SOReL and TOReL: Two Methods for Fully Offline Reinforcement Learning
作者: Mattie Fellows, Clarisse Wibault, Uljad Berdica, Johannes Forkel, Michael A. Osborne, Jakob N. Foerster
分类: cs.LG, cs.AI
发布日期: 2025-05-28 (更新: 2025-05-29)
🔗 代码/项目: GITHUB
💡 一句话要点
提出SOReL和TOReL,解决离线强化学习中超参数调优和性能评估难题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 贝叶斯方法 超参数调优 环境建模 风险评估
📋 核心要点
- 现有离线强化学习方法依赖大量在线交互进行超参数调优,且初始在线性能缺乏可靠保证。
- SOReL通过贝叶斯方法推断环境动态后验,利用后验预测不确定性估计在线性能,并离线调优超参数。
- TOReL扩展了基于信息率的离线超参数调优方法,使其适用于更广泛的离线RL算法。
📝 摘要(中文)
样本效率仍然是强化学习(RL)在现实世界中应用的主要障碍:目前的成功仅限于模拟器提供几乎无限环境交互的场景,而现实中这些交互通常代价高昂或具有危险性。离线RL原则上提供了一种解决方案,即利用离线数据在部署前学习接近最优的策略。然而,目前的离线RL方法依赖于大量的在线交互来进行超参数调优,并且对其初始在线性能没有可靠的界限。为了解决这两个问题,我们提出了两种算法。首先,SOReL:一种用于安全离线强化学习的算法。仅使用离线数据,我们的贝叶斯方法推断环境动态的后验分布,通过后验预测不确定性获得在线性能的可靠估计。至关重要的是,所有超参数也完全离线调优。其次,我们引入了TOReL:一种用于离线强化学习算法的调优方法,它将我们基于信息率的离线超参数调优方法扩展到一般的离线RL方法。我们的实验评估证实了SOReL在贝叶斯设置中准确估计遗憾的能力,而TOReL的离线超参数调优仅使用离线数据就实现了与最佳在线超参数调优方法相媲美的性能。因此,SOReL和TOReL为安全可靠的离线RL迈出了重要一步,释放了RL在现实世界中的潜力。我们的实现已公开。
🔬 方法详解
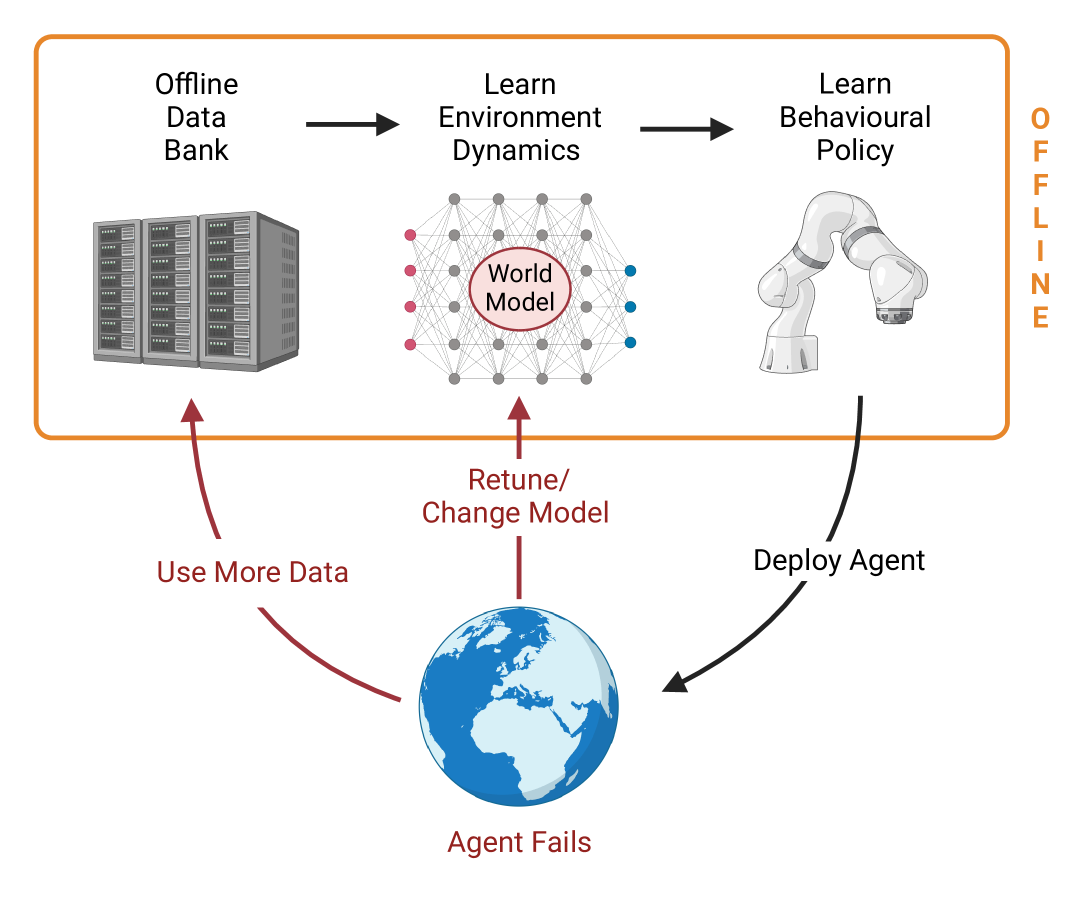
问题定义:离线强化学习旨在利用预先收集好的数据集训练策略,避免与真实环境的交互。然而,现有方法通常需要额外的在线交互进行超参数调整,这违背了离线学习的初衷,并且难以保证初始部署时的性能安全。因此,如何完全基于离线数据进行超参数调优和性能评估是关键问题。
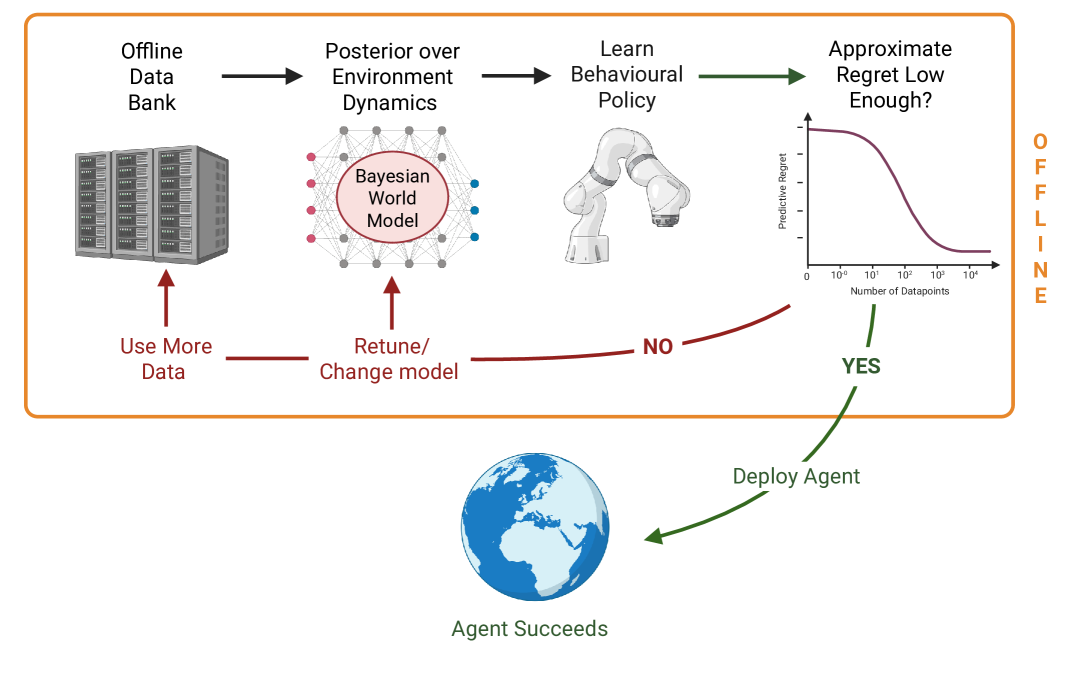
