功率水平。
🔬 方法详解
问题定义:大型语言模型(LLM)的参数规模日益增长,导致计算和存储成本显著增加,尤其是在资源受限的边缘设备上部署时,模型大小和计算复杂度成为主要瓶颈。现有的量化方法虽然可以降低模型大小,但往往无法有效降低计算复杂度,或者精度损失较大。
核心思路:论文的核心思路是将LLM中的权重和Transformer表量化为2的幂次(Power-of-Two, PoT)。由于2的幂次的乘法运算可以通过简单的位移操作实现,因此可以显著降低计算复杂度,同时减少内存占用。这种方法旨在在精度损失可接受的范围内,大幅提升LLM的推理速度和效率。
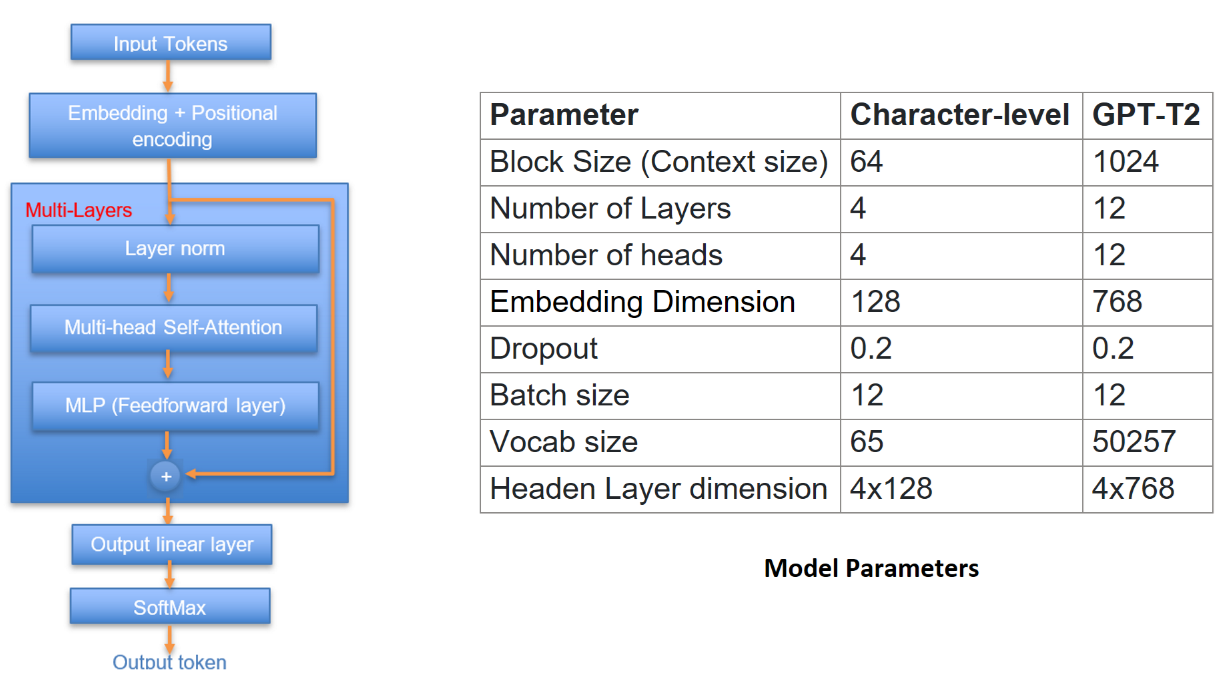
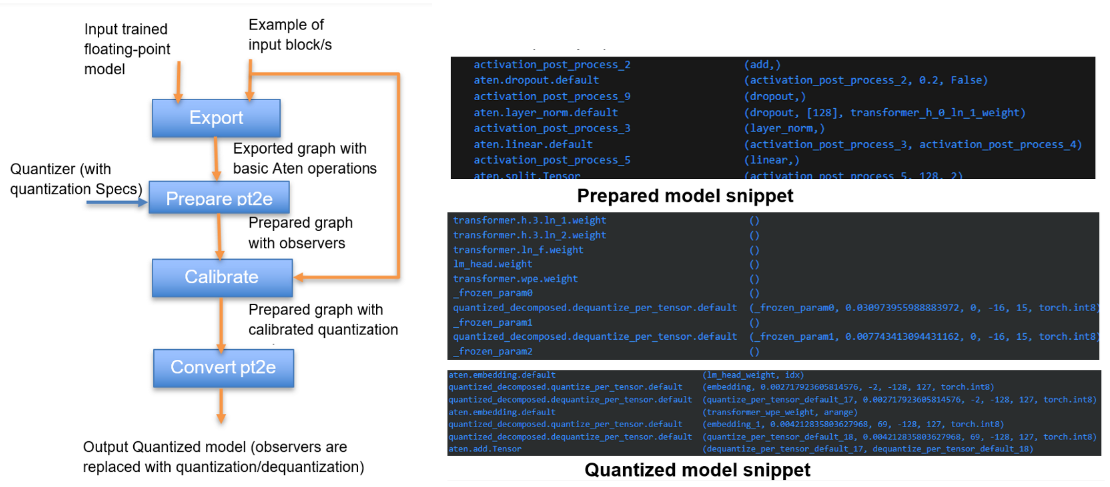
技术框架:该方法主要包含以下几个阶段:1) 选择需要量化的层,通常是线性层的权重和Transformer表;2) 将这些权重和表量化为2的幂次,即每个权重值都近似为2的某个整数次幂;3) 使用量化后的模型进行推理,将乘法运算替换为位移操作;4) 评估量化后的模型性能,如交叉熵损失,并根据需要调整量化参数。
关键创新:该方法最重要的创新点在于利用了2的幂次的特殊性质,将乘法运算转化为位移操作,从而在硬件层面实现了计算加速。与传统的量化方法相比,PoT量化不仅降低了模型大小,更重要的是降低了计算复杂度,这对于边缘设备的部署至关重要。
关键设计:关键设计包括:1) 确定合适的量化位数,需要在精度和计算复杂度之间进行权衡;2) 选择合适的量化策略,例如对称量化或非对称量化;3) 设计有效的训练或微调策略,以减少量化带来的精度损失。论文中使用了交叉熵损失作为评估指标,并探索了不同的量化位数(4-6位)对模型性能的影响。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在Nano-GPT模型上,使用4-6位PoT量化后,交叉熵损失仅有轻微下降。在1.24亿参数的GPT-2模型上,交叉熵损失的降低约为[1.3-0.88],表明该方法在保持较高精度的同时,能够有效降低LLM的计算复杂度。这些结果验证了PoT量化在LLM压缩和加速方面的潜力。
🎯 应用场景
该研究成果可应用于各种需要部署大型语言模型的边缘设备,例如智能手机、物联网设备和自动驾驶汽车。通过降低LLM的计算复杂度和内存占用,可以使这些设备能够运行更强大的AI模型,从而提升用户体验和应用性能。此外,该方法还可以用于加速LLM的训练和推理,降低云计算成本。
📄 摘要(原文)
Complexity of Neural Networks is increasing rapidly due to the massive increase in model parameters. Specifically, in Large Language Models (LLMs), the number of model parameters has grown exponentially in the past few years, for example, from 1.5 billion parameters in GPT2 to 175 billion in GPT3. This raises a significant challenge for implementation, especially for Edge devices where memory and processing power are very limited. In this work, we investigate reducing LLM complexity with special type of quantization, power of two (PoT), for linear layers weights and transformer tables. PoT not only provides memory reduction but more importantly provides significant computational reduction through converting multiplication to bit shifting. We obtained preliminary results of PoT quantization on Nano-GPT implementation using Shakespeare dataset. We then extended results to 124-M GPT-2 model. The PoT quantization results are shown to be very promising with cross entropy loss degradation $\approx$[1.3-0.88] with number of bits range [4-6] to represent power levels.