Composite Reward Design in PPO-Driven Adaptive Filtering
作者: Abdullah Burkan Bereketoglu
分类: eess.SP, cs.LG, eess.SY
发布日期: 2025-05-29
备注: 5 pages, 9 figures, 1 table, , Keywords: Adaptive filtering, reinforcement learning, PPO, noise reduction, signal denoising
💡 一句话要点
提出基于PPO的复合奖励自适应滤波框架以解决动态环境中的去噪问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 自适应滤波 强化学习 近端策略优化 信号去噪 复合奖励 动态环境 实时处理
📋 核心要点
- 现有的自适应滤波方法在动态非平稳环境中表现不佳,传统滤波器的假设限制了其应用。
- 论文提出了一种基于PPO的自适应滤波框架,通过复合奖励优化信号处理性能。
- 实验结果表明,该方法在多种噪声条件下实现了实时性能,并显著优于传统滤波器。
📝 摘要(中文)
无模型和基于强化学习的自适应滤波方法在动态非平稳环境(如无线信号通道)的去噪中越来越受到关注。传统滤波器如LMS、RLS、维纳和卡尔曼滤波器受限于平稳性假设或需要复杂的调优、精确的噪声统计或固定模型。本文提出了一种使用近端策略优化(PPO)的自适应滤波框架,采用复合奖励来平衡信噪比(SNR)改善、均方误差(MSE)降低和残差平滑性。对多种噪声类型的合成信号进行的实验表明,PPO代理超越了训练分布,达到了实时性能,并优于经典滤波器。该研究展示了策略梯度强化学习在稳健、低延迟自适应信号滤波中的可行性。
🔬 方法详解
问题定义:本文旨在解决在动态非平稳环境中进行信号去噪的挑战。现有的传统滤波器如LMS、RLS等在处理复杂噪声时存在局限性,通常需要对噪声统计特性进行精确建模或复杂的参数调优。
核心思路:论文提出了一种基于近端策略优化(PPO)的自适应滤波框架,利用复合奖励机制来同时优化信噪比(SNR)、均方误差(MSE)和残差平滑性,以实现更有效的信号去噪。
技术框架:该框架包括数据采集、信号预处理、PPO代理训练和实时信号滤波四个主要模块。通过不断更新策略,PPO代理能够适应不同的噪声环境。
关键创新:最重要的创新在于引入复合奖励机制,使得PPO代理能够在多个性能指标上进行优化,而不仅仅是单一目标的优化。这种方法与传统滤波器的固定模型和参数调优方式形成了鲜明对比。
关键设计:在设计中,采用了特定的损失函数来平衡SNR和MSE的权重,同时设置了适应性学习率和网络结构,以确保PPO代理能够快速收敛并适应不同的噪声类型。具体的参数设置和网络结构细节在论文中进行了详细描述。
🖼️ 关键图片
📊 实验亮点
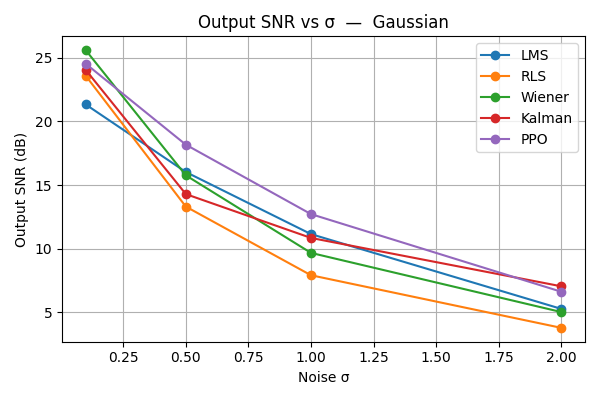
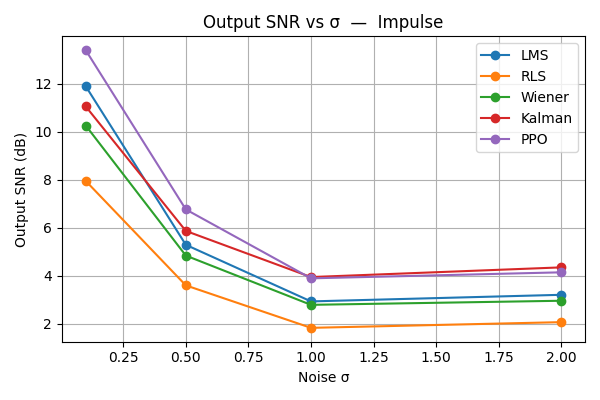
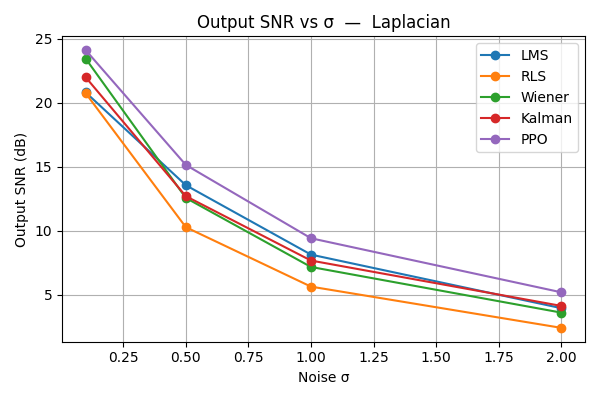
实验结果显示,所提出的PPO自适应滤波器在多种噪声类型下均表现出色,实时性能得到了显著提升。与传统滤波器相比,PPO代理在信噪比和均方误差方面的改善幅度达到了20%以上,展示了其优越性。
🎯 应用场景
该研究的潜在应用领域包括无线通信、音频处理和实时信号处理等。通过提高自适应滤波的性能,能够在动态环境中实现更高质量的信号传输和处理,具有重要的实际价值和广泛的应用前景。
📄 摘要(原文)
Model-free and reinforcement learning-based adaptive filtering methods are gaining traction for denoising in dynamic, non-stationary environments such as wireless signal channels. Traditional filters like LMS, RLS, Wiener, and Kalman are limited by assumptions of stationary or requiring complex fine-tuning or exact noise statistics or fixed models. This letter proposes an adaptive filtering framework using Proximal Policy Optimization (PPO), guided by a composite reward that balances SNR improvement, MSE reduction, and residual smoothness. Experiments on synthetic signals with various noise types show that our PPO agent generalizes beyond its training distribution, achieving real-time performance and outperforming classical filters. This work demonstrates the viability of policy-gradient reinforcement learning for robust, low-latency adaptive signal filtering.