PDE-Transformer: Efficient and Versatile Transformers for Physics Simulations
作者: Benjamin Holzschuh, Qiang Liu, Georg Kohl, Nils Thuerey
分类: cs.LG
发布日期: 2025-05-30
备注: ICML 2025. Code available at https://github.com/tum-pbs/pde-transformer
💡 一句话要点
提出PDE-Transformer,用于高效且通用的物理模拟代理建模。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 物理模拟 Transformer 偏微分方程 代理模型 深度学习 自注意力机制 基础模型
📋 核心要点
- 现有Transformer架构在处理大规模物理模拟时面临可扩展性和通用性挑战。
- PDE-Transformer通过结合扩散Transformer的改进和针对物理模拟的调整,提升了Transformer的性能。
- 实验表明,PDE-Transformer在多种PDE数据集上优于现有Transformer,并在下游任务中表现出色。
📝 摘要(中文)
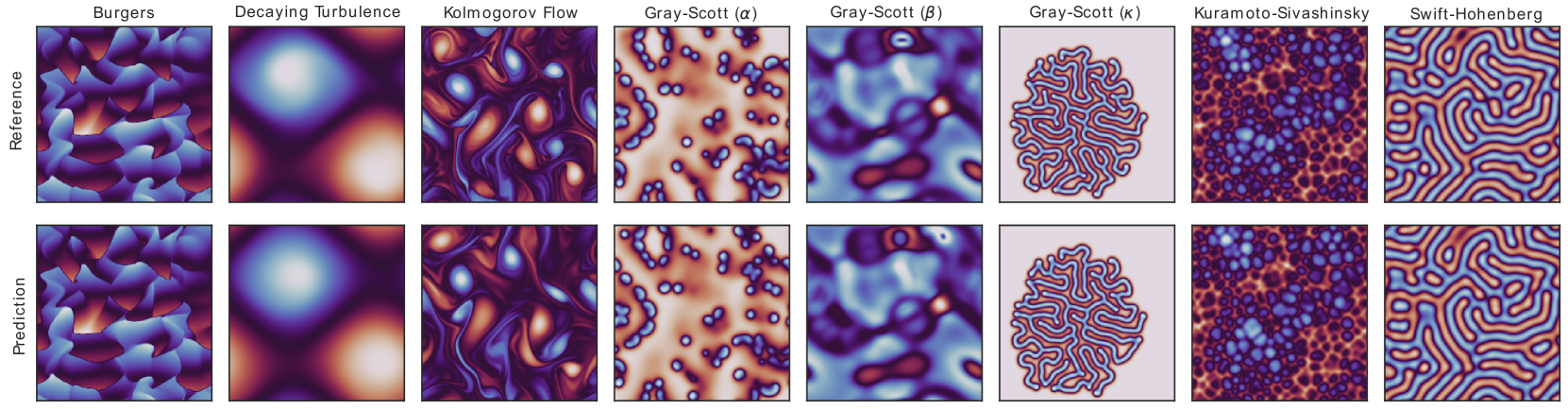
本文介绍了一种改进的基于Transformer的架构PDE-Transformer,用于在规则网格上进行物理模拟的代理建模。我们将扩散Transformer的最新架构改进与针对大规模模拟的调整相结合,从而产生一种更具可扩展性和通用性的通用Transformer架构,该架构可用作构建物理科学中大规模基础模型的骨干。我们证明了我们提出的架构在包含16种不同类型PDE的大型数据集上,优于用于计算机视觉的最先进的Transformer架构。我们建议将不同的物理通道单独嵌入为时空token,这些token通过通道自注意力进行交互。这有助于在同时学习多种类型的PDE时,保持token的一致信息密度。我们证明,与从头开始训练相比,我们预训练的模型在几个具有挑战性的下游任务上实现了更高的性能,并且也优于其他用于物理模拟的基础模型架构。
🔬 方法详解
问题定义:现有Transformer架构在应用于大规模物理模拟时,面临着计算效率和泛化能力的挑战。特别是,如何有效地处理多通道物理场数据,并在不同类型的偏微分方程(PDE)之间共享知识,是一个重要的难题。现有的方法可能无法很好地保持token的信息密度,导致在学习多种PDE时性能下降。
