Beyond Linear Steering: Unified Multi-Attribute Control for Language Models
作者: Narmeen Oozeer, Luke Marks, Fazl Barez, Amirali Abdullah
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-05-30 (更新: 2025-09-19)
备注: Accepted to Findings of EMNLP, 2025
💡 一句话要点
K-Steering:一种用于语言模型的多属性统一控制非线性方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型控制 多属性控制 非线性steering 梯度干预 行为组合
📋 核心要点
- 现有线性steering方法在控制LLM多属性时存在属性间干扰和线性假设的局限性,需要对每个属性单独调优。
- K-Steering通过训练非线性多标签分类器,利用梯度计算干预方向,避免了线性假设和独立属性向量的需求。
- 实验表明,K-Steering在ToneBank和DebateMix基准测试中,能够更准确地控制LLM的多个行为属性,优于现有方法。
📝 摘要(中文)
在大型语言模型(LLM)的推理阶段控制多个行为属性是一个具有挑战性的问题,这主要是由于属性之间的相互干扰以及线性steering方法的局限性。线性steering方法假设激活空间中的行为是可加的,并且需要针对每个属性进行单独调整。我们提出了一种统一且灵活的方法,名为K-Steering。该方法在隐藏激活上训练一个非线性多标签分类器,并在推理时通过梯度计算干预方向。这避免了线性假设,消除了存储和调整单独属性向量的需求,并允许动态组合行为而无需重新训练。为了评估我们的方法,我们提出了两个新的基准测试,ToneBank和DebateMix,针对组合行为控制。经验结果表明,在3个模型系列中,经过基于激活的分类器和基于LLM的判断器的验证,K-Steering在准确steering多个行为方面优于强大的基线。
🔬 方法详解
问题定义:现有方法在控制大型语言模型(LLM)的多个行为属性时面临挑战。线性steering方法假设不同属性的行为在激活空间中是线性可加的,这与实际情况不符。此外,这些方法通常需要为每个属性存储和调整单独的向量,增加了计算和存储成本。属性之间的相互干扰也使得同时控制多个属性变得困难。
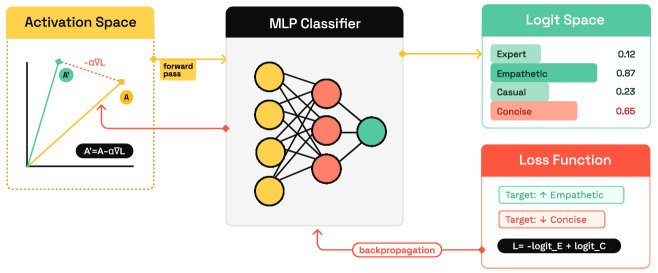
核心思路:K-Steering的核心思想是利用非线性分类器学习隐藏层激活与多个行为属性之间的复杂关系。通过训练一个多标签分类器,模型能够理解不同属性之间的相互作用,并生成更准确的干预方向。在推理时,通过计算分类器输出关于隐藏层激活的梯度,得到干预方向,从而实现对LLM行为的控制。
技术框架:K-Steering主要包含两个阶段:训练阶段和推理阶段。在训练阶段,收集LLM在不同行为属性下的隐藏层激活数据,并训练一个非线性多标签分类器,该分类器的输入是隐藏层激活,输出是对应的行为属性标签。在推理阶段,给定目标行为属性,计算分类器输出关于当前隐藏层激活的梯度,并将该梯度作为干预方向,用于调整LLM的输出。
关键创新:K-Steering的关键创新在于使用非线性分类器来建模隐藏层激活与多个行为属性之间的关系,从而避免了线性假设的限制。此外,K-Steering只需要训练一个分类器,而不需要为每个属性单独训练向量,降低了计算和存储成本。通过梯度计算干预方向,K-Steering能够动态组合不同的行为属性,而无需重新训练模型。
