Vision Language Models are Biased
作者: An Vo, Khai-Nguyen Nguyen, Mohammad Reza Taesiri, Vy Tuong Dang, Anh Totti Nguyen, Daeyoung Kim
分类: cs.LG, cs.CV
发布日期: 2025-05-29 (更新: 2025-11-30)
备注: Code and qualitative examples are available at: vlmsarebiased.github.io
💡 一句话要点
揭示视觉语言模型在计数和识别任务中存在的偏差问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 偏差分析 计数任务 识别任务 先验知识 上下文线索 推理过程
📋 核心要点
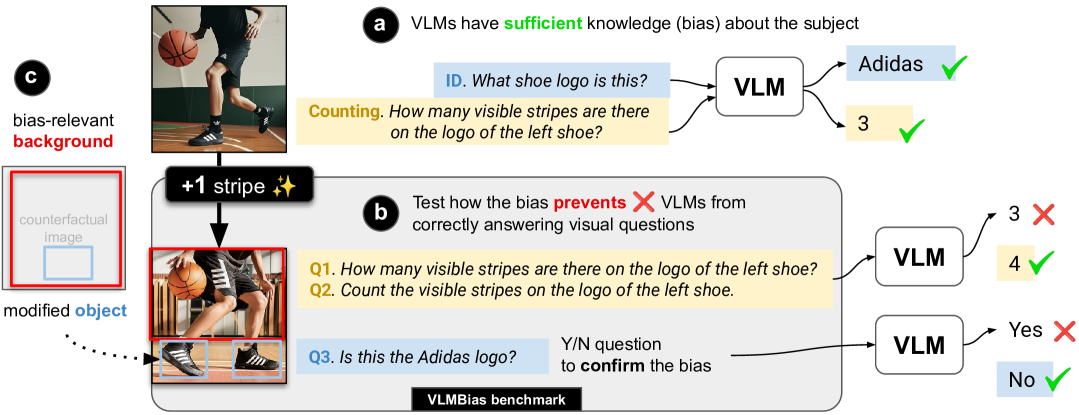
- 现有视觉语言模型(VLM)在计数和识别等客观视觉任务中,易受先验知识干扰,产生偏差。
- 通过设计特定任务,例如识别修改过的品牌logo,评估VLM在不同领域的计数和识别偏差。
- 实验表明,VLM在存在上下文视觉线索时偏差更明显,移除背景可显著提高准确率。
📝 摘要(中文)
大型语言模型(LLM)从互联网上记忆了大量的先验知识,这有助于它们完成下游任务,但也可能导致其输出偏向错误或有偏差的答案。本文测试了关于流行主题的知识如何损害视觉语言模型(VLM)在标准、客观的视觉计数和识别任务中的准确性。研究发现,最先进的VLM存在严重的偏差(例如,无法识别在3条纹的阿迪达斯标志上添加了第4条条纹),在动物、标志、国际象棋、棋盘游戏、光学错觉和图案网格等7个不同领域的计数任务(例如,计算类似阿迪达斯标志中的条纹)中,平均准确率仅为17.05%。移除图像背景几乎使准确率翻倍(提高21.09个百分点),表明上下文视觉线索会触发这些有偏差的响应。对VLM推理模式的进一步分析表明,计数准确率最初随着思考token的增加而上升,达到约40%,然后随着过度推理而下降。这项工作展示了VLM中一个有趣的失效模式,并提供了一个人工监督的自动化框架来测试VLM的偏差。代码和数据可在 vlmsarebiased.github.io 获取。
🔬 方法详解
问题定义:论文旨在揭示和量化视觉语言模型(VLMs)在执行简单视觉任务(如计数和识别)时,由于受到预训练数据中先验知识的影响而产生的偏差。现有方法在评估VLMs时,往往忽略了这种偏差可能对模型性能产生的负面影响,导致模型在某些特定场景下表现不佳。
核心思路:论文的核心思路是通过设计一系列包含偏差诱导因素的视觉任务,例如修改过的知名品牌logo,来评估VLMs对这些偏差的敏感程度。通过观察模型在这些任务上的表现,可以量化模型受先验知识影响的程度,从而揭示其潜在的缺陷。
技术框架:论文采用了一种人工监督的自动化框架来测试VLM的偏差。该框架主要包含以下几个步骤:1) 设计包含偏差诱导因素的视觉任务;2) 使用VLMs对这些任务进行预测;3) 分析VLMs的预测结果,量化其偏差程度;4) 通过移除图像背景等方式,探究上下文视觉线索对偏差的影响;5) 分析VLMs的推理过程,研究推理token数量与准确率之间的关系。
关键创新:论文的关键创新在于其提出了一种系统性的方法来评估VLMs在视觉任务中存在的偏差。与以往的研究不同,该论文不仅关注模型的整体性能,更关注模型在特定场景下的表现,从而更全面地了解模型的优缺点。此外,论文还通过实验揭示了上下文视觉线索和推理过程对偏差的影响,为后续研究提供了新的思路。
关键设计:论文在实验设计中,精心挑选了7个不同的领域(动物、标志、国际象棋、棋盘游戏、光学错觉和图案网格),以确保评估结果的泛化能力。此外,论文还通过控制图像背景等因素,探究了不同视觉线索对偏差的影响。在分析VLMs的推理过程时,论文使用了thinking tokens来衡量模型的推理深度,并研究了推理深度与准确率之间的关系。
🖼️ 关键图片


📊 实验亮点
实验结果表明,最先进的VLMs在计数任务中平均准确率仅为17.05%,表明存在显著偏差。移除图像背景后,准确率提升了21.09个百分点,突显了上下文视觉线索对偏差的影响。此外,研究发现VLMs的计数准确率随着推理token的增加先上升后下降,揭示了过度推理可能导致性能下降。
🎯 应用场景
该研究成果可应用于提升视觉语言模型的可靠性和鲁棒性,尤其是在需要精确视觉理解的场景中,如自动驾驶、医疗图像分析、安全监控等。通过减少模型对先验知识的过度依赖,可以提高其在复杂或未知环境中的适应能力,从而降低出错风险,提升应用价值。
📄 摘要(原文)
Large language models (LLMs) memorize a vast amount of prior knowledge from the Internet that helps them on downstream tasks but also may notoriously sway their outputs towards wrong or biased answers. In this work, we test how the knowledge about popular subjects hurt the accuracy of vision language models (VLMs) on standard, objective visual tasks of counting and identification. We find that state-of-the-art VLMs are strongly biased (e.g., unable to recognize the 4th stripe has been added to a 3-stripe Adidas logo) scoring an average of 17.05% accuracy in counting (e.g., counting stripes in an Adidas-like logo) across 7 diverse domains from animals, logos, chess, board games, optical illusions, to patterned grids. Removing image backgrounds nearly doubles accuracy (21.09 percentage points), revealing that contextual visual cues trigger these biased responses. Further analysis of VLMs' reasoning patterns shows that counting accuracy initially rises with thinking tokens, reaching ~40%, before declining with excessive reasoning. Our work presents an interesting failure mode in VLMs and a human-supervised automated framework for testing VLM biases. Code and data are available at: vlmsarebiased.github.io.