Intercept Cancer: Cancer Pre-Screening with Large Scale Healthcare Foundation Models
作者: Liwen Sun, Hao-Ren Yao, Gary Gao, Ophir Frieder, Chenyan Xiong
分类: cs.LG, cs.CL
发布日期: 2025-05-30 (更新: 2025-09-26)
💡 一句话要点
CATCH-FM:利用大规模医疗健康基础模型进行癌症预筛查
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 癌症预筛查 医疗健康基础模型 电子健康记录 风险预测 少样本学习
📋 核心要点
- 现有癌症筛查方法昂贵且具侵入性,全球普及率低,导致大量潜在可挽救生命损失。
- CATCH-FM利用大规模EHR数据预训练医疗基础模型,仅凭历史医疗记录进行癌症风险预筛查。
- 实验表明,CATCH-FM在癌症风险预测中优于传统模型和LLM,并在胰腺癌预测中达到SOTA。
📝 摘要(中文)
癌症筛查能够早期发现癌症,从而挽救生命。然而,现有的筛查技术需要昂贵且具有侵入性的医疗程序,并且并非全球普及,导致许多本可以挽救的生命逝去。我们提出了CATCH-FM,即利用医疗健康基础模型早期发现癌症,这是一种癌症预筛查方法,仅基于患者的历史医疗记录识别高风险患者,以便进行进一步筛查。我们利用数百万份电子健康记录(EHR),建立了在医疗代码序列上预训练的EHR基础模型的缩放定律,预训练了高达24亿参数的计算最优基础模型,并在临床医生策划的癌症风险预测队列上对其进行微调。在包含三万名患者的回顾性评估中,CATCH-FM表现出强大的有效性,在99%特异性截断下,预测首次癌症风险的敏感性达到50%,并且在AUPRC方面优于基于特征的树模型以及通用和医疗LLM高达20%。尽管存在显著的人口统计学、医疗保健系统和EHR编码差异,CATCH-FM在EHRSHOT少样本排行榜上实现了最先进的胰腺癌风险预测,优于使用现场患者数据预训练的EHR基础模型。我们的分析表明了CATCH-FM在各种患者分布中的鲁棒性、在ICD代码空间中操作的优势以及其捕获非平凡癌症风险因素的能力。我们的代码将开源。
🔬 方法详解
问题定义:论文旨在解决癌症早期筛查成本高、普及率低的问题。现有方法依赖昂贵的医疗程序,无法大规模应用。因此,需要一种低成本、非侵入性的方法来识别高风险人群,以便进行进一步的诊断筛查。
核心思路:论文的核心思路是利用大规模电子健康记录(EHR)数据,预训练医疗领域的基础模型,然后利用这些模型进行癌症风险预测。通过学习EHR数据中的模式,模型可以识别出与癌症风险相关的因素,从而实现早期预筛查。
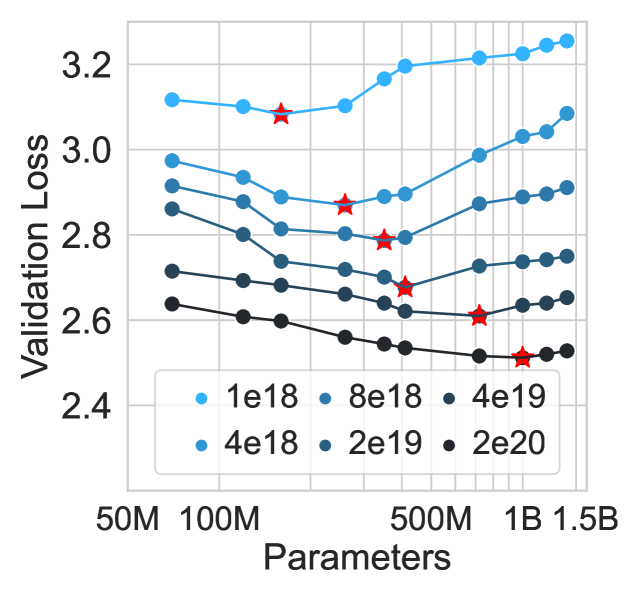
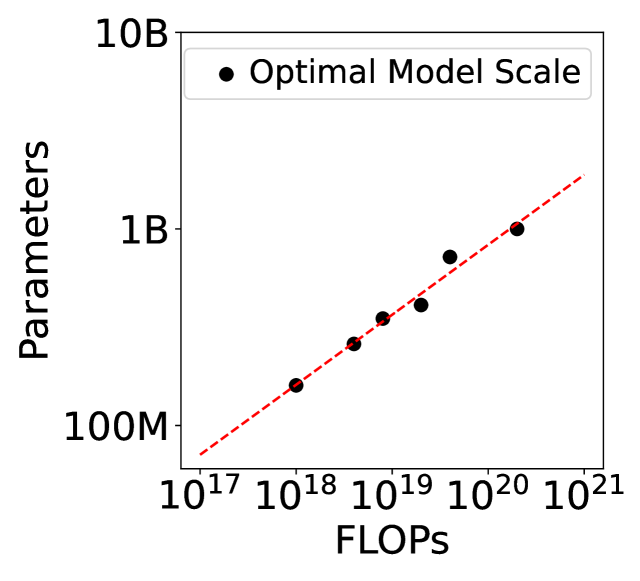
技术框架:CATCH-FM的整体框架包括以下几个阶段:1) 数据预处理:收集和清洗大规模EHR数据,将其转换为模型可以处理的格式,例如医疗代码序列。2) 基础模型预训练:在医疗代码序列上预训练大规模Transformer模型,学习医疗领域的知识表示。论文探索了不同模型规模的缩放规律,选择了计算最优的模型规模。3) 风险预测微调:在临床医生标注的癌症风险预测数据集上微调预训练的基础模型,使其能够预测个体患癌症的风险。4) 模型评估:在回顾性数据集上评估模型的性能,并与其他基线方法进行比较。
关键创新:论文的关键创新在于:1) 大规模EHR基础模型:利用大规模EHR数据预训练医疗领域的基础模型,这使得模型能够学习到丰富的医疗知识,从而提高癌症风险预测的准确性。2) ICD代码空间操作:直接在ICD代码空间中进行建模,避免了特征工程的复杂性,并能够更好地捕捉医疗事件之间的关系。3) 少样本学习能力:CATCH-FM在少样本学习任务中表现出色,表明其具有良好的泛化能力。
关键设计:论文的关键设计包括:1) 模型规模选择:通过实验确定了计算最优的模型规模,避免了过度参数化。2) 预训练目标:使用masked language modeling (MLM) 作为预训练目标,使得模型能够学习到医疗代码之间的上下文关系。3) 微调策略:使用交叉熵损失函数进行微调,并采用适当的正则化技术防止过拟合。
