DES-LOC: Desynced Low Communication Adaptive Optimizers for Training Foundation Models
作者: Alex Iacob, Lorenzo Sani, Mher Safaryan, Paris Giampouras, Samuel Horváth, Andrej Jovanovic, Meghdad Kurmanji, Preslav Aleksandrov, William F. Shen, Xinchi Qiu, Nicholas D. Lane
分类: cs.LG
发布日期: 2025-05-28
备注: Keywords: Distributed Training, Foundation Models, Large Language Models, Optimizers, Communication Efficiency, Federated Learning, Distributed Systems, Optimization Theory, Scaling, Robustness. Preprint, under review at NeurIPS
💡 一句话要点
DES-LOC:面向大规模模型训练的解耦低通信自适应优化器
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 分布式训练 自适应优化器 低通信 解耦同步 大规模模型 容错训练 基础模型
📋 核心要点
- 分布式训练中,自适应优化器因需同步额外状态而通信开销大,现有Local SGD扩展方法存在收敛性问题或通信量过高。
- DES-LOC的核心思想是为模型参数和动量分配独立的同步周期,实现通信成本的降低,同时保证模型的收敛性。
- 实验结果表明,DES-LOC在通信效率上显著优于DDP和Local ADAM,并且更适用于实际训练中可能出现的系统故障。
📝 摘要(中文)
本文提出了解耦低通信自适应优化器(DES-LOC),旨在解决分布式数据并行(DDP)方法在扩展基础模型训练时受带宽限制的问题。现有不频繁通信方法(如Local SGD)仅同步模型参数,无法直接应用于自适应优化器,因为后者具有额外的优化器状态。现有扩展Local SGD的方法要么缺乏收敛保证,要么需要同步所有优化器状态,导致通信成本增加三倍。DES-LOC为参数和动量分配独立的同步周期,从而降低通信成本并保持收敛性。在高达17亿参数的语言模型上的大量实验表明,DES-LOC的通信量比DDP少170倍,比之前的最先进的Local ADAM少2倍。此外,与之前的启发式方法不同,DES-LOC适用于易发生系统故障的实际训练场景。DES-LOC为基础模型训练提供了一种可扩展、带宽高效且容错的解决方案。
🔬 方法详解
问题定义:在大规模基础模型的分布式训练中,使用分布式数据并行(DDP)方法进行扩展时,带宽成为主要的瓶颈。传统的Local SGD方法虽然减少了通信量,但主要针对同步模型参数,无法直接应用于如Adam等自适应优化器,因为这些优化器还维护着额外的状态(例如动量)。现有的扩展Local SGD以支持自适应优化器的方法,要么缺乏收敛性保证,要么需要同步所有优化器状态,导致通信成本显著增加,这限制了其在大规模模型训练中的应用。
核心思路:DES-LOC的核心思路是解耦参数和动量的同步频率。不同于以往所有参数和动量以相同频率同步的方法,DES-LOC允许参数和动量拥有独立的同步周期。通过更频繁地同步对模型收敛更重要的参数,而以较低的频率同步动量,从而在保证收敛性的前提下,显著降低整体的通信成本。这种解耦的设计使得优化器能够更好地适应不同参数和动量的特性,从而实现更高效的分布式训练。
技术框架:DES-LOC的整体框架基于分布式数据并行(DDP),每个worker维护模型参数和优化器状态的副本。在每个训练迭代中,worker首先使用本地数据计算梯度,然后根据预设的同步周期,选择性地同步模型参数和动量。同步过程使用All-Reduce操作,将所有worker的梯度或动量进行平均。更新模型参数和动量后,worker继续进行本地训练,直到下一个同步周期。关键在于参数和动量的同步周期是独立设置的,可以根据实际情况进行调整。
关键创新:DES-LOC最重要的创新在于解耦了参数和动量的同步周期。以往的方法要么同步所有状态,要么只同步参数,而DES-LOC允许对不同类型的优化器状态进行差异化处理。这种解耦的设计使得优化器能够在通信效率和模型收敛之间取得更好的平衡。与现有方法的本质区别在于,DES-LOC不再将所有优化器状态视为同等重要,而是根据其对模型收敛的影响程度,分配不同的同步频率。
关键设计:DES-LOC的关键设计在于如何确定参数和动量的同步周期。一种常用的方法是基于经验或启发式规则进行设置,例如,可以根据参数的梯度范数或动量的变化率来动态调整同步周期。另一种方法是使用自动调整算法,例如强化学习,来学习最优的同步策略。此外,DES-LOC还考虑了系统故障的情况,通过引入冗余备份和容错机制,确保训练过程的稳定性和可靠性。具体的损失函数和网络结构与所训练的模型相关,DES-LOC本身是一种通用的优化器,可以应用于各种不同的模型和任务。
🖼️ 关键图片

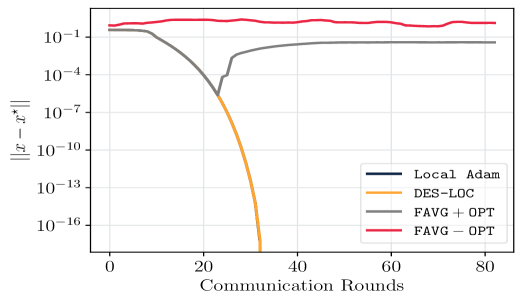
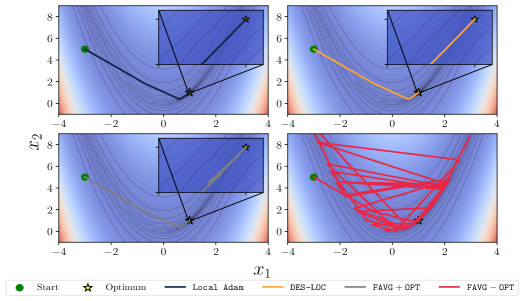
📊 实验亮点
实验结果表明,DES-LOC在训练高达17亿参数的语言模型时,通信量比DDP减少了170倍,比之前的最先进的Local ADAM减少了2倍。此外,DES-LOC在实际训练场景中表现出更好的鲁棒性,能够更好地应对系统故障。这些结果表明,DES-LOC是一种高效、可扩展且容错的分布式训练解决方案。
🎯 应用场景
DES-LOC适用于大规模基础模型的分布式训练,例如大型语言模型、视觉Transformer等。其降低通信成本的特性使其特别适用于带宽受限的训练环境,例如云计算平台或跨地域的分布式集群。该方法可以显著加速模型训练过程,降低训练成本,并提高训练的稳定性和可靠性,从而推动人工智能技术的发展。
📄 摘要(原文)
Scaling foundation model training with Distributed Data Parallel (DDP) methods is bandwidth-limited. Existing infrequent communication methods like Local SGD were designed to synchronize only model parameters and cannot be trivially applied to adaptive optimizers due to additional optimizer states. Current approaches extending Local SGD either lack convergence guarantees or require synchronizing all optimizer states, tripling communication costs. We propose Desynced Low Communication Adaptive Optimizers (DES-LOC), a family of optimizers assigning independent synchronization periods to parameters and momenta, enabling lower communication costs while preserving convergence. Through extensive experiments on language models of up to 1.7B, we show that DES-LOC can communicate 170x less than DDP and 2x less than the previous state-of-the-art Local ADAM. Furthermore, unlike previous heuristic approaches, DES-LOC is suited for practical training scenarios prone to system failures. DES-LOC offers a scalable, bandwidth-efficient, and fault-tolerant solution for foundation model training.