Hyperbolic Dataset Distillation
作者: Wenyuan Li, Guang Li, Keisuke Maeda, Takahiro Ogawa, Miki Haseyama
分类: cs.LG, cs.AI, cs.CV
发布日期: 2025-05-30 (更新: 2025-10-17)
备注: Accepted to NeurIPS 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于双曲空间的HDD数据集精馏方法,有效建模数据层级关系并提升训练稳定性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 数据集精馏 双曲空间 层级结构 分布匹配 深度学习
📋 核心要点
- 现有数据集精馏方法忽略了数据间复杂的层级关系,限制了精馏效果。
- 提出HDD方法,将数据嵌入双曲空间,利用其特性建模层级结构,优化精馏过程。
- 实验表明,HDD能有效保持模型性能,且双曲空间剪枝能显著提高训练稳定性。
📝 摘要(中文)
为了解决深度学习中大规模数据集带来的计算和存储挑战,数据集精馏技术被提出,旨在合成一个紧凑的数据集来替代原始数据集,同时保持相当的模型性能。与需要昂贵双层优化的基于优化的方法不同,分布匹配(DM)方法通过对齐合成数据和原始数据的分布来提高效率,从而消除了嵌套优化。DM实现了很高的计算效率,并已成为一种有前途的解决方案。然而,现有的DM方法受限于欧几里得空间,将数据视为独立同分布的点,忽略了复杂的几何和层级关系。为了克服这个限制,我们提出了一种新的双曲数据集精馏方法,称为HDD。双曲空间具有负曲率和随距离呈指数增长的体积,自然地模拟了层级和树状结构。HDD将浅层网络提取的特征嵌入到洛伦兹双曲空间中,其中合成数据和原始数据之间的差异通过它们质心之间的双曲(测地线)距离来衡量。通过优化这个距离,层级结构被显式地集成到精馏过程中,引导合成样本向原始数据分布的根中心区域靠拢,同时保留其潜在的几何特征。此外,我们发现双曲空间中的剪枝只需要精馏核心集的20%就能保持模型性能,同时显著提高训练稳定性。据我们所知,这是第一个将双曲空间纳入数据集精馏过程的工作。
🔬 方法详解
问题定义:现有数据集精馏方法,特别是分布匹配方法,通常在欧几里得空间中进行,将数据视为独立同分布的点,忽略了数据之间存在的层级和几何关系。这种简化导致精馏后的数据集无法很好地代表原始数据的复杂结构,从而影响模型性能。
核心思路:论文的核心思路是将数据嵌入到双曲空间中进行数据集精馏。双曲空间具有负曲率和指数增长的体积,能够自然地建模层级和树状结构。通过在双曲空间中对齐合成数据和原始数据的分布,可以更好地保留原始数据的层级关系和几何特征。
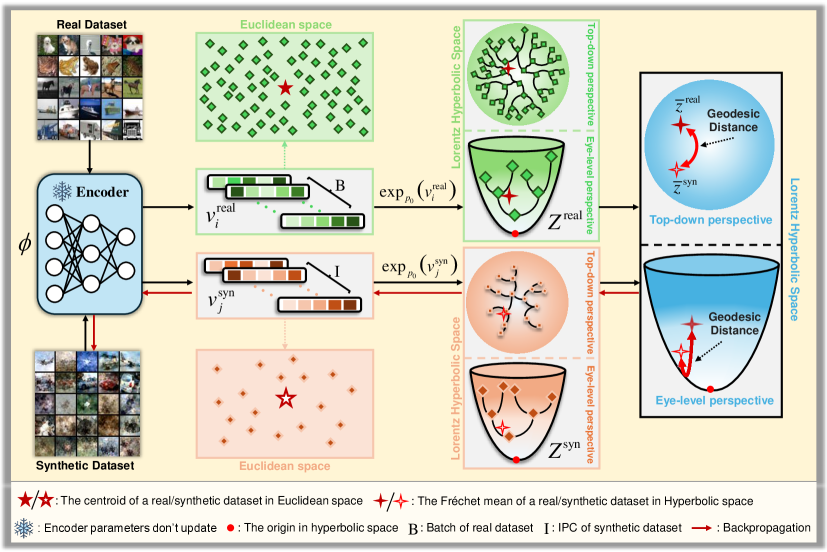
技术框架:HDD方法的技术框架主要包括以下几个步骤:1. 使用一个浅层网络提取原始数据和合成数据的特征。2. 将提取的特征嵌入到洛伦兹双曲空间中。3. 计算原始数据和合成数据在双曲空间中的质心。4. 通过优化原始数据和合成数据质心之间的双曲距离,来训练合成数据集。5. 在双曲空间中进行剪枝,进一步压缩数据集。
关键创新:论文最重要的技术创新点是将双曲空间引入到数据集精馏过程中。这是首次尝试利用双曲空间的特性来建模数据的层级关系,并将其应用于数据集精馏。与传统的欧几里得空间方法相比,HDD能够更好地保留原始数据的结构信息,从而提高精馏效果。
关键设计:HDD的关键设计包括:1. 使用洛伦兹模型来表示双曲空间。2. 使用双曲距离(测地线距离)来衡量数据点之间的相似度。3. 使用基于质心距离的损失函数来优化合成数据集。4. 在双曲空间中进行剪枝,通过移除距离质心较远的数据点来进一步压缩数据集。论文还发现,在双曲空间中进行剪枝时,只需要保留20%的精馏核心集就能保持模型性能。
🖼️ 关键图片


📊 实验亮点
论文提出的HDD方法在数据集精馏任务上取得了显著的成果。实验结果表明,HDD能够有效地保持模型性能,并且通过在双曲空间中进行剪枝,只需要保留20%的精馏核心集就能达到与使用完整精馏数据集相当的性能,同时显著提高了训练稳定性。代码已开源。
🎯 应用场景
该研究成果可应用于各种需要处理大规模数据集的深度学习任务中,例如图像分类、目标检测、自然语言处理等。通过使用HDD方法进行数据集精馏,可以显著减少计算和存储成本,提高训练效率,并为资源受限的设备上的模型部署提供可能。未来,该方法有望进一步扩展到处理更复杂的数据结构和关系。
📄 摘要(原文)
To address the computational and storage challenges posed by large-scale datasets in deep learning, dataset distillation has been proposed to synthesize a compact dataset that replaces the original while maintaining comparable model performance. Unlike optimization-based approaches that require costly bi-level optimization, distribution matching (DM) methods improve efficiency by aligning the distributions of synthetic and original data, thereby eliminating nested optimization. DM achieves high computational efficiency and has emerged as a promising solution. However, existing DM methods, constrained to Euclidean space, treat data as independent and identically distributed points, overlooking complex geometric and hierarchical relationships. To overcome this limitation, we propose a novel hyperbolic dataset distillation method, termed HDD. Hyperbolic space, characterized by negative curvature and exponential volume growth with distance, naturally models hierarchical and tree-like structures. HDD embeds features extracted by a shallow network into the Lorentz hyperbolic space, where the discrepancy between synthetic and original data is measured by the hyperbolic (geodesic) distance between their centroids. By optimizing this distance, the hierarchical structure is explicitly integrated into the distillation process, guiding synthetic samples to gravitate towards the root-centric regions of the original data distribution while preserving their underlying geometric characteristics. Furthermore, we find that pruning in hyperbolic space requires only 20% of the distilled core set to retain model performance, while significantly improving training stability. To the best of our knowledge, this is the first work to incorporate the hyperbolic space into the dataset distillation process. The code is available at https://github.com/Guang000/HDD.