Information Structure in Mappings: An Approach to Learning, Representation, and Generalisation
作者: Henry Conklin
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-05-29
备注: PhD Thesis, 204 pages; entropy estimation discussed from p.94
💡 一句话要点
提出一种量化映射结构的方法,用于理解深度学习模型的表征、泛化能力和设计决策的影响。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 表征学习 信息论 深度学习 泛化能力 模型可解释性
📋 核心要点
- 现有技术缺乏统一的符号体系来描述神经网络的表征空间,难以理解其内部结构。
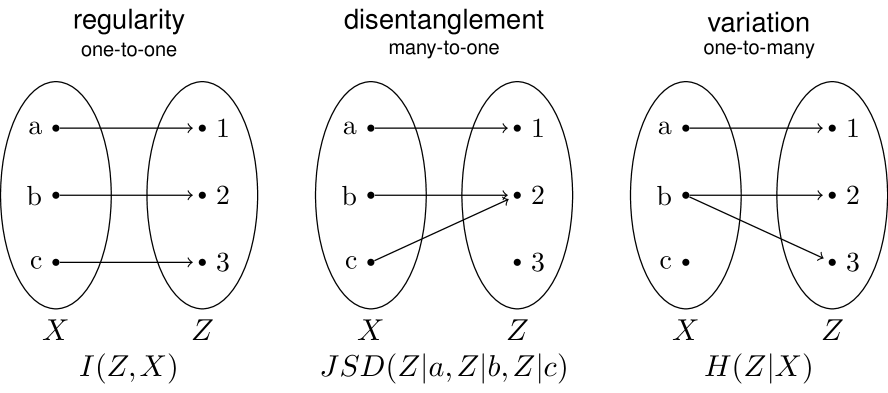
- 论文提出了一种量化映射结构的方法,通过识别结构原语和信息论量化来分析模型。
- 该方法应用于多智能体强化学习、序列到序列模型和大型语言模型,揭示了学习、结构和泛化之间的关系。
📝 摘要(中文)
尽管大规模神经网络取得了显著成功,但我们仍然缺乏统一的符号体系来思考和描述它们的表征空间。我们缺乏可靠的方法来描述其表征是如何构建的,这种结构如何在训练中涌现,以及什么样的结构是理想的。本论文介绍了一种量化方法,用于识别空间映射中的系统性结构,并利用这些方法来理解深度学习模型如何学习表征信息,什么样的表征结构驱动泛化,以及设计决策如何影响涌现的结构。为此,我识别了映射中存在的结构原语,以及每种结构的信息论量化。这使我们能够分析多智能体强化学习模型、在单个任务上训练的序列到序列模型以及大型语言模型的学习、结构和泛化。我还介绍了一种新颖的、高性能的方法来估计向量空间的熵,从而可以将这种分析应用于参数规模从 100 万到 120 亿的模型。
🔬 方法详解
问题定义:现有深度学习模型缺乏可解释性,难以理解其内部表征空间的结构,以及这种结构如何影响模型的泛化能力。现有方法难以可靠地描述表征的构建方式,以及什么样的结构是理想的。
核心思路:论文的核心思路是通过量化模型输入和输出空间之间的映射关系,识别并分析其中存在的结构原语。通过信息论量化这些结构,可以理解模型如何学习表征信息,以及表征结构如何驱动泛化。这种方法允许研究者从信息论的角度理解模型的内部运作机制。
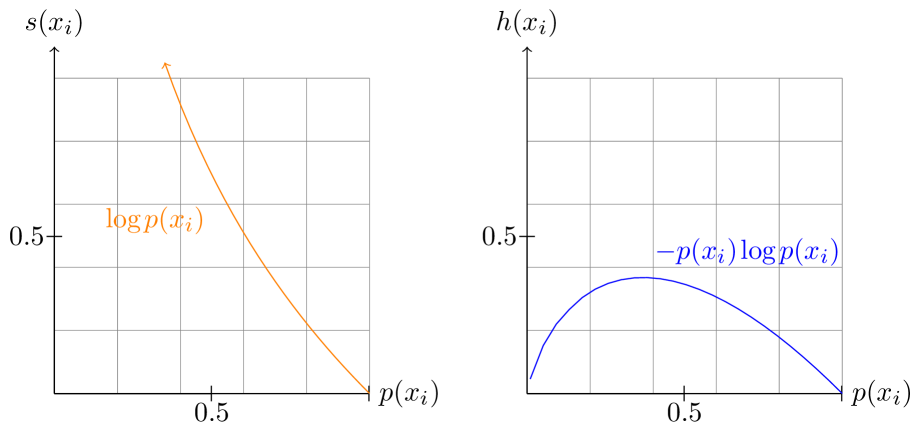
技术框架:该方法主要包含以下几个阶段:1) 识别映射中存在的结构原语;2) 使用信息论方法量化这些结构;3) 将该方法应用于不同的深度学习模型,例如多智能体强化学习模型、序列到序列模型和大型语言模型;4) 分析学习、结构和泛化之间的关系。此外,论文还提出了一种新颖的、高性能的向量空间熵估计方法,用于处理大规模模型。
关键创新:最重要的技术创新点在于提出了一种量化映射结构的方法,能够识别并量化深度学习模型中的结构原语。与现有方法相比,该方法提供了一种更系统、更量化的方式来理解模型的内部表征空间,以及这种表征空间如何影响模型的性能。此外,高性能的向量空间熵估计方法也是一个重要的创新,使得该方法能够应用于更大规模的模型。
关键设计:论文的关键设计包括:1) 如何定义和识别结构原语(具体定义未知);2) 使用哪些信息论指标来量化这些结构(具体指标未知);3) 如何设计高性能的向量空间熵估计方法(具体方法未知)。这些技术细节对于方法的有效性和可扩展性至关重要。
🖼️ 关键图片
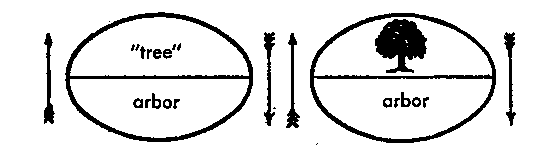
📊 实验亮点
论文通过实验验证了该方法在多智能体强化学习模型、序列到序列模型和大型语言模型上的有效性。实验结果表明,该方法能够有效地识别模型中的结构原语,并量化这些结构对模型性能的影响。此外,论文还展示了高性能的向量空间熵估计方法在处理大规模模型时的优势。
