AReaL: A Large-Scale Asynchronous Reinforcement Learning System for Language Reasoning
作者: Wei Fu, Jiaxuan Gao, Xujie Shen, Chen Zhu, Zhiyu Mei, Chuyi He, Shusheng Xu, Guo Wei, Jun Mei, Jiashu Wang, Tongkai Yang, Binhang Yuan, Yi Wu
分类: cs.LG, cs.AI
发布日期: 2025-05-30 (更新: 2025-11-25)
🔗 代码/项目: GITHUB
💡 一句话要点
AReaL:一种用于语言推理的大规模异步强化学习系统,显著提升训练效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 异步训练 系统优化 语言推理
📋 核心要点
- 现有大规模LLM强化学习系统采用同步模式,GPU利用率低,成为训练瓶颈。
- AReaL通过完全异步的架构,解耦生成与训练过程,实现更高的GPU利用率。
- 实验表明,AReaL在数学和代码推理任务上,训练速度提升高达2.77倍,性能持平或更优。
📝 摘要(中文)
强化学习(RL)已成为训练大型语言模型(LLM)的主流范式,尤其是在推理任务中。LLM 的有效 RL 需要大规模并行化,因此对高效训练系统的需求迫在眉睫。现有的大多数 LLM 大规模 RL 系统是同步的,在批处理设置中交替进行生成和训练,其中每个训练批次中的 rollout 由同一模型生成。这种方法稳定了 RL 训练,但存在严重的系统级效率低下问题:生成必须等到批次中最长的输出完成后才能进行模型更新,从而导致 GPU 利用率不足。我们提出了 AReaL,这是一个完全异步的 RL 系统,它将生成与训练完全分离。AReaL 中的 rollout worker 不间断地生成新的输出,而无需等待,而训练 worker 在收集到一批数据时立即更新模型。AReaL 还包含一系列系统级优化,从而大大提高了 GPU 利用率。为了稳定 RL 训练,AReaL 平衡了 rollout 和训练 worker 的工作负载以控制数据陈旧性,并采用了一种陈旧性增强的 PPO 变体,以更好地处理过时的训练样本。在数学和代码推理基准上的大量实验表明,与使用相同数量 GPU 的同步系统相比,AReaL 实现了高达 2.77 倍的训练加速,并且最终性能相当或更好。AReaL 的代码可在 https://github.com/inclusionAI/AReaL/ 获得。
🔬 方法详解
问题定义:现有的大规模语言模型强化学习系统,尤其是用于推理任务的系统,通常采用同步训练模式。在这种模式下,生成 rollout 和模型训练交替进行,一个批次内的所有 rollout 必须全部完成才能进行模型更新。这种同步机制导致 GPU 在等待最长 rollout 完成时处于空闲状态,造成严重的资源浪费和训练效率低下。
核心思路:AReaL 的核心思路是将 rollout 生成和模型训练完全解耦,采用异步的方式进行。Rollout worker 持续生成新的数据,而训练 worker 在收集到足够的数据后立即进行模型更新,无需等待其他 rollout 完成。这种异步设计旨在最大化 GPU 的利用率,从而加速整个训练过程。
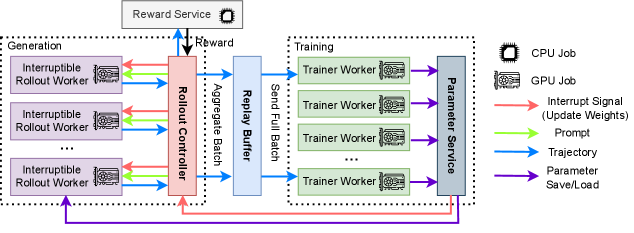
技术框架:AReaL 的整体架构包含两类 worker:rollout worker 和 training worker。Rollout worker 负责生成新的训练数据,它们独立运行,无需同步。Training worker 负责收集 rollout worker 生成的数据,并使用这些数据更新模型。为了保证训练的稳定性,AReaL 引入了数据陈旧性控制机制,平衡 rollout 和 training worker 的工作负载,避免使用过于陈旧的数据进行训练。
关键创新:AReaL 最重要的创新点在于其完全异步的架构设计。与传统的同步系统相比,AReaL 能够充分利用 GPU 资源,避免了因同步等待造成的资源浪费。此外,AReaL 还引入了陈旧性增强的 PPO 变体,以更好地处理异步训练中可能出现的过时数据问题。
关键设计:AReaL 的关键设计包括:1) 异步架构,允许 rollout 和 training worker 独立运行;2) 数据陈旧性控制机制,平衡 rollout 和 training worker 的工作负载;3) 陈旧性增强的 PPO 变体,用于处理过时数据。具体的参数设置和网络结构细节在论文中未详细描述,可能需要参考代码实现。
🖼️ 关键图片


📊 实验亮点
AReaL 在数学和代码推理基准测试中表现出色,与使用相同数量 GPU 的同步系统相比,实现了高达 2.77 倍的训练加速。同时,AReaL 保持了与同步系统相当甚至更优的最终性能,证明了其异步架构的有效性和稳定性。这些结果表明 AReaL 是一种高效且实用的 LLM 强化学习训练系统。
🎯 应用场景
AReaL 的异步强化学习系统可广泛应用于训练用于各种语言推理任务的大型语言模型,例如数学问题求解、代码生成和逻辑推理。该系统能够显著提高训练效率,降低训练成本,并加速 LLM 在实际应用中的部署。未来,该系统可以扩展到其他类型的强化学习任务,例如机器人控制和游戏 AI。
📄 摘要(原文)
Reinforcement learning (RL) has become a dominant paradigm for training large language models (LLMs), particularly for reasoning tasks. Effective RL for LLMs requires massive parallelization and poses an urgent need for efficient training systems. Most existing large-scale RL systems for LLMs are synchronous, alternating generation and training in a batch setting where rollouts in each training batch are generated by the same model. This approach stabilizes RL training but suffers from severe system-level inefficiency: generation must wait until the longest output in the batch is completed before model updates, resulting in GPU underutilization. We present AReaL, a fully asynchronous RL system that completely decouples generation from training. Rollout workers in AReaL continuously generate new outputs without waiting, while training workers update the model whenever a batch of data is collected. AReaL also incorporates a collection of system-level optimizations, leading to substantially higher GPU utilization. To stabilize RL training, AReaL balances the workload of rollout and training workers to control data staleness, and adopts a staleness-enhanced PPO variant to better handle outdated training samples. Extensive experiments on math and code reasoning benchmarks show that AReaL achieves up to 2.77$\times$ training speedup compared to synchronous systems with the same number of GPUs and matched or improved final performance. The code of AReaL is available at https://github.com/inclusionAI/AReaL/.