🖼️ 关键图片

📊 实验亮点
CATCH-FM在回顾性评估中表现出强大的有效性,在99%特异性截断下,预测首次癌症风险的敏感性达到50%,并且在AUPRC方面优于基于特征的树模型以及通用和医疗LLM高达20%。在EHRSHOT少样本排行榜上实现了最先进的胰腺癌风险预测,优于使用现场患者数据预训练的EHR基础模型。
🎯 应用场景
CATCH-FM可应用于大规模人群的癌症风险预筛查,尤其是在医疗资源有限的地区。通过识别高风险个体,可以有针对性地进行进一步诊断,提高癌症的早期检出率,降低医疗成本,并最终提高患者的生存率。该技术还可用于药物研发和临床试验设计,加速新疗法的开发。
📄 摘要(原文)
Cancer screening, leading to early detection, saves lives. Unfortunately, existing screening techniques require expensive and intrusive medical procedures, not globally available, resulting in too many lost would-be-saved lives. We present CATCH-FM, CATch Cancer early with Healthcare Foundation Models, a cancer pre-screening methodology that identifies high-risk patients for further screening solely based on their historical medical records. With millions of electronic healthcare records (EHR), we establish the scaling law of EHR foundation models pretrained on medical code sequences, pretrain compute-optimal foundation models of up to 2.4 billion parameters, and finetune them on clinician-curated cancer risk prediction cohorts. In our retrospective evaluation comprising of thirty thousand patients, CATCH-FM achieves strong efficacy, with 50% sensitivity in predicting first cancer risks at 99% specificity cutoff, and outperforming feature-based tree models and both general and medical LLMs by up to 20% AUPRC. Despite significant demographic, healthcare system, and EHR coding differences, CATCH-FM achieves state-of-the-art pancreatic cancer risk prediction on the EHRSHOT few-shot leaderboard, outperforming EHR foundation models pretrained using on-site patient data. Our analysis demonstrates the robustness of CATCH-FM in various patient distributions, the benefits of operating in the ICD code space, and its ability to capture non-trivial cancer risk factors. Our code will be open-sourced.