LittleBit: Ultra Low-Bit Quantization via Latent Factorization
作者: Banseok Lee, Dongkyu Kim, Youngcheon You, Youngmin Kim
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-05-30 (更新: 2026-01-15)
备注: Accepted to NeurIPS 2025. Banseok Lee and Dongkyu Kim contributed equally
🔗 代码/项目: GITHUB
💡 一句话要点
LittleBit:通过潜在因子分解实现超低比特量化,显著压缩大语言模型。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 超低比特量化 大语言模型压缩 潜在因子分解 量化感知训练 低秩近似
📋 核心要点
- 现有大语言模型部署面临高内存和计算成本,亚1比特量化性能下降明显,限制了其在资源受限环境中的应用。
- LittleBit通过潜在因子分解将权重表示为低秩形式,并进行二值化,同时引入多尺度补偿机制缓解信息损失。
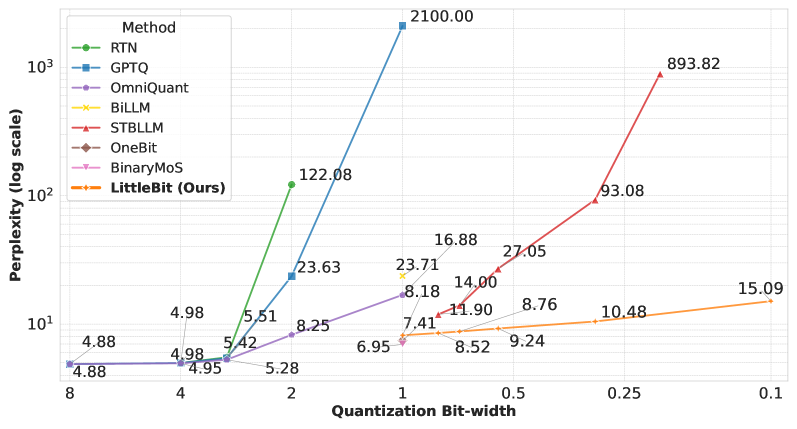
- 实验表明,LittleBit在亚1比特量化上优于现有方法,例如在Llama2-7B上0.1 BPW的性能超过了现有方法0.7 BPW。
📝 摘要(中文)
部署大型语言模型(LLMs)常常面临巨大的内存和计算成本挑战。量化提供了一种解决方案,但低于1比特范围内的性能下降仍然特别困难。本文介绍了一种用于极端LLM压缩的新方法LittleBit。它针对每权重0.1比特(BPW)的级别,实现了近31倍的内存缩减,例如将Llama2-13B压缩到0.9 GB以下。LittleBit使用潜在矩阵分解以低秩形式表示权重,随后对这些因子进行二值化。为了抵消这种极端精度带来的信息损失,它集成了一种多尺度补偿机制,包括行、列和一个额外的潜在维度,用于学习每个秩的重要性。两个关键贡献实现了有效的训练:用于量化感知训练(QAT)初始化的双符号-值独立分解(Dual-SVID)和用于减轻误差的集成残差补偿。大量实验证实了LittleBit在亚1比特量化方面的优越性:例如,其在Llama2-7B上的0.1 BPW性能超过了领先方法的0.7 BPW。LittleBit建立了一种新的、可行的尺寸-性能权衡,在内核级别实现了比FP16快11.6倍的潜在加速,并使强大的LLM在资源受限的环境中变得实用。我们的代码可以在https://github.com/SamsungLabs/LittleBit找到。
🔬 方法详解
问题定义:论文旨在解决大语言模型在资源受限设备上部署的问题,具体来说,就是如何在极低的比特数(例如0.1 BPW)下对模型进行量化,同时尽可能地保持模型的性能。现有方法在亚1比特量化时性能下降严重,难以达到可用的精度。
核心思路:论文的核心思路是将权重矩阵分解为低秩矩阵,然后对这些低秩矩阵进行二值化。这样做的好处是可以显著减少参数量,同时通过低秩分解保留了权重矩阵的主要信息。为了弥补二值化带来的信息损失,论文还引入了多尺度补偿机制。
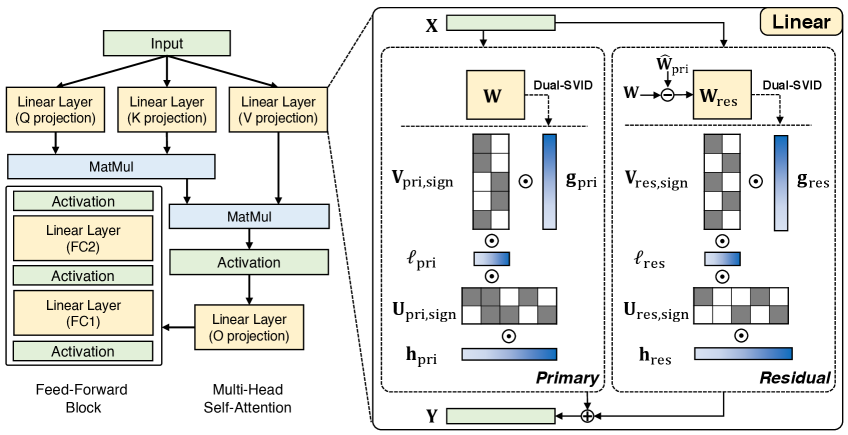
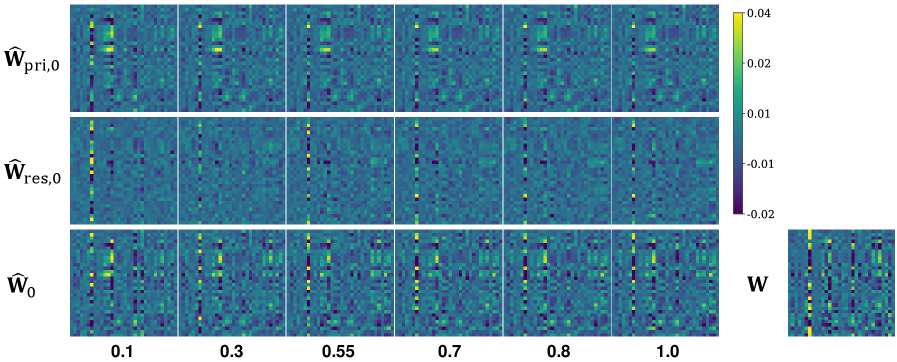
技术框架:LittleBit的整体框架包括以下几个主要步骤:1. 潜在因子分解:将权重矩阵分解为两个或多个低秩矩阵的乘积。2. 二值化:对分解后的低秩矩阵进行二值化。3. 多尺度补偿:引入行、列和潜在维度补偿机制,以减轻二值化带来的信息损失。4. 量化感知训练:使用Dual-SVID初始化和集成残差补偿进行量化感知训练。
关键创新:论文的关键创新在于以下几个方面:1. 潜在因子分解与二值化结合:将潜在因子分解与二值化相结合,实现了极低的比特量化。2. 多尺度补偿机制:引入行、列和潜在维度补偿机制,有效缓解了二值化带来的信息损失。3. Dual-SVID初始化:提出Dual-SVID初始化方法,加速了量化感知训练的收敛。4. 集成残差补偿:通过集成残差补偿,进一步提升了量化模型的精度。
