QiMeng-CodeV-R1: Reasoning-Enhanced Verilog Generation
作者: Yaoyu Zhu, Di Huang, Hanqi Lyu, Xiaoyun Zhang, Chongxiao Li, Wenxuan Shi, Yutong Wu, Jianan Mu, Jinghua Wang, Yang Zhao, Pengwei Jin, Shuyao Cheng, Shengwen Liang, Xishan Zhang, Rui Zhang, Zidong Du, Qi Guo, Xing Hu, Yunji Chen
分类: cs.LG, cs.AR, cs.PL
发布日期: 2025-05-30 (更新: 2025-10-13)
💡 一句话要点
CodeV-R1:推理增强的Verilog代码生成框架,提升硬件设计自动化水平
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Verilog代码生成 强化学习 电子设计自动化 自然语言处理 代码验证
📋 核心要点
- 现有方法缺乏自动、精确的Verilog代码验证环境,高质量自然语言-代码数据集稀缺,且强化学习训练成本高昂。
- CodeV-R1通过规则测试平台生成器进行代码验证,往返数据合成方法生成高质量数据集,并使用自适应DAPO算法降低训练成本。
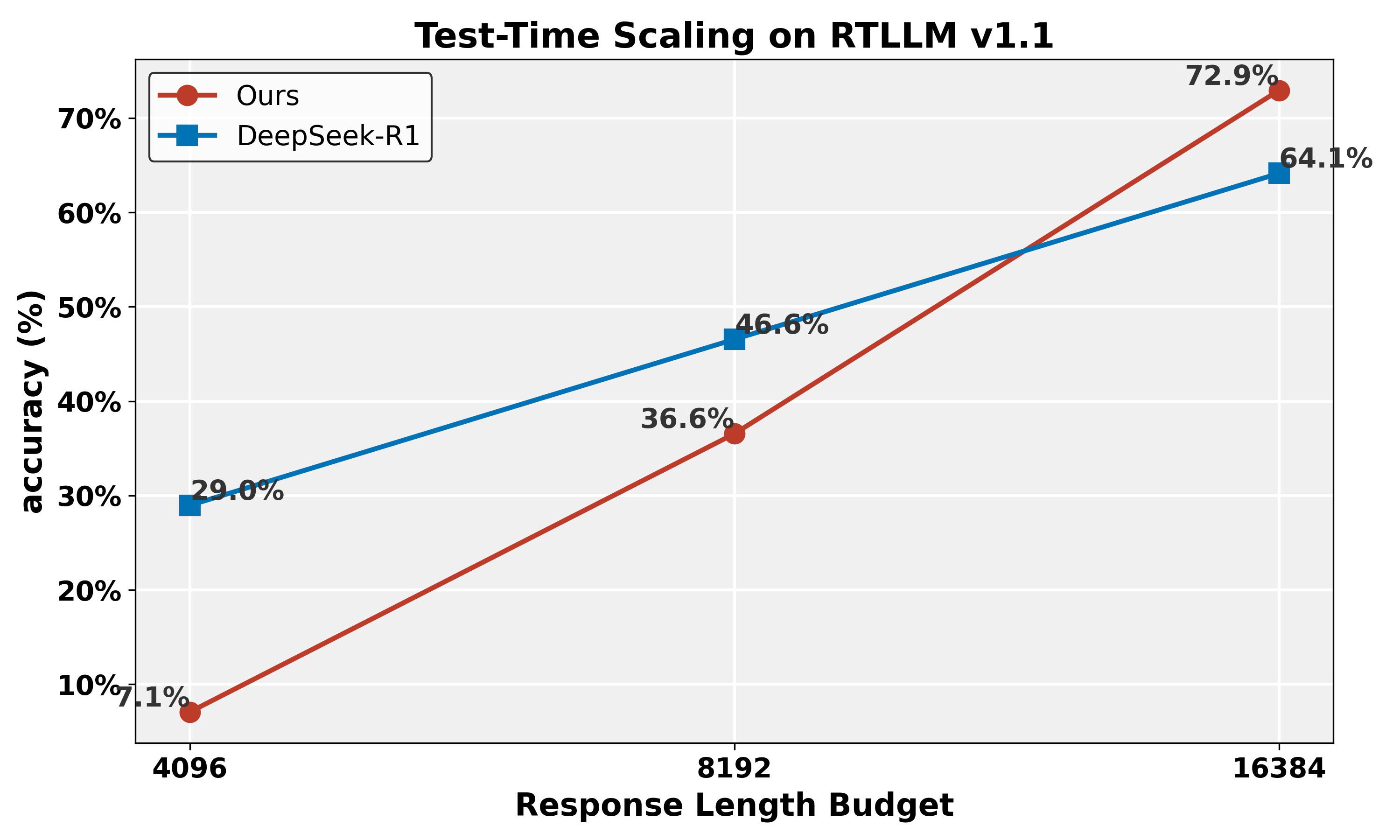
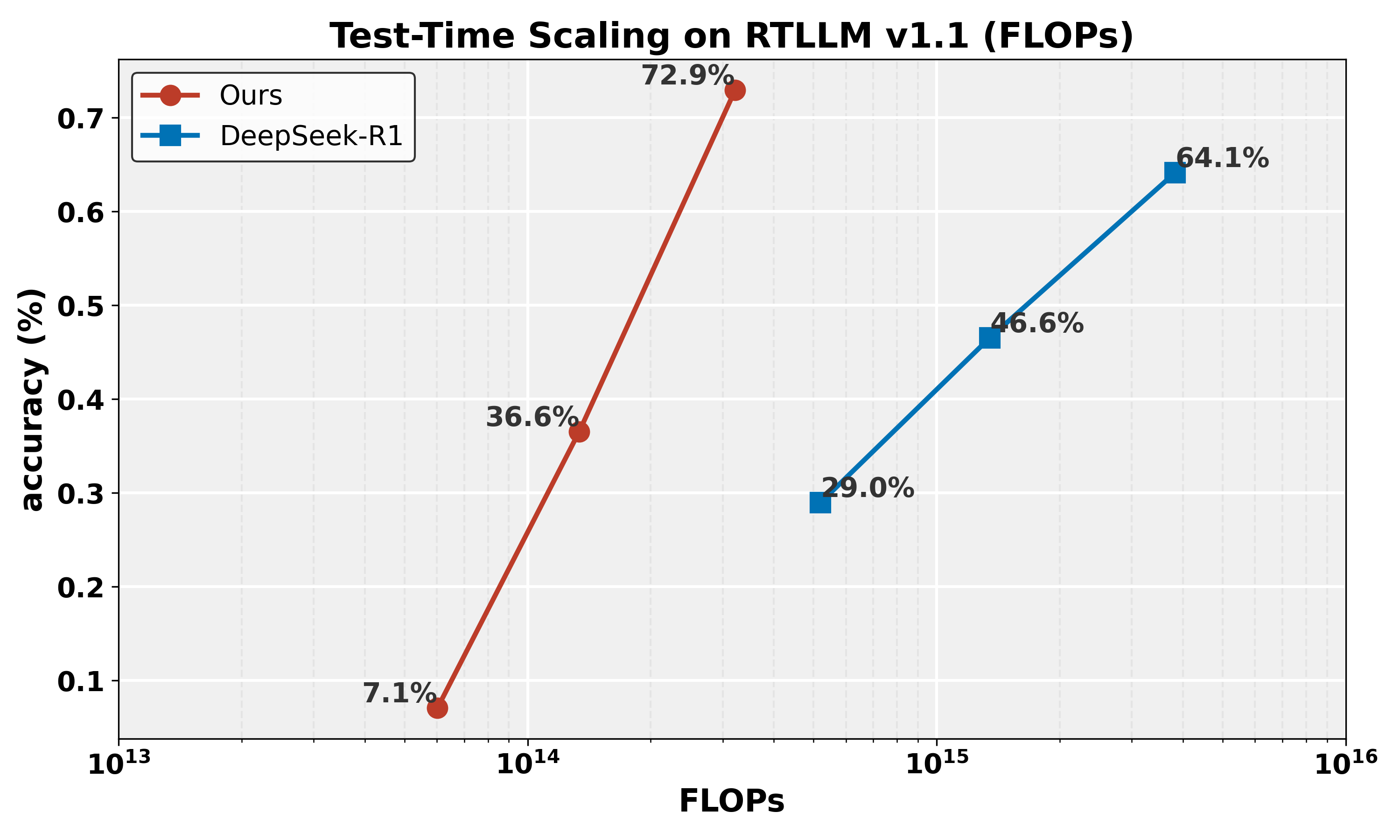
- CodeV-R1-7B在VerilogEval v2和RTLLM v1.1上分别实现了68.6%和72.9%的pass@1,显著超越了现有技术水平。
📝 摘要(中文)
本文介绍了CodeV-R1,一个用于训练Verilog代码生成大语言模型(LLM)的基于可验证奖励的强化学习(RLVR)框架。针对电子设计自动化(EDA)中将RLVR应用于硬件描述语言(HDL)生成的三大挑战:缺乏自动且精确的验证环境、高质量自然语言-代码对的稀缺以及RLVR的高昂计算成本,本文提出了相应的解决方案。首先,开发了一个基于规则的测试平台生成器,用于执行针对黄金参考的鲁棒等价性检查。其次,提出了一种往返数据合成方法,将开源Verilog代码片段与LLM生成的自然语言描述配对,通过生成的测试平台验证代码-自然语言-代码的一致性,并过滤掉不等价的示例以产生高质量数据集。第三,采用两阶段“蒸馏-强化学习”训练流程:蒸馏用于推理能力的冷启动,然后是自适应DAPO,这是一种新型RLVR算法,可以通过自适应调整采样率来降低训练成本。最终模型CodeV-R1-7B在VerilogEval v2和RTLLM v1.1上分别实现了68.6%和72.9%的pass@1,超越了先前的state-of-the-art 12~20%,甚至超过了671B DeepSeek-R1在RTLLM上的性能。该模型、训练代码和数据集已发布,以促进EDA和LLM社区的研究。
🔬 方法详解
