Breakpoint: Scalable evaluation of system-level reasoning in LLM code agents
作者: Kaivalya Hariharan, Uzay Girit, Atticus Wang, Jacob Andreas
分类: cs.LG
发布日期: 2025-05-30
备注: 21 pages, 14 figures
💡 一句话要点
Breakpoint:通过对抗性代码损坏,可扩展地评估LLM代码智能体的系统级推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码修复 系统级推理 LLM评估 对抗性测试 代码复杂度
📋 核心要点
- 现有LLM基准测试主要评估局部推理,长视距基准依赖人工标注,难以扩展和调整难度。
- Breakpoint通过对抗性地破坏真实代码库中的函数,自动生成代码修复任务,从而评估LLM的系统级推理能力。
- 实验表明,Breakpoint可以有效控制任务难度,并揭示了现有模型在复杂系统级推理任务上的不足。
📝 摘要(中文)
大型语言模型(LLM)的基准测试主要评估短视距、局部推理能力。现有的长视距套件(如SWE-bench)依赖于手动整理的问题,因此扩展或调整难度需要昂贵的人力,且评估很快饱和。然而,许多实际任务,如软件工程或科学研究,要求智能体快速理解和动态操作新的复杂结构;评估这些能力需要构建大量且多样的问题集供智能体解决。我们引入Breakpoint,一种基准测试方法,通过对抗性地破坏真实软件仓库中的函数来自动生成代码修复任务。Breakpoint系统地控制任务难度,通过两个明确的维度:局部推理(以代码复杂性指标如循环复杂度为特征)和系统级推理(以调用图中心性和同时损坏的相互依赖函数的数量为特征)。在超过900个生成任务的实验中,我们证明了我们的方法可以扩展到任意难度,最先进模型的成功率从最简单任务的55%下降到最难任务的0%。
🔬 方法详解
问题定义:现有LLM基准测试在评估系统级推理能力方面存在不足。SWE-bench等长视距基准依赖人工标注,扩展性和难度控制受限,无法满足评估LLM在复杂软件工程任务中推理能力的需求。现有方法难以生成大量多样且难度可控的测试用例。
核心思路:Breakpoint的核心思路是通过对抗性地修改真实软件仓库中的函数来自动生成代码修复任务。通过控制代码复杂度和函数间的依赖关系,可以系统地调整任务的难度,从而评估LLM在不同难度下的系统级推理能力。这种方法避免了人工标注的成本,并能够生成大量多样化的测试用例。
技术框架:Breakpoint的整体流程包括以下几个步骤:1) 从真实软件仓库中选择函数;2) 对选定的函数进行对抗性修改,引入错误;3) 根据代码复杂度和函数依赖关系计算任务难度;4) 将修改后的代码作为输入,要求LLM进行修复;5) 评估LLM的修复结果。其中,对抗性修改策略和难度评估是关键环节。
关键创新:Breakpoint最重要的创新在于其自动生成代码修复任务的能力,以及对任务难度的系统性控制。与现有方法相比,Breakpoint无需人工标注,可以生成大量多样化的测试用例,并且能够根据代码复杂度和函数依赖关系精确控制任务难度。这使得Breakpoint能够更全面、更有效地评估LLM的系统级推理能力。
关键设计:Breakpoint的关键设计包括:1) 对抗性修改策略,例如引入语法错误、逻辑错误等;2) 难度评估指标,包括代码复杂度(如循环复杂度)和函数依赖关系(如调用图中心性、同时损坏的函数数量);3) 评估指标,例如修复成功率、修复时间等。这些设计共同保证了Breakpoint能够生成高质量、难度可控的代码修复任务,并准确评估LLM的性能。
🖼️ 关键图片

