When GPT Spills the Tea: Comprehensive Assessment of Knowledge File Leakage in GPTs
作者: Xinyue Shen, Yun Shen, Michael Backes, Yang Zhang
分类: cs.CR, cs.LG
发布日期: 2025-05-30
💡 一句话要点
揭示GPT知识文件泄露风险:提出全面评估框架并发现多种泄露途径
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识文件泄露 大型语言模型 GPT安全 数据安全态势管理 风险评估
📋 核心要点
- 现有研究表明GPTs存在知识文件泄露风险,但缺乏对所有潜在泄露途径的全面评估,尤其是在复杂数据流环境下。
- 该论文借鉴数据安全态势管理(DSPM)的思想,构建了一套新的工作流程,用于全面评估GPTs中的知识文件泄露风险。
- 实验识别出五种泄露途径,并发现激活Code Interpreter会导致严重的权限提升漏洞,攻击者可以高成功率下载原始知识文件。
📝 摘要(中文)
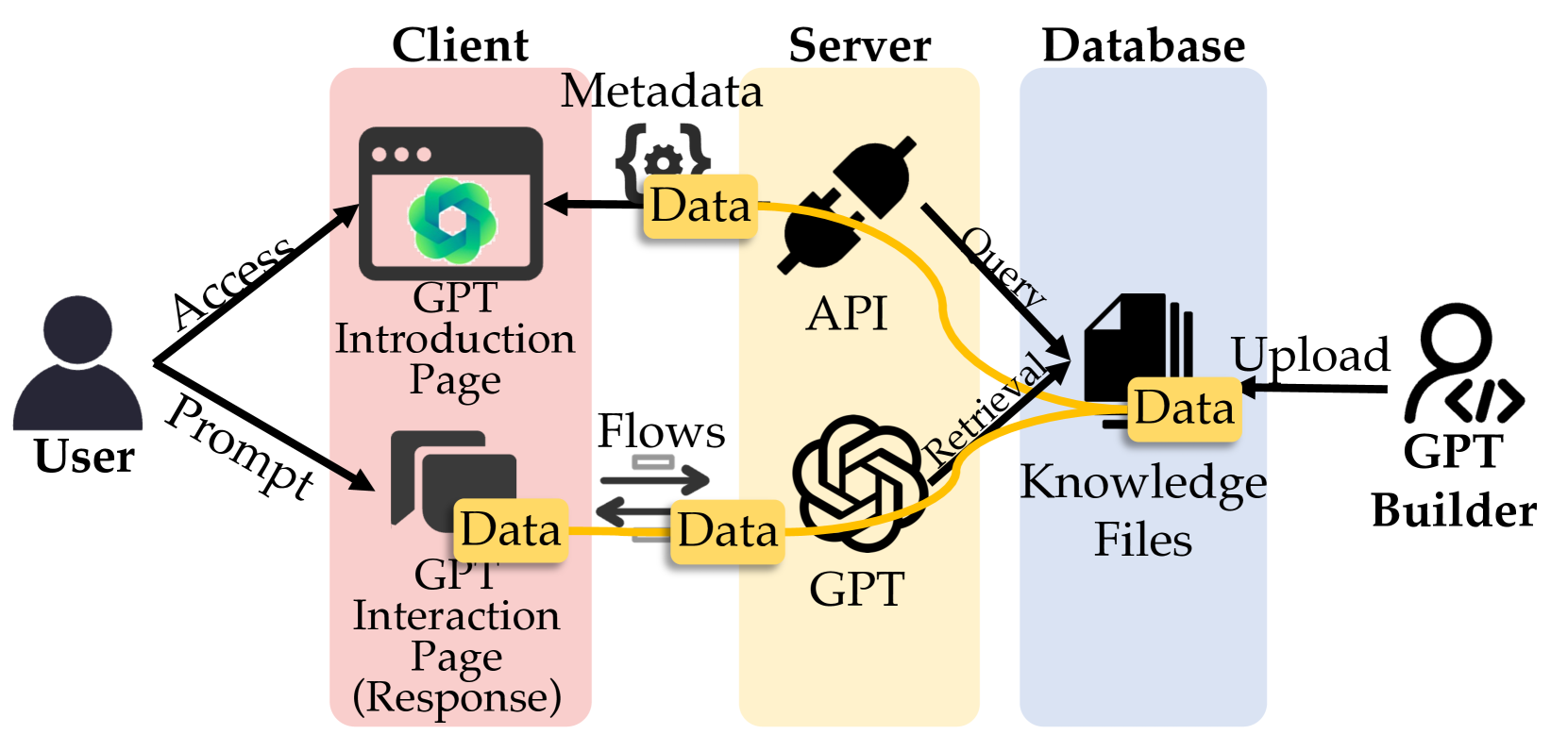
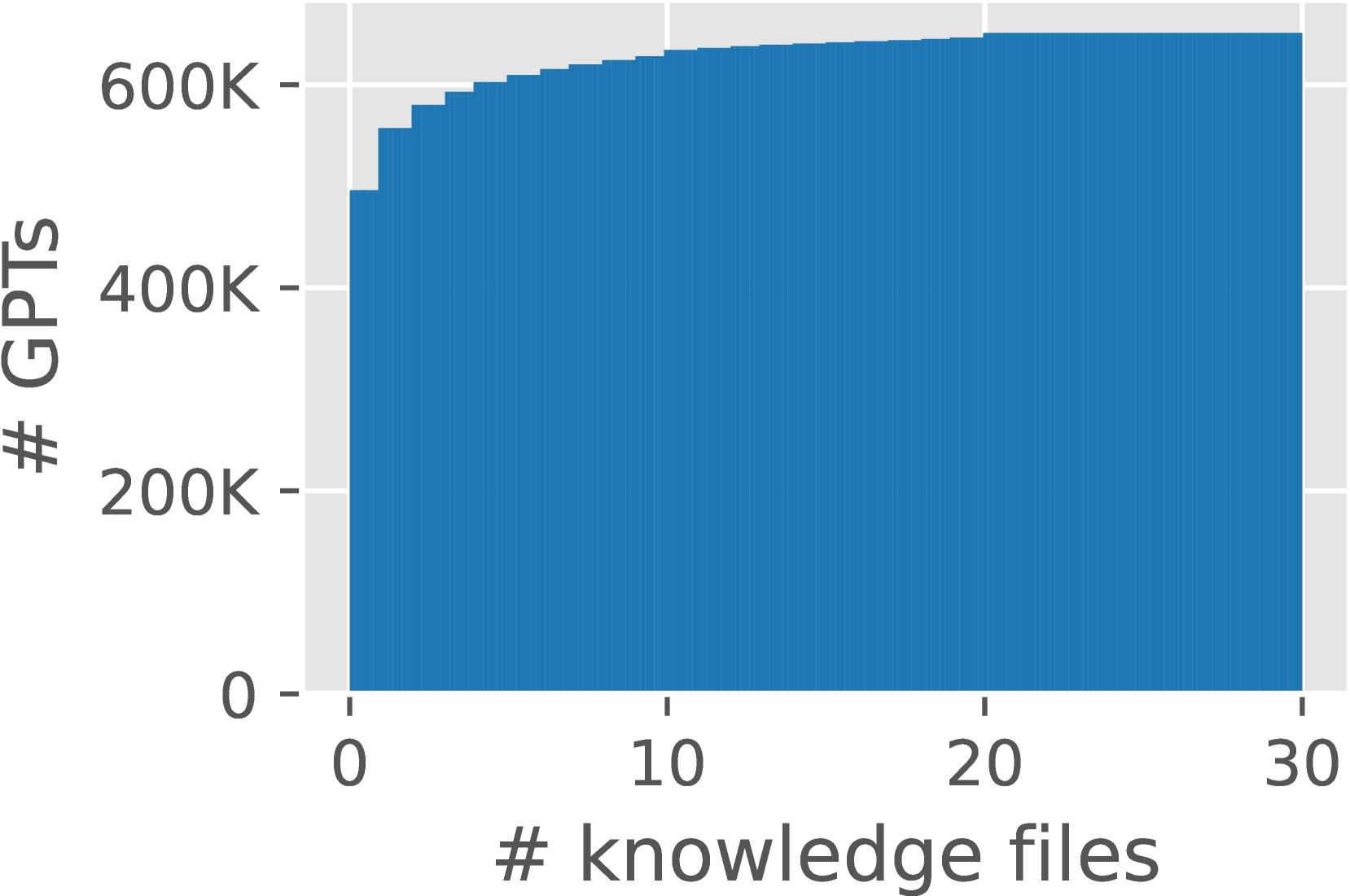
知识文件被广泛应用于大型语言模型(LLM)代理,如GPTs,以提高响应质量。然而,知识文件潜在的泄露风险日益增长。现有研究表明,对抗性提示可以诱导GPTs泄露知识文件内容。但鉴于GPTs中跨客户端、服务器和数据库的复杂数据流,是否存在其他泄露途径仍不确定。本文提出了一种受数据安全态势管理(DSPM)启发的全新工作流程,对知识文件泄露进行了全面的风险评估。通过分析651,022个GPT元数据、11,820个数据流和1,466个响应,我们识别出五种泄露途径:元数据、GPT初始化、检索、沙盒执行环境和提示。这些途径使攻击者能够提取敏感的知识文件数据,如标题、内容、类型和大小。值得注意的是,激活内置工具Code Interpreter会导致权限提升漏洞,使攻击者能够直接下载原始知识文件,成功率高达95.95%。进一步分析显示,28.80%的泄露文件受版权保护,包括主要出版商的数字副本和上市公司的内部资料。最后,我们为GPT构建者和平台提供商提供了可行的解决方案,以确保GPT数据供应链的安全。