问题定义:论文旨在解决从自然语言描述自动生成Verilog代码的问题。现有方法面临三大痛点:一是缺乏可靠的自动验证机制,难以评估生成代码的正确性;二是高质量的自然语言-Verilog代码数据集匮乏,限制了模型的训练效果;三是基于强化学习的训练方式计算成本过高,难以实际应用。
核心思路:论文的核心思路是构建一个可验证奖励的强化学习(RLVR)框架,通过自动化的测试平台生成和数据合成技术,解决验证难题和数据稀缺问题,并设计高效的强化学习算法降低训练成本。这样可以训练出更准确、更高效的Verilog代码生成模型。
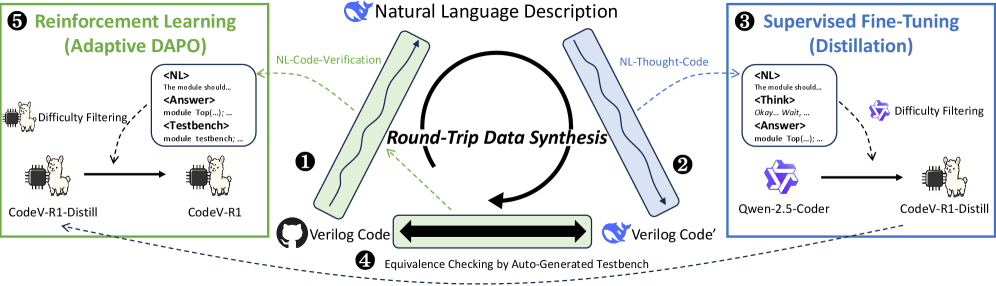
技术框架:CodeV-R1框架包含三个主要模块:1) 基于规则的测试平台生成器,用于自动生成Verilog代码的测试用例并进行等价性验证;2) 往返数据合成方法,利用LLM生成自然语言描述,并验证代码-自然语言-代码的一致性,从而构建高质量数据集;3) 两阶段训练流程,首先使用蒸馏方法进行推理能力冷启动,然后使用自适应DAPO算法进行强化学习训练。
关键创新:论文的关键创新在于:1) 提出了基于规则的测试平台生成器,实现了Verilog代码的自动化验证;2) 设计了往返数据合成方法,有效解决了高质量训练数据稀缺的问题;3) 提出了自适应DAPO算法,通过自适应调整采样率,显著降低了强化学习的训练成本。
关键设计:在往返数据合成中,使用LLM生成自然语言描述,并使用测试平台验证代码-自然语言-代码的一致性,只有通过验证的样本才会被加入训练集。自适应DAPO算法根据训练过程中的性能反馈,动态调整采样率,从而更有效地利用计算资源。具体参数设置和网络结构等细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
CodeV-R1-7B在VerilogEval v2和RTLLM v1.1上分别实现了68.6%和72.9%的pass@1,相比之前的state-of-the-art模型提升了12~20%。更令人瞩目的是,其性能甚至超越了参数量高达671B的DeepSeek-R1在RTLLM上的表现,充分证明了该方法的有效性。
🎯 应用场景
该研究成果可应用于电子设计自动化(EDA)领域,加速硬件设计流程,降低设计成本。通过自然语言描述自动生成Verilog代码,可以降低硬件设计的门槛,使更多工程师能够参与到硬件开发中。未来,该技术有望应用于芯片设计、FPGA开发等领域,推动硬件设计的智能化。
📄 摘要(原文)
Large language models (LLMs) trained via reinforcement learning with verifiable reward (RLVR) have achieved breakthroughs on tasks with explicit, automatable verification, such as software programming and mathematical problems. Extending RLVR to electronic design automation (EDA), especially automatically generating hardware description languages (HDLs) like Verilog from natural-language (NL) specifications, however, poses three key challenges: the lack of automated and accurate verification environments, the scarcity of high-quality NL-code pairs, and the prohibitive computation cost of RLVR. To this end, we introduce CodeV-R1, an RLVR framework for training Verilog generation LLMs. First, we develop a rule-based testbench generator that performs robust equivalence checking against golden references. Second, we propose a round-trip data synthesis method that pairs open-source Verilog snippets with LLM-generated NL descriptions, verifies code-NL-code consistency via the generated testbench, and filters out inequivalent examples to yield a high-quality dataset. Third, we employ a two-stage "distill-then-RL" training pipeline: distillation for the cold start of reasoning abilities, followed by adaptive DAPO, our novel RLVR algorithm that can reduce training cost by adaptively adjusting sampling rate. The resulting model, CodeV-R1-7B, achieves 68.6% and 72.9% pass@1 on VerilogEval v2 and RTLLM v1.1, respectively, surpassing prior state-of-the-art by 12~20%, while even exceeding the performance of 671B DeepSeek-R1 on RTLLM. We have released our model, training code, and dataset to facilitate research in EDA and LLM communities.