On Designing Diffusion Autoencoders for Efficient Generation and Representation Learning
作者: Magdalena Proszewska, Nikolay Malkin, N. Siddharth
分类: cs.LG
发布日期: 2025-05-30
备注: 21 pages, 10 tables, 15 figures
💡 一句话要点
提出DMZ:一种结合扩散自编码器优势的高效生成与表征学习框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 扩散模型 扩散自编码器 生成模型 表征学习 领域迁移
📋 核心要点
- 扩散自编码器在生成任务中依赖于高质量的潜在变量建模,但现有方法在建模和采样方面存在挑战。
- 论文提出DMZ模型,通过特定的设计决策,结合了扩散自编码器和学习前向噪声过程模型的优点。
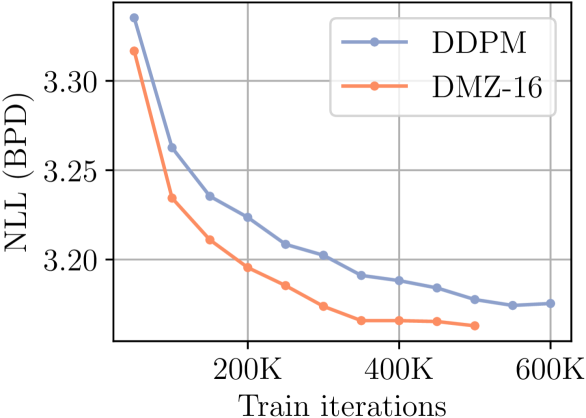
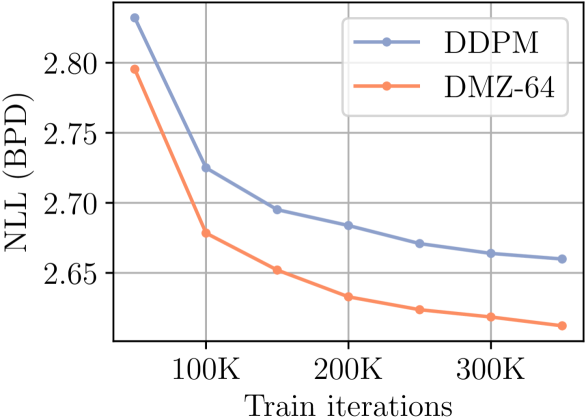
- DMZ模型在下游任务中表现出有效的表征能力,并能以更少的去噪步骤实现更高效的建模和生成。
📝 摘要(中文)
扩散自编码器(DAs)是扩散生成模型的变体,它使用输入相关的潜在变量来捕获表征,并结合扩散过程。这些表征在不同程度上可用于下游分类、可控生成和插值等任务。然而,DAs的生成性能严重依赖于潜在变量的建模和采样质量。改进生成建模也是另一类扩散模型(学习其前向噪声过程的模型)的主要目标。虽然它们能有效地以输入相关的方式调整噪声过程,但必须满足从扩散过程的终端条件导出的额外约束。本文将这两类模型联系起来,表明DA框架中的某些设计决策(潜在变量选择、条件方法等)——导致一个我们称之为DMZ的模型——使我们能够获得两全其美:在包括领域迁移在内的下游任务中评估的有效表征,以及与标准DMs相比,以更少的去噪步骤实现更有效的建模和生成。
🔬 方法详解
问题定义:论文旨在解决扩散自编码器在生成建模时对潜在变量建模和采样质量的高度依赖问题。现有的扩散自编码器在生成性能上受限于潜在变量的建模能力,而学习前向噪声过程的扩散模型虽然能自适应调整噪声过程,但需要满足额外的约束条件。
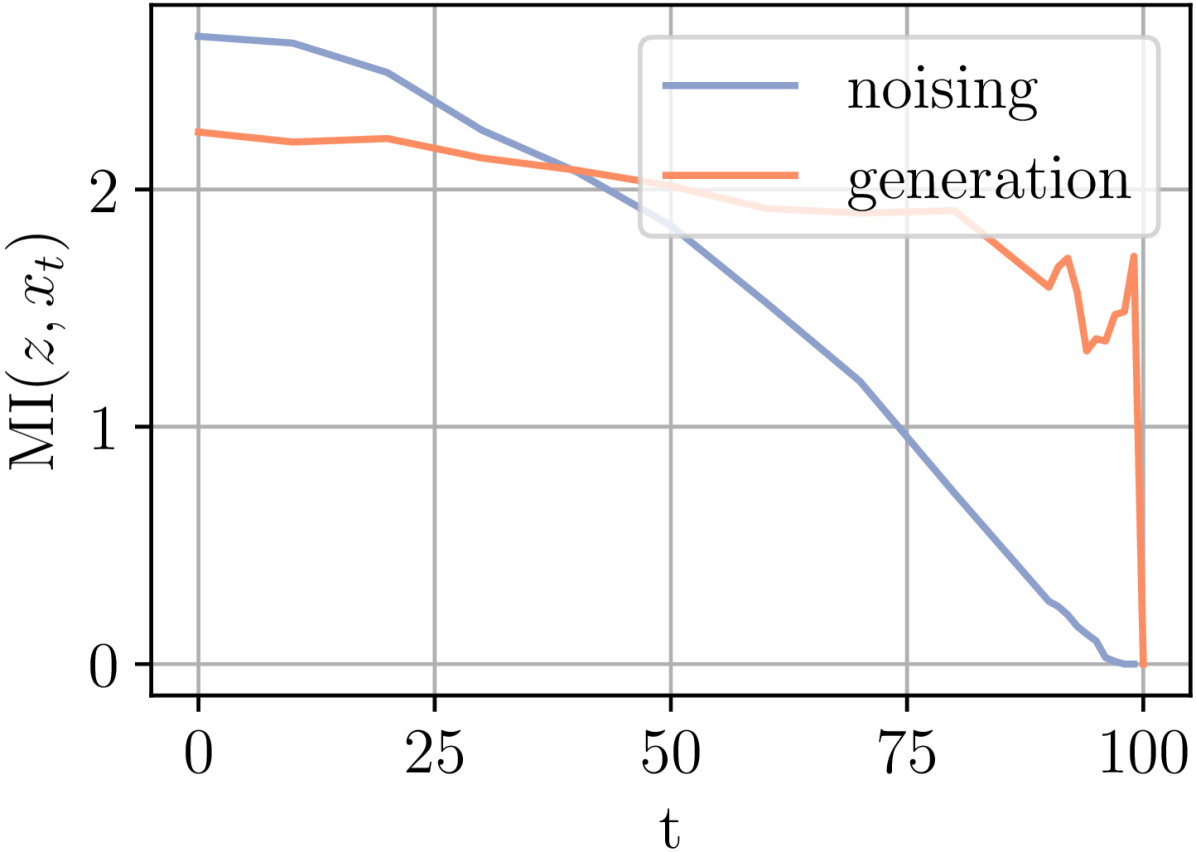
核心思路:论文的核心思路是将扩散自编码器和学习前向噪声过程的扩散模型结合起来,通过特定的设计决策,使得模型既能学习到有效的表征,又能实现高效的生成。具体来说,通过精心选择潜在变量、条件方法等,使得模型能够同时受益于两类模型的优点。
技术框架:论文提出的DMZ模型基于扩散自编码器的框架,包含编码器、扩散过程和解码器三个主要部分。编码器将输入映射到潜在空间,扩散过程逐步向潜在变量添加噪声,解码器则从噪声中逐步恢复原始输入。关键在于对潜在变量的选择和条件方法的改进,使得模型能够更好地学习到输入相关的表征。
关键创新:论文的关键创新在于将扩散自编码器和学习前向噪声过程的扩散模型联系起来,并提出了一种新的模型DMZ,该模型通过特定的设计决策,能够同时实现有效的表征学习和高效的生成。这种结合不同类型扩散模型优势的思路是该论文的主要创新点。
关键设计:论文的关键设计包括:潜在变量的选择,可能采用了更易于建模的潜在空间;条件方法,可能使用了更有效的条件机制,例如自适应的噪声调度策略;损失函数,可能结合了表征学习和生成任务的损失函数,以平衡模型的性能。具体的网络结构和参数设置在论文中应该有详细描述,但摘要中未明确提及。