🎯 应用场景
该研究成果可应用于深度学习模型的可解释性分析、模型设计优化和泛化能力提升。通过理解模型内部的表征结构,可以更好地设计模型架构、选择合适的训练数据,并提高模型的鲁棒性和泛化能力。此外,该方法还可以用于比较不同模型之间的表征差异,从而指导模型的选择和集成。
📄 摘要(原文)
Despite the remarkable success of large large-scale neural networks, we still lack unified notation for thinking about and describing their representational spaces. We lack methods to reliably describe how their representations are structured, how that structure emerges over training, and what kinds of structures are desirable. This thesis introduces quantitative methods for identifying systematic structure in a mapping between spaces, and leverages them to understand how deep-learning models learn to represent information, what representational structures drive generalisation, and how design decisions condition the structures that emerge. To do this I identify structural primitives present in a mapping, along with information theoretic quantifications of each. These allow us to analyse learning, structure, and generalisation across multi-agent reinforcement learning models, sequence-to-sequence models trained on a single task, and Large Language Models. I also introduce a novel, performant, approach to estimating the entropy of vector space, that allows this analysis to be applied to models ranging in size from 1 million to 12 billion parameters. The experiments here work to shed light on how large-scale distributed models of cognition learn, while allowing us to draw parallels between those systems and their human analogs. They show how the structures of language and the constraints that give rise to them in many ways parallel the kinds of structures that drive performance of contemporary neural networks.