ReCalKV: Low-Rank KV Cache Compression via Head Reordering and Offline Calibration
作者: Xianglong Yan, Zhiteng Li, Tianao Zhang, Haotong Qin, Linghe Kong, Yulun Zhang, Xiaokang Yang
分类: cs.LG, cs.AI
发布日期: 2025-05-30 (更新: 2025-09-27)
🔗 代码/项目: GITHUB
💡 一句话要点
ReCalKV:通过Head重排序与离线校准实现低秩KV缓存压缩
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: KV缓存压缩 低秩分解 大型语言模型 长上下文推理 模型压缩
📋 核心要点
- 现有KV缓存压缩方法忽略了Key和Value的不同角色和重要性,导致高压缩率下性能显著下降。
- ReCalKV通过Head重排序和离线Value校准,为Key和Value定制压缩策略,实现更高效的低秩近似。
- 实验表明,ReCalKV在保持性能的同时,实现了比现有低秩压缩方法更高的压缩率。
📝 摘要(中文)
大型语言模型(LLMs)展现了卓越的性能,但其长上下文推理仍然受到Key-Value(KV)缓存所需的大量内存的限制。这使得KV缓存压缩成为高效长上下文推理的关键步骤。最近的方法探索了低秩技术来减少KV缓存的隐藏大小。然而,它们忽略了Keys和Values的不同角色和重要性差异,导致在高压缩率下性能显著下降。为了解决这个问题,我们提出ReCalKV,一种后训练低秩KV缓存压缩方法,为Keys和Values定制了策略。对于Keys,我们提出了Head-wise Similarity aware Reordering (HSR),它将结构相似的head聚类成组,从而通过分组SVD实现更准确的低秩近似。对于Values,我们提出了Offline Value Calibration (OVC),它使用校准数据有效地校准value投影矩阵而无需训练,确保上下文信息的准确表示。大量实验表明,ReCalKV始终优于现有的低秩压缩方法,以最小的性能损失实现了高压缩率。
🔬 方法详解
问题定义:论文旨在解决大型语言模型中KV缓存占用内存过大的问题,特别是在长上下文推理场景下。现有的低秩压缩方法虽然能减少KV缓存的体积,但忽略了Key和Value在模型中的不同作用,采用统一的压缩策略,导致在高压缩率下模型性能显著下降。
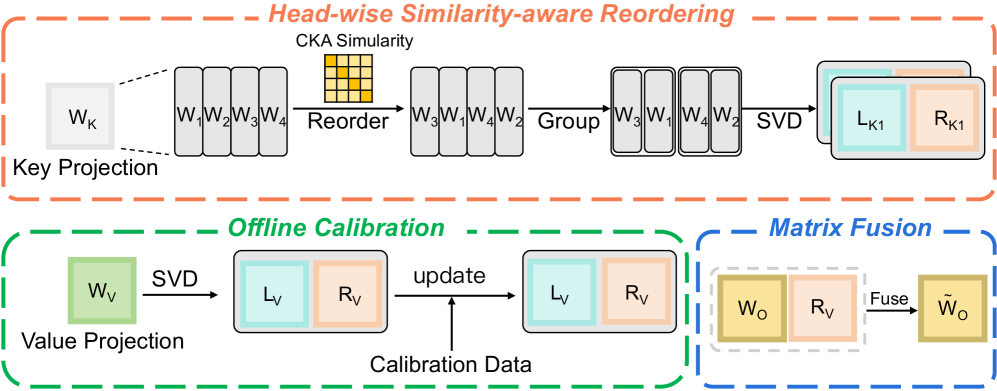
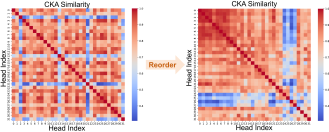
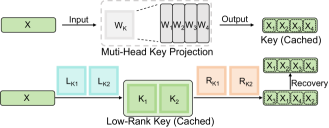
核心思路:ReCalKV的核心思路是针对Key和Value的不同特性,分别设计定制化的低秩压缩策略。对于Key,通过Head重排序,将相似的head分组,然后进行低秩分解,提高压缩效率。对于Value,采用离线校准方法,在不进行训练的情况下,校准Value的投影矩阵,保证上下文信息的准确性。
技术框架:ReCalKV是一个后训练的KV缓存压缩框架,主要包含两个模块:Head-wise Similarity aware Reordering (HSR) 和 Offline Value Calibration (OVC)。HSR模块首先计算不同head之间的相似度,然后将相似的head进行聚类,最后对每个head组进行低秩分解。OVC模块使用校准数据集,通过最小化重构误差来校准Value的投影矩阵。
关键创新:ReCalKV的关键创新在于针对Key和Value分别设计了不同的压缩策略。HSR模块通过考虑head之间的相似性,提高了Key的低秩近似精度。OVC模块通过离线校准,避免了训练过程,提高了Value压缩的效率和准确性。这种针对性的设计是与现有方法的本质区别。
关键设计:HSR模块中,head相似度的计算方式和聚类算法的选择是关键设计。OVC模块中,校准数据集的选择和重构误差的定义是关键设计。论文中可能还涉及低秩分解的具体实现方式(如SVD)和相关参数设置。
🖼️ 关键图片
📊 实验亮点
实验结果表明,ReCalKV在多种模型和数据集上都优于现有的低秩压缩方法。具体来说,ReCalKV在保持较小性能损失的情况下,实现了更高的压缩率。论文中可能给出了具体的性能数据,例如在某个数据集上,ReCalKV相比于其他方法,在压缩率提升X%的同时,性能下降仅为Y%。
🎯 应用场景
ReCalKV可应用于各种需要长上下文推理的大型语言模型,例如文档总结、机器翻译、对话系统等。通过降低KV缓存的内存占用,ReCalKV可以使这些模型在资源受限的设备上运行,或者在相同的硬件条件下处理更长的上下文,从而提高模型的实用性和适用范围。
📄 摘要(原文)
Large language models (LLMs) have demonstrated remarkable performance, but their long-context reasoning remains constrained by the excessive memory required for the Key-Value (KV) cache. This makes KV cache compression a critical step toward efficient long-context inference. Recent methods have explored low-rank techniques to reduce the hidden size of the KV cache. However, they neglect the distinct roles and varying importance of Keys and Values, leading to significant performance drops under high compression. To address this, we propose ReCalKV, a post-training low-rank KV cache compression approach with tailored strategies for Keys and Values. For Keys, we propose Head-wise Similarity aware Reordering (HSR), which clusters structurally similar heads into groups, enabling more accurate low-rank approximation via grouped SVD. For Values, we propose Offline Value Calibration (OVC), which efficiently calibrates the value projection matrix using calibration data without training, ensuring an accurate representation of contextual information. Extensive experiments show that ReCalKV consistently outperforms existing low-rank compression methods, achieving high compression ratios with minimal performance loss. The code and models will be available at:https://github.com/XIANGLONGYAN/ReCalKV.