Scaling Reasoning without Attention
作者: Xueliang Zhao, Wei Wu, Lingpeng Kong
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-05-28
备注: preprint
💡 一句话要点
提出无注意力语言模型以解决推理效率低下问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 无注意力模型 复杂推理 状态空间模型 课程微调 语言模型
📋 核心要点
- 现有大型语言模型在推理任务中效率低下,主要由于依赖于Transformer架构和缺乏有效的微调策略。
- 本文提出的无注意力语言模型通过状态空间双层架构消除了自注意力机制,采用两阶段课程微调策略以提升推理能力。
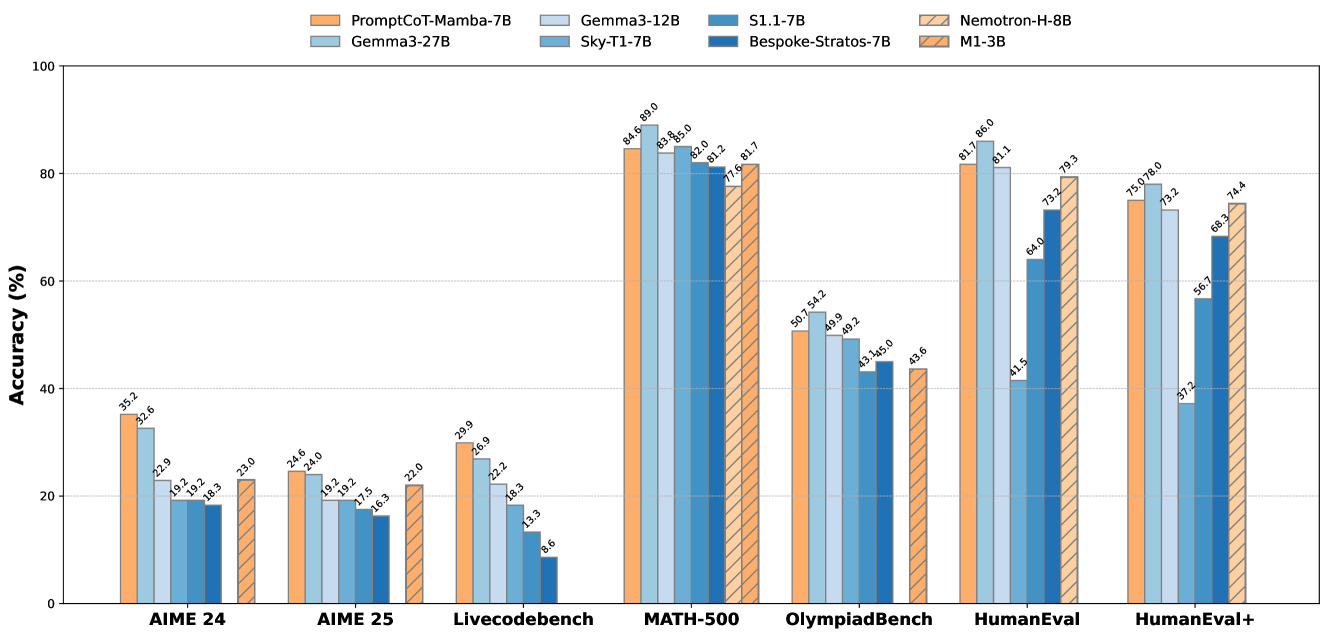
- 实验结果表明, extit{ourmodel-7B}在多个基准测试中超越了同规模和更大规模的模型,显示出显著的性能提升。
📝 摘要(中文)
大型语言模型(LLMs)在复杂推理任务中取得了显著进展,但仍面临两个核心挑战:由于依赖于Transformer架构导致的效率低下,以及在高难度领域缺乏结构化的微调。本文提出了一种无注意力语言模型 extit{ourmodel},通过架构和数据中心的创新来解决这两个问题。该模型基于Mamba-2的状态空间双层(SSD),消除了自注意力和键值缓存的需求,实现了固定内存和常数时间的推理。为了训练复杂推理,我们提出了一种基于 extsc{PromptCoT}合成范式的两阶段课程微调策略,生成通过抽象概念选择和推理引导生成的教学结构问题。在基准评估中, extit{ourmodel-7B}超越了同规模的强大Transformer和混合模型,甚至在AIME 24、AIME 25和Livecodebench上分别超越了更大规模的Gemma3-27B 2.6%、0.6%和3.0%。这些结果突显了状态空间模型作为高容量推理的高效可扩展替代方案的潜力。
🔬 方法详解