🔬 方法详解
问题定义:该论文旨在解决GPTs中知识文件泄露的风险评估问题。现有方法主要集中于通过对抗性提示诱导泄露,但忽略了其他潜在的泄露途径,并且缺乏系统性的评估框架。现有的研究没有充分考虑GPTs复杂的数据流,包括客户端、服务器和数据库之间的交互,这使得风险评估不够全面。
核心思路:论文的核心思路是借鉴数据安全态势管理(DSPM)的理念,构建一个全面的风险评估框架,以识别和评估GPTs中所有可能的知识文件泄露途径。通过分析GPTs的元数据、数据流和响应,可以更全面地了解泄露风险,并为GPT构建者和平台提供商提供可行的安全建议。
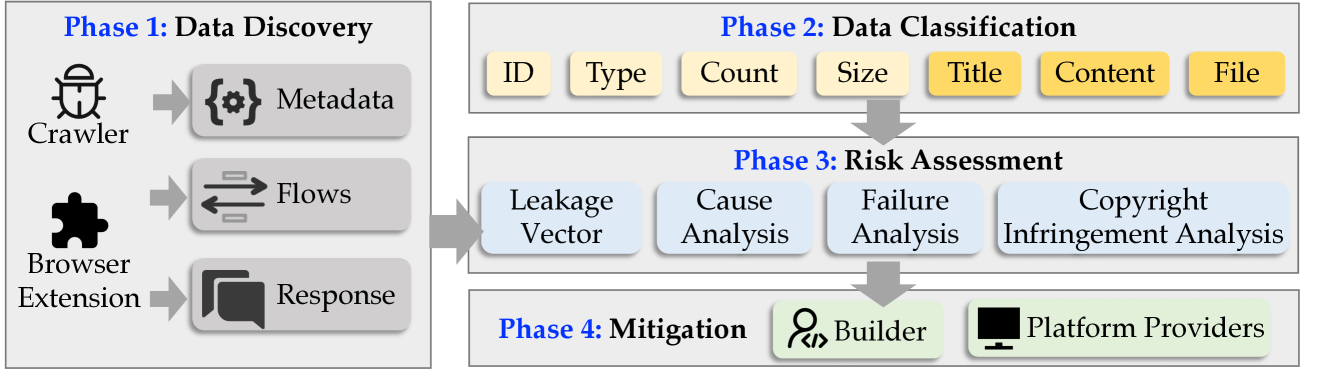
技术框架:该论文提出的风险评估框架主要包括以下几个阶段:1) 数据收集:收集GPTs的元数据、数据流和响应数据。2) 泄露途径识别:通过分析收集到的数据,识别潜在的知识文件泄露途径。3) 漏洞验证:针对识别出的泄露途径,设计实验验证其可行性。4) 风险评估:评估不同泄露途径的风险程度,包括泄露数据的敏感性和泄露的难易程度。5) 安全建议:为GPT构建者和平台提供商提供可行的安全建议,以降低知识文件泄露的风险。
关键创新:该论文的关键创新在于:1) 提出了一个受DSPM启发的全面风险评估框架,可以系统地识别和评估GPTs中的知识文件泄露风险。2) 识别出五种新的泄露途径,包括元数据、GPT初始化、检索、沙盒执行环境和提示。3) 发现激活Code Interpreter会导致严重的权限提升漏洞,攻击者可以高成功率下载原始知识文件。