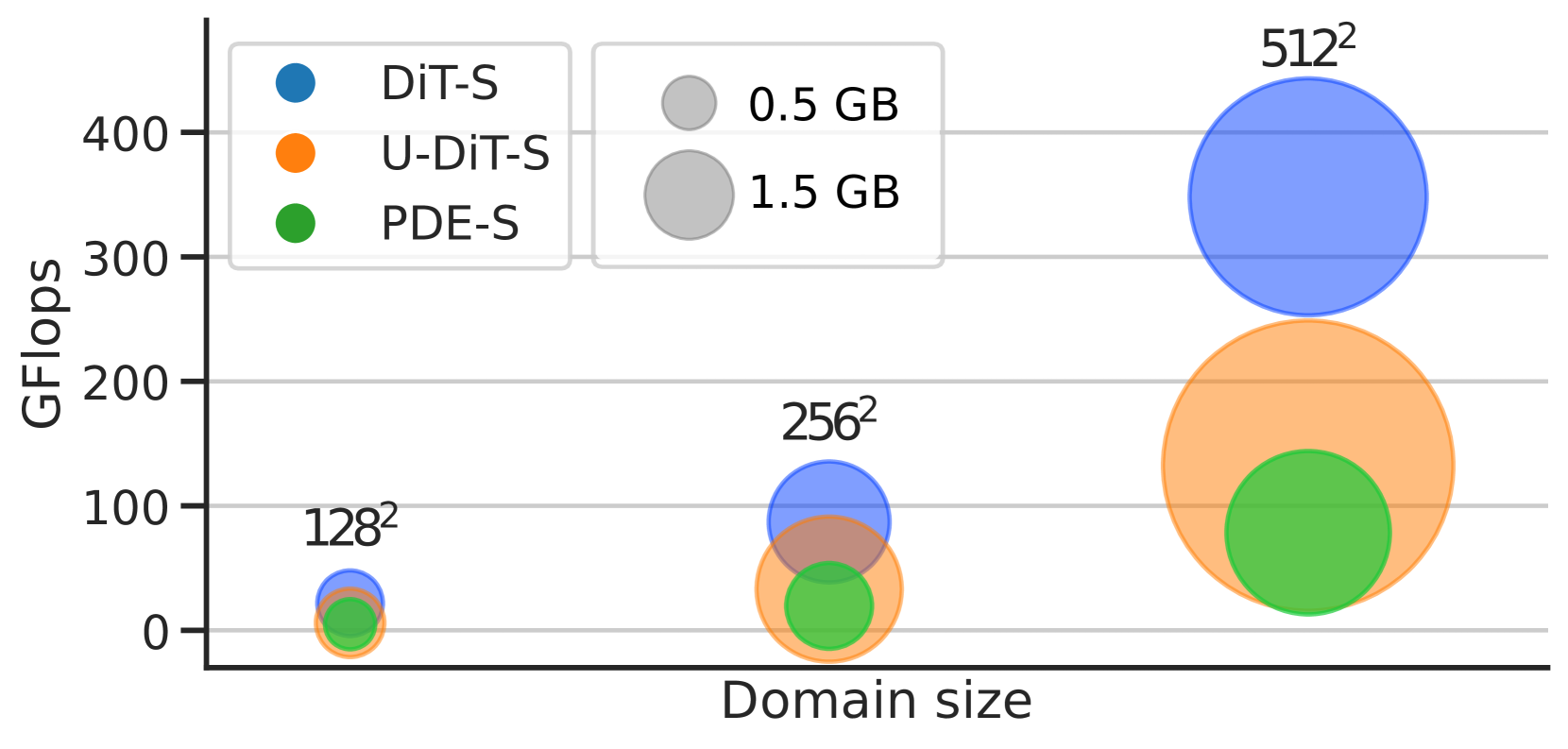
核心思路:PDE-Transformer的核心思路是构建一个更具可扩展性和通用性的Transformer架构,使其能够作为物理科学中大规模基础模型的骨干。通过改进架构设计,使其能够更好地处理大规模物理模拟数据,并提高在不同PDE类型之间的泛化能力。
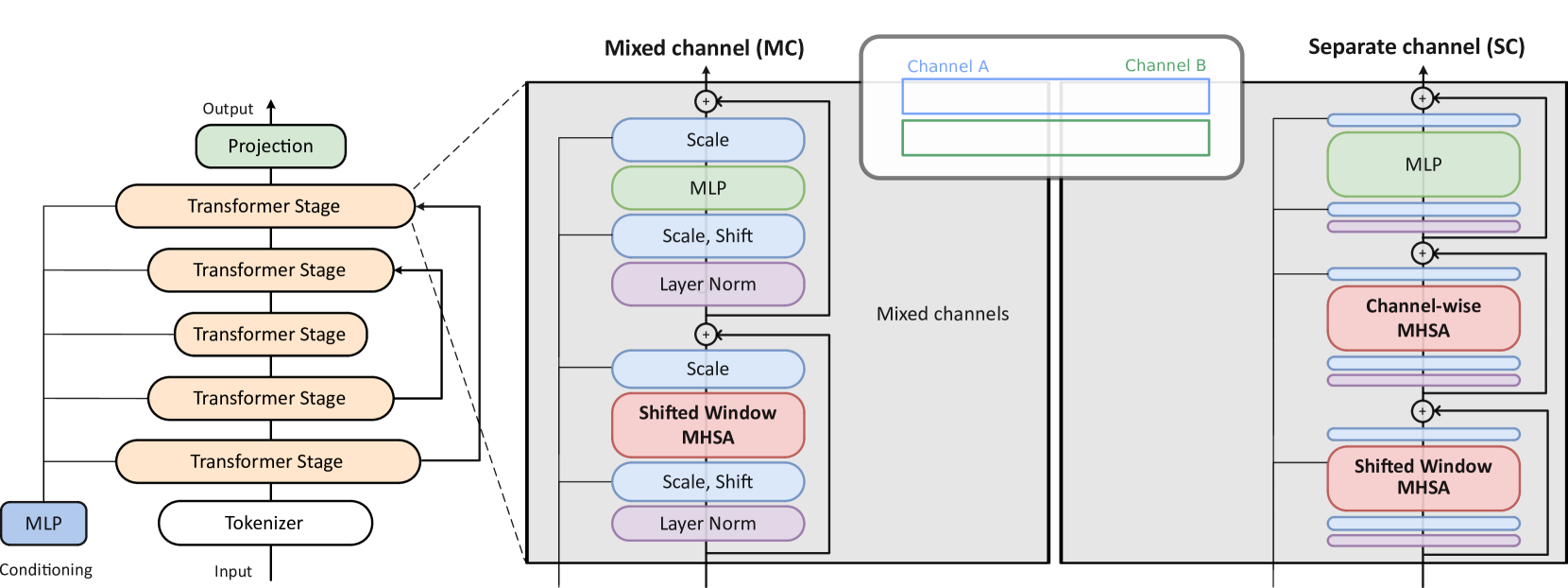
技术框架:PDE-Transformer的整体架构基于Transformer,但进行了针对物理模拟的改进。主要包括:1) 采用扩散Transformer的最新架构改进;2) 针对大规模模拟进行调整,提高可扩展性;3) 将不同的物理通道单独嵌入为时空token;4) 使用通道自注意力机制,使token之间能够进行交互。
关键创新:PDE-Transformer的关键创新在于通道自注意力机制和时空token嵌入方式。通道自注意力机制允许模型在不同物理通道之间进行信息交互,从而更好地理解物理过程。将不同的物理通道单独嵌入为时空token,有助于保持token的信息密度,提高模型在学习多种PDE时的性能。
关键设计:PDE-Transformer的关键设计包括:1) 使用特定的嵌入方式将物理通道转换为时空token;2) 设计通道自注意力机制,允许不同通道之间进行信息交互;3) 采用合适的损失函数,例如均方误差(MSE)或其变体,来训练模型;4) 针对不同的PDE类型,调整网络结构和超参数,以获得最佳性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,PDE-Transformer在包含16种不同类型PDE的大型数据集上,优于用于计算机视觉的最先进的Transformer架构。与从头开始训练相比,预训练的PDE-Transformer在几个具有挑战性的下游任务上实现了更高的性能,并且也优于其他用于物理模拟的基础模型架构。这些结果表明,PDE-Transformer具有很强的泛化能力和实用价值。
🎯 应用场景
PDE-Transformer可应用于各种物理模拟领域,例如流体动力学、热传导、电磁学等。它可以作为物理模拟的代理模型,加速模拟过程,并用于预测物理现象。该研究的潜在价值在于提高物理模拟的效率和准确性,从而促进科学研究和工程应用。未来,PDE-Transformer有望成为物理科学领域的基础模型,为各种下游任务提供支持。
📄 摘要(原文)
We introduce PDE-Transformer, an improved transformer-based architecture for surrogate modeling of physics simulations on regular grids. We combine recent architectural improvements of diffusion transformers with adjustments specific for large-scale simulations to yield a more scalable and versatile general-purpose transformer architecture, which can be used as the backbone for building large-scale foundation models in physical sciences. We demonstrate that our proposed architecture outperforms state-of-the-art transformer architectures for computer vision on a large dataset of 16 different types of PDEs. We propose to embed different physical channels individually as spatio-temporal tokens, which interact via channel-wise self-attention. This helps to maintain a consistent information density of tokens when learning multiple types of PDEs simultaneously. We demonstrate that our pre-trained models achieve improved performance on several challenging downstream tasks compared to training from scratch and also beat other foundation model architectures for physics simulations.