🖼️ 关键图片
📊 实验亮点
论文提出的DMZ模型在下游任务中表现出有效的表征能力,并且能够以更少的去噪步骤实现更高效的建模和生成。具体的性能数据和对比基线需要在论文中查找,摘要中未提供详细的实验结果。
🎯 应用场景
该研究成果可应用于图像生成、图像编辑、数据增强、领域迁移等领域。通过学习高效的表征,可以提升下游任务的性能,例如图像分类、目标检测等。此外,该方法还可以用于生成具有特定属性的图像,实现可控生成。未来,该研究有望推动生成模型在更多实际场景中的应用。
📄 摘要(原文)
Diffusion autoencoders (DAs) are variants of diffusion generative models that use an input-dependent latent variable to capture representations alongside the diffusion process. These representations, to varying extents, can be used for tasks such as downstream classification, controllable generation, and interpolation. However, the generative performance of DAs relies heavily on how well the latent variables can be modelled and subsequently sampled from. Better generative modelling is also the primary goal of another class of diffusion models -- those that learn their forward (noising) process. While effective at adjusting the noise process in an input-dependent manner, they must satisfy additional constraints derived from the terminal conditions of the diffusion process. Here, we draw a connection between these two classes of models and show that certain design decisions (latent variable choice, conditioning method, etc.) in the DA framework -- leading to a model we term DMZ -- allow us to obtain the best of both worlds: effective representations as evaluated on downstream tasks, including domain transfer, as well as more efficient modelling and generation with fewer denoising steps compared to standard DMs.