问题定义:本文旨在解决大型语言模型在复杂推理任务中的效率低下问题,现有方法主要依赖于Transformer架构,导致推理速度慢且资源消耗高。
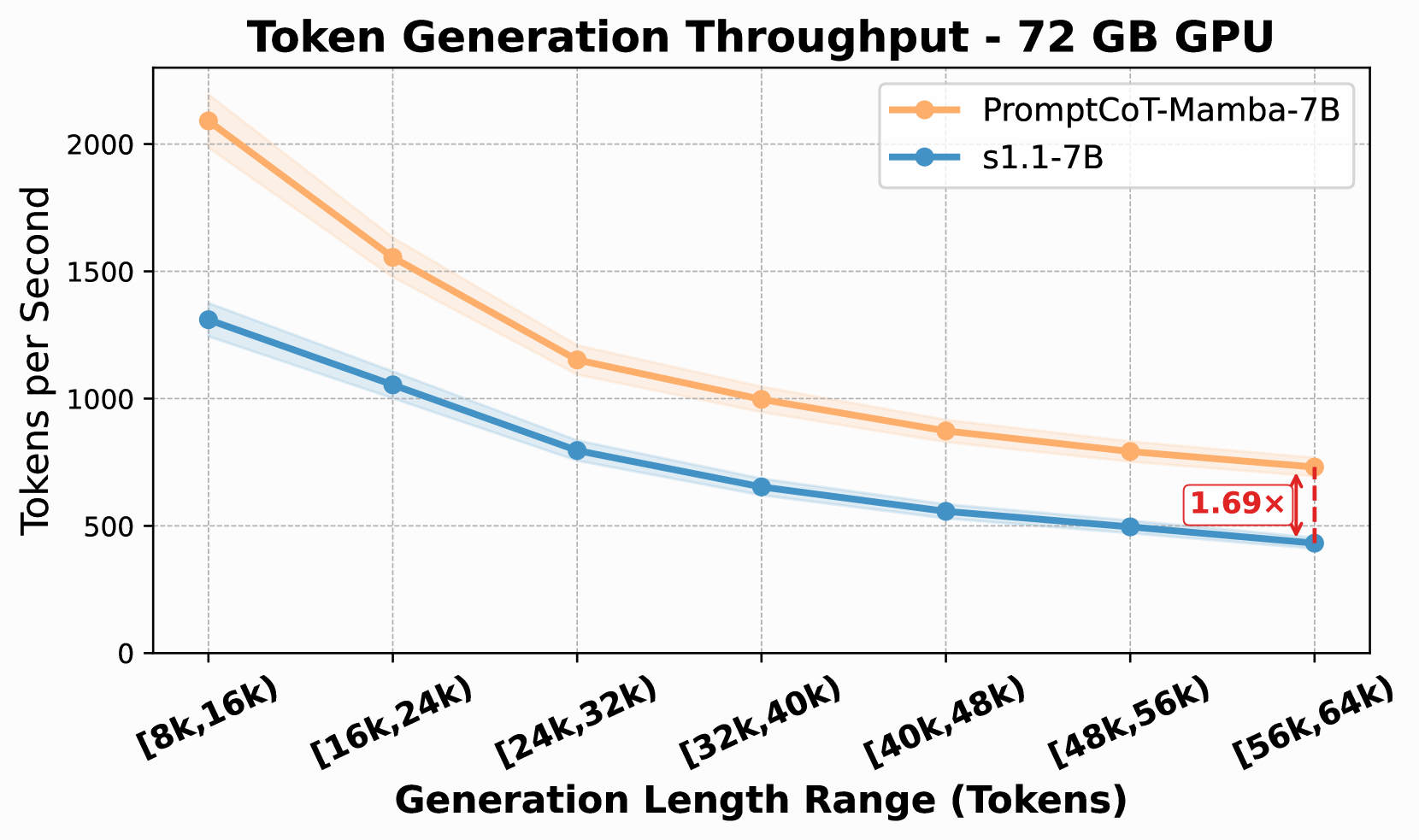
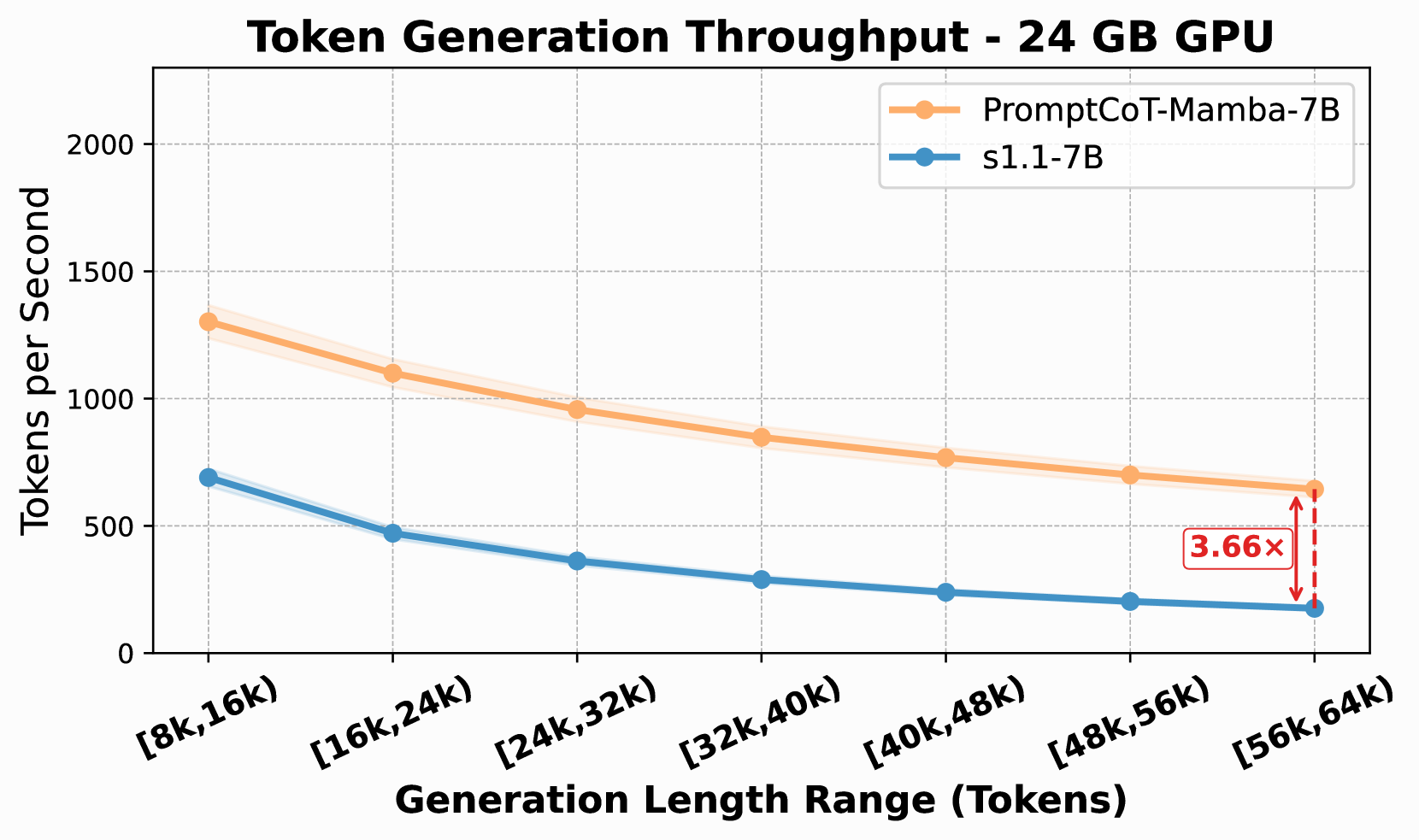
核心思路:提出一种无注意力的语言模型 extit{ourmodel},通过状态空间双层(SSD)架构消除自注意力机制,从而实现固定内存和常数时间的推理效率。
技术框架:模型的整体架构包括状态空间双层结构,采用两阶段课程微调策略。第一阶段生成教学结构问题,第二阶段进行推理能力的提升训练。
关键创新:最重要的创新在于去除了自注意力机制,采用状态空间模型作为替代方案,从而在推理效率和资源利用上实现了显著提升。
关键设计:模型设计中采用了固定内存配置,损失函数和网络结构经过精心调整,以适应无注意力机制的特性,确保在复杂推理任务中的表现优越。
🖼️ 关键图片
📊 实验亮点
实验结果显示, extit{ourmodel-7B}在AIME 24、AIME 25和Livecodebench上分别超越了Gemma3-27B 2.6%、0.6%和3.0%。这些结果表明,该模型在复杂推理任务中具有显著的性能优势,验证了其作为高效替代方案的潜力。
🎯 应用场景
该研究的潜在应用领域包括教育、自动化推理系统和智能助手等。通过提高推理效率, extit{ourmodel}可以在需要快速响应和高准确度的场景中发挥重要作用,未来可能推动更广泛的智能应用发展。
📄 摘要(原文)
Large language models (LLMs) have made significant advances in complex reasoning tasks, yet they remain bottlenecked by two core challenges: architectural inefficiency due to reliance on Transformers, and a lack of structured fine-tuning for high-difficulty domains. We introduce \ourmodel, an attention-free language model that addresses both issues through architectural and data-centric innovations. Built on the state space dual (SSD) layers of Mamba-2, our model eliminates the need for self-attention and key-value caching, enabling fixed-memory, constant-time inference. To train it for complex reasoning, we propose a two-phase curriculum fine-tuning strategy based on the \textsc{PromptCoT} synthesis paradigm, which generates pedagogically structured problems via abstract concept selection and rationale-guided generation. On benchmark evaluations, \ourmodel-7B outperforms strong Transformer and hybrid models of comparable scale, and even surpasses the much larger Gemma3-27B by 2.6\% on AIME 24, 0.6\% on AIME 25, and 3.0\% on Livecodebench. These results highlight the potential of state space models as efficient and scalable alternatives to attention-based architectures for high-capacity reasoning.