关键设计:K-Steering使用多标签分类器来预测多个行为属性。分类器的具体结构可以根据实际情况选择,例如多层感知机(MLP)或卷积神经网络(CNN)。损失函数通常采用二元交叉熵损失,以衡量预测标签与真实标签之间的差异。在计算梯度时,可以使用自动微分工具,例如PyTorch或TensorFlow。干预方向可以通过调整隐藏层激活来实现,例如将激活向量加上或乘以干预方向。
🖼️ 关键图片
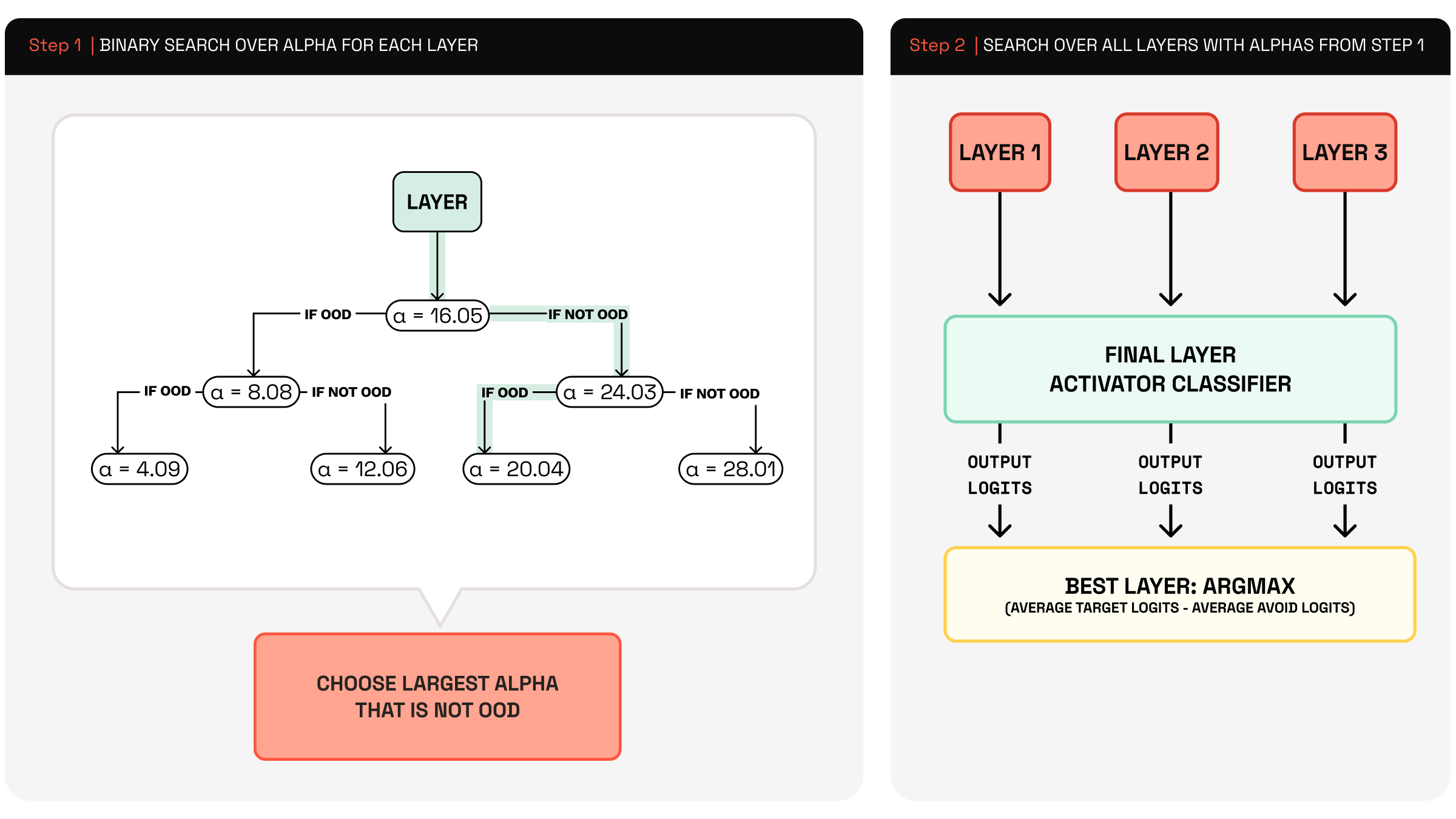
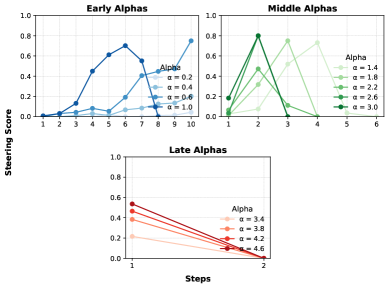
📊 实验亮点
实验结果表明,K-Steering在ToneBank和DebateMix两个新的基准测试中,显著优于现有的线性steering方法。在控制LLM的多个行为属性时,K-Steering能够更准确地实现目标行为,并且具有更好的泛化能力。通过激活分类器和LLM-based judges的验证,证明了K-Steering的有效性。
🎯 应用场景
K-Steering可应用于各种需要精确控制LLM行为的场景,例如对话系统、内容生成和文本摘要。它可以用于控制LLM的语气、风格、观点等多个属性,从而生成更符合用户需求的文本。该方法还可以用于提高LLM的安全性,例如通过控制LLM避免生成有害或不当的内容。未来,K-Steering可以扩展到控制更复杂的行为属性,并与其他技术相结合,实现更高级的LLM控制。
📄 摘要(原文)
Controlling multiple behavioral attributes in large language models (LLMs) at inference time is a challenging problem due to interference between attributes and the limitations of linear steering methods, which assume additive behavior in activation space and require per-attribute tuning. We introduce K-Steering, a unified and flexible approach that trains a single non-linear multi-label classifier on hidden activations and computes intervention directions via gradients at inference time. This avoids linearity assumptions, removes the need for storing and tuning separate attribute vectors, and allows dynamic composition of behaviors without retraining. To evaluate our method, we propose two new benchmarks, ToneBank and DebateMix, targeting compositional behavioral control. Empirical results across 3 model families, validated by both activation-based classifiers and LLM-based judges, demonstrate that K-Steering outperforms strong baselines in accurately steering multiple behaviors.