核心思路:SOReL的核心思路是利用贝叶斯方法对环境动态进行建模,通过后验分布来估计策略的性能,并利用后验预测不确定性来评估风险。TOReL则将基于信息率的超参数调优方法扩展到更通用的离线RL算法中,从而实现完全离线的超参数优化。
技术框架:SOReL包含以下主要步骤:1) 利用离线数据构建环境动态的贝叶斯模型;2) 基于该模型推断策略的后验性能分布;3) 利用后验分布的不确定性来评估策略的风险;4) 完全离线地调整超参数以优化性能和降低风险。TOReL则将信息率的概念引入离线超参数调优,通过最大化策略的信息增益来选择最优的超参数组合。
关键创新:SOReL的关键创新在于利用贝叶斯方法对环境动态进行建模,并利用后验预测不确定性来评估策略的风险。这使得SOReL能够在完全离线的环境下,对策略的性能进行可靠的估计,并进行安全的超参数调优。TOReL的创新在于将信息率的概念引入离线超参数调优,从而能够更有效地搜索最优的超参数组合。与现有方法相比,SOReL和TOReL都避免了在线交互,实现了真正的离线强化学习。
关键设计:SOReL中,环境动态的贝叶斯模型可以使用高斯过程或其他合适的概率模型来表示。后验性能分布可以通过蒙特卡洛采样或其他近似推断方法来估计。风险评估可以基于后验分布的方差或其他不确定性度量。TOReL中,信息率可以通过策略的价值函数或Q函数的改变来估计。超参数的搜索可以使用贝叶斯优化或其他优化算法。
🖼️ 关键图片
📊 实验亮点
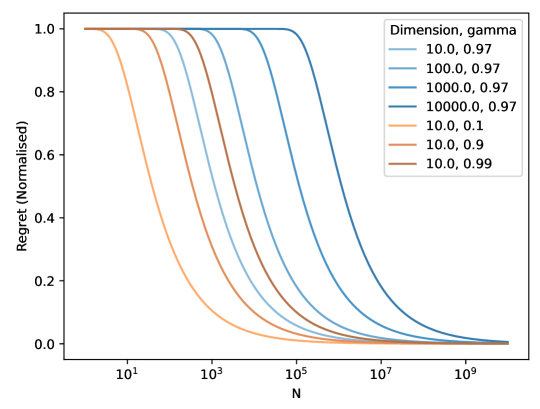
实验结果表明,SOReL能够在贝叶斯设置中准确估计遗憾,并且TOReL的离线超参数调优能够达到与最佳在线超参数调优方法相媲美的性能。这表明SOReL和TOReL在离线强化学习的性能评估和超参数调优方面具有显著优势。
🎯 应用场景
SOReL和TOReL的潜在应用领域包括自动驾驶、医疗诊断、金融交易等。在这些领域中,与环境的交互成本高昂或存在风险,因此离线强化学习具有重要的应用价值。SOReL和TOReL能够安全可靠地利用离线数据学习策略,降低了部署风险,加速了强化学习在现实世界中的应用。
📄 摘要(原文)
Sample efficiency remains a major obstacle for real world adoption of reinforcement learning (RL): success has been limited to settings where simulators provide access to essentially unlimited environment interactions, which in reality are typically costly or dangerous to obtain. Offline RL in principle offers a solution by exploiting offline data to learn a near-optimal policy before deployment. In practice, however, current offline RL methods rely on extensive online interactions for hyperparameter tuning, and have no reliable bound on their initial online performance. To address these two issues, we introduce two algorithms. Firstly, SOReL: an algorithm for safe offline reinforcement learning. Using only offline data, our Bayesian approach infers a posterior over environment dynamics to obtain a reliable estimate of the online performance via the posterior predictive uncertainty. Crucially, all hyperparameters are also tuned fully offline. Secondly, we introduce TOReL: a tuning for offline reinforcement learning algorithm that extends our information rate based offline hyperparameter tuning methods to general offline RL approaches. Our empirical evaluation confirms SOReL's ability to accurately estimate regret in the Bayesian setting whilst TOReL's offline hyperparameter tuning achieves competitive performance with the best online hyperparameter tuning methods using only offline data. Thus, SOReL and TOReL make a significant step towards safe and reliable offline RL, unlocking the potential for RL in the real world. Our implementations are publicly available: https://github.com/CWibault/sorel_torel.