HELM: Hyperbolic Large Language Models via Mixture-of-Curvature Experts
作者: Neil He, Rishabh Anand, Hiren Madhu, Ali Maatouk, Smita Krishnaswamy, Leandros Tassiulas, Menglin Yang, Rex Ying
分类: cs.LG, cs.AI
发布日期: 2025-05-30 (更新: 2025-11-06)
💡 一句话要点
提出HELM:基于混合曲率专家模型的双曲空间大型语言模型,提升文本几何结构建模能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 双曲空间 混合曲率专家 几何深度学习 自然语言处理
📋 核心要点
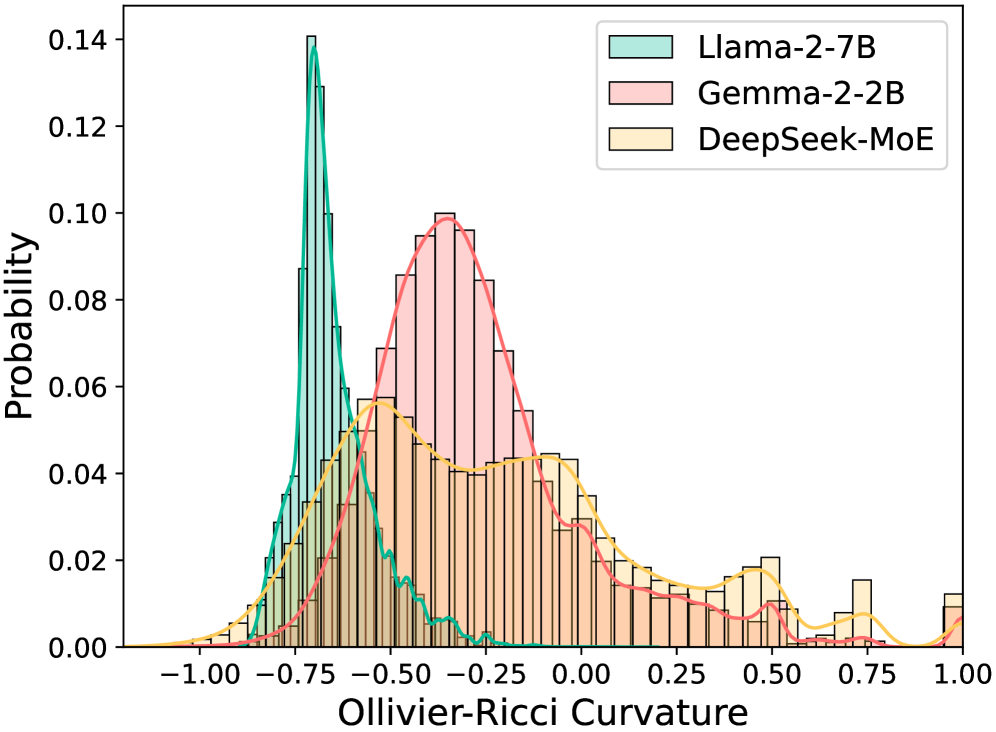
- 现有大型语言模型在处理自然语言的内在语义层次和几何结构方面存在不足,主要原因是它们依赖于欧几里得空间操作。
- HELM通过在双曲空间中构建大型语言模型,并引入混合曲率专家模型,从而更好地捕捉文本的底层几何结构。
- 实验结果表明,HELM在MMLU和ARC等基准测试中,相比于LLaMA和DeepSeek等模型,性能提升高达4%。
📝 摘要(中文)
大型语言模型(LLM)在各个领域的文本建模任务中取得了巨大成功。然而,自然语言具有内在的语义层次结构和细微的几何结构,由于当前LLM依赖于欧几里得操作,因此无法完全捕捉到这些结构。最近的研究表明,不尊重token嵌入的几何结构会导致训练不稳定和生成能力下降。这些发现表明,转向非欧几里得几何可以更好地使语言模型与文本的底层几何结构对齐。因此,我们提出完全在双曲空间中操作,双曲空间以其广阔、无尺度和低失真特性而闻名。我们因此引入了HELM,一系列双曲大型语言模型,它对基于Transformer的LLM进行了几何上的重新思考,解决了现有双曲LM的表示不灵活性、缺少必要操作以及可扩展性差的问题。此外,我们还引入了一种混合曲率专家模型HELM-MICE,其中每个专家在不同的曲率空间中操作,以编码来自文本的更细粒度的几何结构,以及一个密集模型HELM-D。对于HELM-MICE,我们进一步开发了双曲多头潜在注意力(HMLA),用于高效、减少KV缓存的训练和推理。对于这两种模型,我们开发了旋转位置编码和RMS归一化的基本双曲等价物。我们是第一个训练十亿参数规模的完全双曲LLM的人,并在MMLU和ARC等知名基准上对其进行评估,涵盖STEM问题解决、一般知识和常识推理。我们的结果表明,与LLaMA和DeepSeek中使用的流行的欧几里得架构相比,我们的HELM架构始终如一地获得了高达4%的收益,突出了双曲几何在大规模LM预训练中的有效性和增强的推理能力。
🔬 方法详解
问题定义:现有的大型语言模型主要基于欧几里得空间,无法有效捕捉自然语言中固有的层次结构和几何结构,导致模型在处理复杂推理任务时性能受限。此外,直接在欧几里得空间进行嵌入可能导致训练不稳定和生成能力下降。