关键设计:1. Dual-SVID初始化:通过将权重矩阵分解为符号矩阵和值矩阵,并分别进行初始化,加速了量化感知训练的收敛。2. 多尺度补偿:通过学习行、列和潜在维度的补偿因子,缓解了二值化带来的信息损失。3. 损失函数:使用量化损失和重构损失的加权和作为损失函数,优化量化模型的性能。
🖼️ 关键图片
📊 实验亮点
LittleBit在Llama2-7B模型上实现了0.1 BPW的量化,性能超过了现有最佳方法在0.7 BPW下的表现。在内核级别,LittleBit实现了比FP16快11.6倍的潜在加速。此外,LittleBit可以将Llama2-13B模型压缩到0.9GB以下,使得在资源受限设备上部署大型语言模型成为可能。
🎯 应用场景
LittleBit技术可广泛应用于资源受限的边缘设备,例如移动设备、嵌入式系统和物联网设备,使得这些设备能够运行大型语言模型,从而实现本地化的智能服务,例如离线翻译、智能助手和个性化推荐。该技术还有助于降低云计算成本,使得更多用户能够负担得起高性能的AI服务。
📄 摘要(原文)
Deploying large language models (LLMs) often faces challenges from substantial memory and computational costs. Quantization offers a solution, yet performance degradation in the sub-1-bit regime remains particularly difficult. This paper introduces LittleBit, a novel method for extreme LLM compression. It targets levels like 0.1 bits per weight (BPW), achieving nearly 31$\times$ memory reduction, e.g., Llama2-13B to under 0.9 GB. LittleBit represents weights in a low-rank form using latent matrix factorization, subsequently binarizing these factors. To counteract information loss from this extreme precision, it integrates a multi-scale compensation mechanism. This includes row, column, and an additional latent dimension that learns per-rank importance. Two key contributions enable effective training: Dual Sign-Value-Independent Decomposition (Dual-SVID) for quantization-aware training (QAT) initialization, and integrated Residual Compensation to mitigate errors. Extensive experiments confirm LittleBit's superiority in sub-1-bit quantization: e.g., its 0.1 BPW performance on Llama2-7B surpasses the leading method's 0.7 BPW. LittleBit establishes a new, viable size-performance trade-off--unlocking a potential 11.6$\times$ speedup over FP16 at the kernel level--and makes powerful LLMs practical for resource-constrained environments. Our code can be found at https://github.com/SamsungLabs/LittleBit.