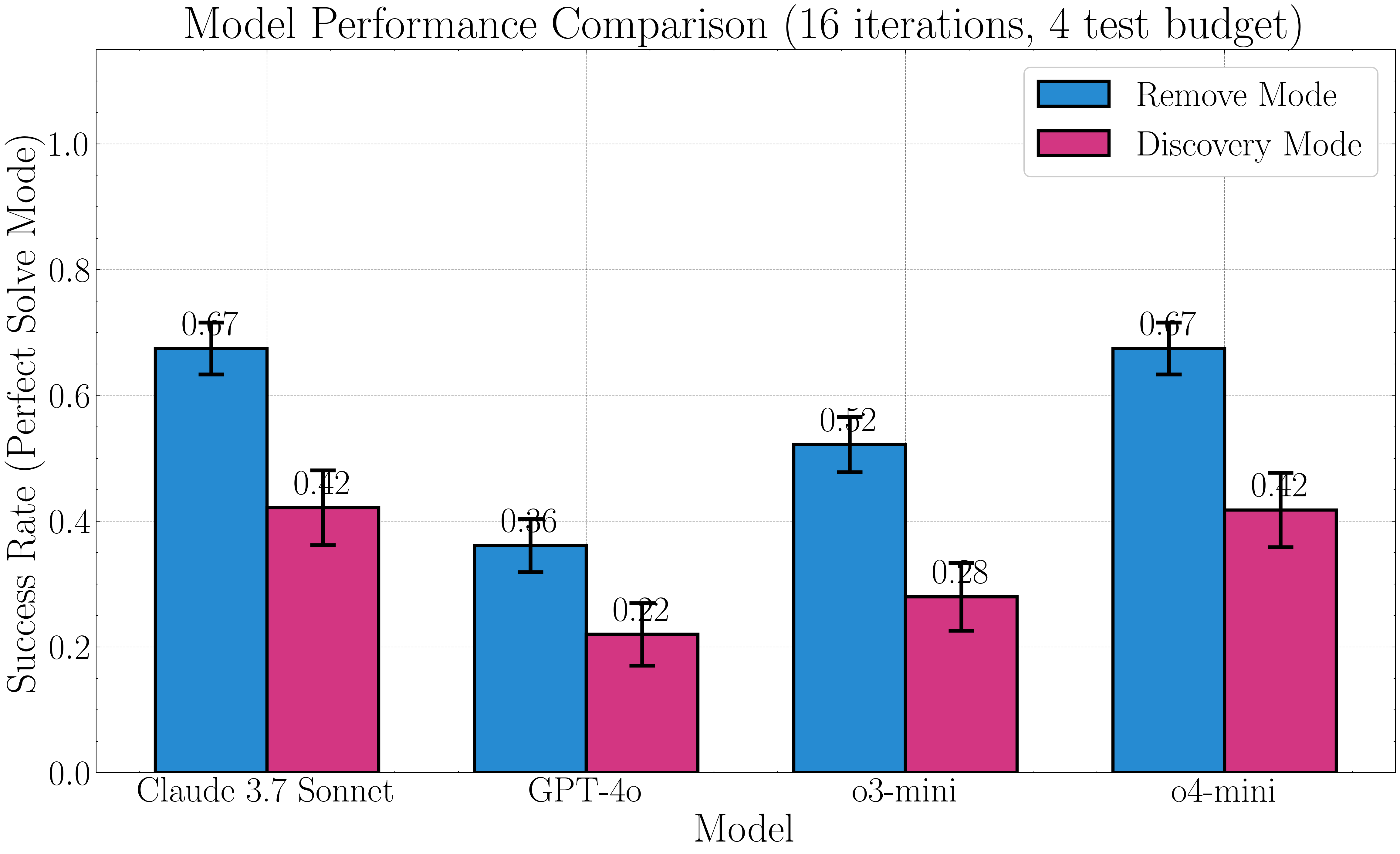

📊 实验亮点
实验结果表明,Breakpoint能够有效控制任务难度,最先进模型的成功率从最简单任务的55%下降到最难任务的0%。这表明现有模型在复杂系统级推理任务上仍存在较大差距。Breakpoint为评估和提升LLM的系统级推理能力提供了一个有效的平台。
🎯 应用场景
Breakpoint可用于评估和提升LLM在软件工程、科学研究等领域的应用能力。通过Breakpoint,可以更好地了解LLM在处理复杂代码和系统级推理方面的能力,从而指导模型改进和应用开发。此外,Breakpoint还可以用于自动化代码修复、代码生成等任务,提高软件开发的效率和质量。
📄 摘要(原文)
Benchmarks for large language models (LLMs) have predominantly assessed short-horizon, localized reasoning. Existing long-horizon suites (e.g. SWE-bench) rely on manually curated issues, so expanding or tuning difficulty demands expensive human effort and evaluations quickly saturate. However, many real-world tasks, such as software engineering or scientific research, require agents to rapidly comprehend and manipulate novel, complex structures dynamically; evaluating these capabilities requires the ability to construct large and varied sets of problems for agents to solve. We introduce Breakpoint, a benchmarking methodology that automatically generates code-repair tasks by adversarially corrupting functions within real-world software repositories. Breakpoint systematically controls task difficulty along two clear dimensions: local reasoning (characterized by code complexity metrics such as cyclomatic complexity) and system-level reasoning (characterized by call-graph centrality and the number of simultaneously corrupted interdependent functions). In experiments across more than 900 generated tasks we demonstrate that our methodology can scale to arbitrary difficulty, with state-of-the-art models' success rates ranging from 55% on the easiest tasks down to 0% on the hardest.