核心思路:论文的核心思路是将大型语言模型迁移到双曲空间,利用双曲空间的特性(如广阔性、无尺度性和低失真性)来更好地表示和处理自然语言的几何结构。通过混合曲率专家模型,使不同的专家在不同的曲率空间中操作,从而捕捉更细粒度的几何信息。
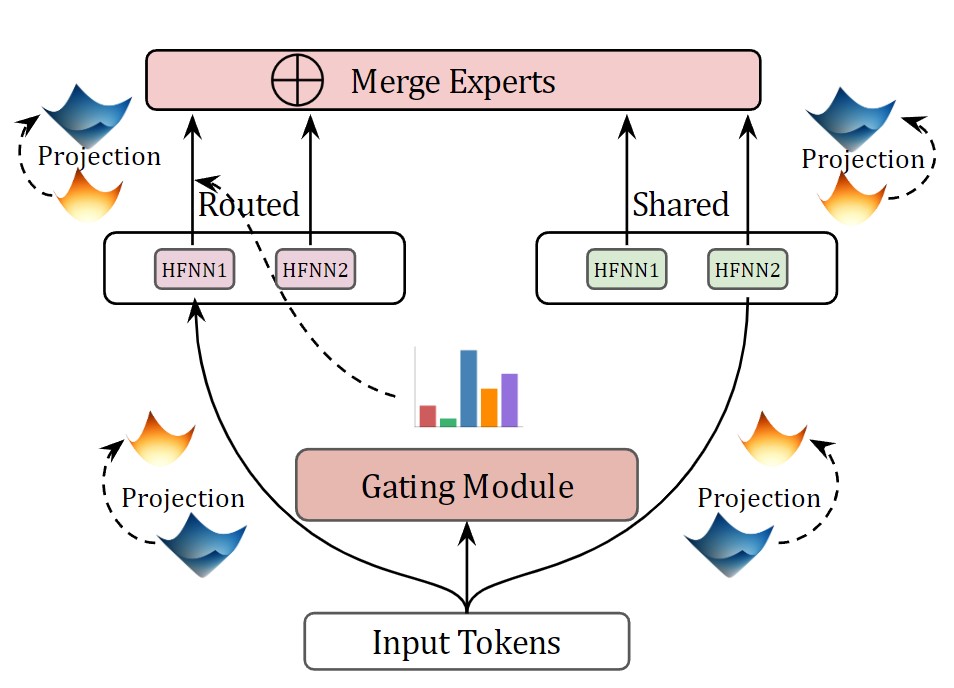
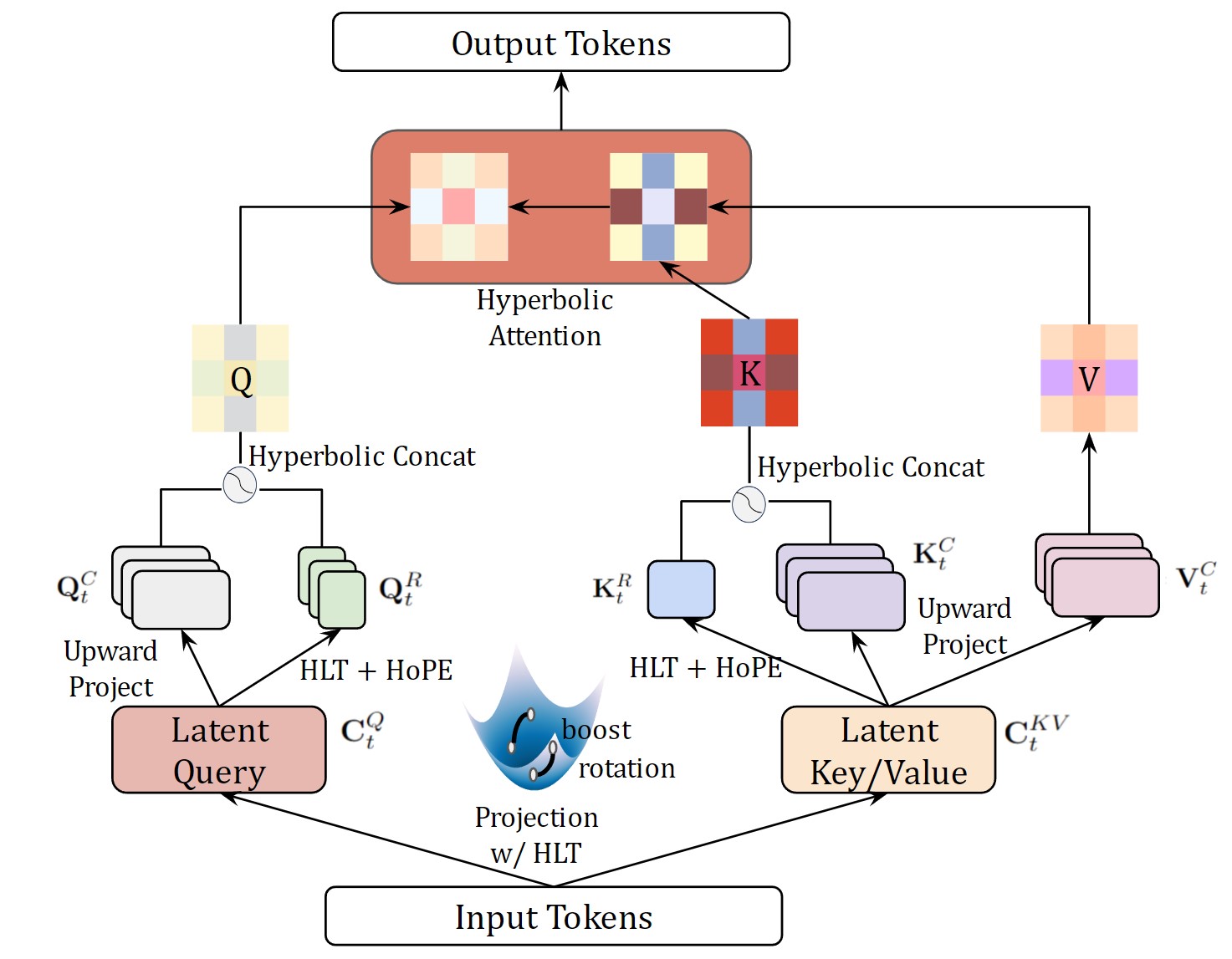
技术框架:HELM包含两个主要模型:HELM-MICE(混合曲率专家模型)和HELM-D(密集模型)。HELM-MICE使用混合曲率专家机制,每个专家在不同的双曲空间中运行。HELM-D是一个在双曲空间中运行的密集模型。两个模型都使用了双曲旋转位置编码和RMS归一化。HELM-MICE还引入了双曲多头潜在注意力(HMLA)机制,以减少KV缓存,提高训练和推理效率。
关键创新:论文的关键创新在于首次提出了完全在双曲空间中运行的大型语言模型,并引入了混合曲率专家机制。HMLA机制也是一个重要的创新,它通过减少KV缓存来提高模型的效率。此外,论文还开发了双曲空间中的旋转位置编码和RMS归一化等关键组件。
关键设计:HELM-MICE的关键设计在于混合曲率专家的选择和路由机制,具体细节未知。HMLA的关键设计在于如何在双曲空间中实现多头注意力,并减少KV缓存。双曲旋转位置编码和RMS归一化的具体实现细节也未知,但它们是保证模型在双曲空间中有效训练和推理的关键。
🖼️ 关键图片
📊 实验亮点
实验结果表明,HELM在MMLU和ARC等基准测试中,相比于流行的欧几里得架构(如LLaMA和DeepSeek),性能提升高达4%。这证明了双曲几何在大规模语言模型预训练中的有效性和增强的推理能力。
🎯 应用场景
HELM的潜在应用领域包括自然语言处理的各个方面,例如文本分类、情感分析、机器翻译、问答系统和文本生成。通过更好地捕捉文本的几何结构,HELM有望在需要复杂推理和理解的任务中取得更好的性能。该研究对于推动下一代大型语言模型的发展具有重要意义。
📄 摘要(原文)
Large language models (LLMs) have shown great success in text modeling tasks across domains. However, natural language exhibits inherent semantic hierarchies and nuanced geometric structure, which current LLMs do not capture completely owing to their reliance on Euclidean operations. Recent studies have also shown that not respecting the geometry of token embeddings leads to training instabilities and degradation of generative capabilities. These findings suggest that shifting to non-Euclidean geometries can better align language models with the underlying geometry of text. We thus propose to operate fully in Hyperbolic space, known for its expansive, scale-free, and low-distortion properties. We thus introduce HELM, a family of HypErbolic Large Language Models, offering a geometric rethinking of the Transformer-based LLM that addresses the representational inflexibility, missing set of necessary operations, and poor scalability of existing hyperbolic LMs. We additionally introduce a Mixture-of-Curvature Experts model, HELM-MICE, where each expert operates in a distinct curvature space to encode more fine-grained geometric structure from text, as well as a dense model, HELM-D. For HELM-MICE, we further develop hyperbolic Multi-Head Latent Attention (HMLA) for efficient, reduced-KV-cache training and inference. For both models, we develop essential hyperbolic equivalents of rotary positional encodings and RMS normalization. We are the first to train fully hyperbolic LLMs at billion-parameter scale, and evaluate them on well-known benchmarks such as MMLU and ARC, spanning STEM problem-solving, general knowledge, and commonsense reasoning. Our results show consistent gains from our HELM architectures -- up to 4% -- over popular Euclidean architectures used in LLaMA and DeepSeek, highlighting the efficacy and enhanced reasoning afforded by hyperbolic geometry in large-scale LM pretraining.