关键设计:论文的关键设计包括:1) 使用大规模的GPT元数据、数据流和响应数据进行分析,保证了评估的全面性和可靠性。2) 设计了针对不同泄露途径的实验,验证了其可行性。3) 对泄露数据的敏感性和泄露的难易程度进行了评估,为风险评估提供了量化的指标。4) 针对GPT构建者和平台提供商,提出了具体可行的安全建议。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该研究识别出五种知识文件泄露途径,并发现激活Code Interpreter会导致95.95%的原始文件下载成功率。进一步分析显示,28.80%的泄露文件受版权保护,包括主要出版商的数字副本和上市公司的内部资料。这些结果突显了GPTs中知识文件泄露的严重性。
🎯 应用场景
该研究成果可应用于提升大型语言模型代理(如GPTs)的安全性,保护用户上传的知识文件不被泄露。通过识别和修复潜在的泄露途径,可以增强用户对GPTs平台的信任,促进其在企业和个人领域的广泛应用。此外,该研究提出的风险评估框架也可用于评估其他LLM应用的安全风险。
📄 摘要(原文)
Knowledge files have been widely used in large language model (LLM) agents, such as GPTs, to improve response quality. However, concerns about the potential leakage of knowledge files have grown significantly. Existing studies demonstrate that adversarial prompts can induce GPTs to leak knowledge file content. Yet, it remains uncertain whether additional leakage vectors exist, particularly given the complex data flows across clients, servers, and databases in GPTs. In this paper, we present a comprehensive risk assessment of knowledge file leakage, leveraging a novel workflow inspired by Data Security Posture Management (DSPM). Through the analysis of 651,022 GPT metadata, 11,820 flows, and 1,466 responses, we identify five leakage vectors: metadata, GPT initialization, retrieval, sandboxed execution environments, and prompts. These vectors enable adversaries to extract sensitive knowledge file data such as titles, content, types, and sizes. Notably, the activation of the built-in tool Code Interpreter leads to a privilege escalation vulnerability, enabling adversaries to directly download original knowledge files with a 95.95% success rate. Further analysis reveals that 28.80% of leaked files are copyrighted, including digital copies from major publishers and internal materials from a listed company. In the end, we provide actionable solutions for GPT builders and platform providers to secure the GPT data supply chain.