An Augmentation-Aware Theory for Self-Supervised Contrastive Learning
作者: Jingyi Cui, Hongwei Wen, Yisen Wang
分类: cs.LG
发布日期: 2025-05-28
备注: Accepted to ICML2025
💡 一句话要点
提出一种数据增强感知的自监督对比学习理论框架,显式建模数据增强的影响。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 自监督学习 对比学习 数据增强 理论分析 误差界限
📋 核心要点
- 现有自监督对比学习理论研究对数据增强的作用,特别是不同增强类型的影响,缺乏深入分析。
- 论文提出了一个数据增强感知的误差界限,将监督风险与无监督风险以及数据增强引入的权衡显式关联。
- 通过像素级和表征级的实验,验证了所提出的理论结果,为理解数据增强在自监督学习中的作用提供了依据。
📝 摘要(中文)
自监督对比学习已成为机器学习和计算机视觉领域中一种强大的工具,用于从无标签数据中学习有意义的表征。与此同时,其经验上的成功也鼓励了许多理论研究来揭示其学习机制。然而,在现有的理论研究中,数据增强的作用仍未得到充分利用,特别是特定增强类型的影响。为了填补这一空白,我们首次提出了一个数据增强感知的自监督对比学习的误差界限,表明监督风险不仅受无监督风险的约束,而且还明确地受到数据增强所引起的权衡的影响。然后,在一个新的语义标签假设下,我们讨论了某些增强方法如何影响误差界限。最后,我们进行了像素级和表征级的实验来验证我们提出的理论结果。
🔬 方法详解
问题定义:现有的自监督对比学习理论研究未能充分挖掘数据增强在学习过程中的作用,特别是忽略了不同类型数据增强对最终表征学习的影响。这导致我们难以理解为何某些数据增强方法在特定任务上表现更好,以及如何选择合适的数据增强策略。
核心思路:论文的核心思路是将数据增强显式地纳入自监督对比学习的理论框架中,通过推导一个数据增强感知的误差界限,来量化数据增强对监督风险的影响。该误差界限不仅考虑了无监督风险,还考虑了由数据增强引入的权衡,从而能够更全面地分析自监督对比学习的学习机制。
技术框架:论文的技术框架主要包括以下几个部分:1) 提出了一个数据增强感知的误差界限,该界限将监督风险与无监督风险以及数据增强引入的权衡联系起来。2) 在一个新的语义标签假设下,分析了特定数据增强方法如何影响误差界限。3) 通过像素级和表征级的实验,验证了所提出的理论结果。整体流程是从理论推导到实验验证,旨在揭示数据增强在自监督对比学习中的作用。
关键创新:论文最重要的技术创新点在于提出了一个数据增强感知的误差界限。与现有理论研究不同,该误差界限显式地考虑了数据增强对监督风险的影响,从而能够更准确地评估自监督对比学习的性能。此外,论文还提出了一个新的语义标签假设,用于分析特定数据增强方法的影响。
关键设计:论文的关键设计包括:1) 数据增强感知的误差界限的具体形式,它将监督风险分解为无监督风险和数据增强相关的项。2) 语义标签假设的具体内容,它描述了数据增强如何改变样本的语义标签。3) 实验设计,包括像素级和表征级的实验设置,以及用于验证理论结果的指标。
🖼️ 关键图片


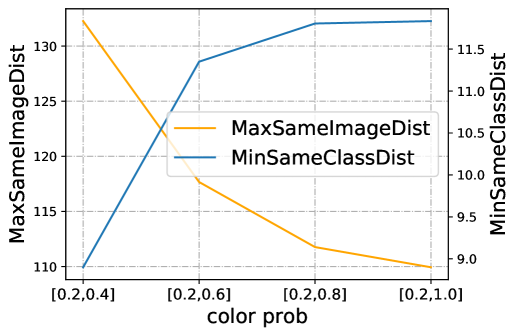
📊 实验亮点
论文通过实验验证了提出的理论结果。在像素级实验中,观察到不同数据增强方法对误差界限的影响与理论预测相符。在表征级实验中,使用学习到的表征进行下游任务,结果表明,通过数据增强感知的策略选择数据增强方法,可以获得更好的性能。具体提升幅度未知,但实验结果支持了论文的理论分析。
🎯 应用场景
该研究成果可应用于指导自监督学习中数据增强策略的选择,提升模型在图像识别、目标检测等任务上的性能。通过理解不同数据增强方法对表征学习的影响,可以设计更有效的自监督学习算法,降低对标注数据的依赖,从而在数据稀缺场景下发挥更大的作用。此外,该理论框架也可以推广到其他自监督学习方法中。
📄 摘要(原文)
Self-supervised contrastive learning has emerged as a powerful tool in machine learning and computer vision to learn meaningful representations from unlabeled data. Meanwhile, its empirical success has encouraged many theoretical studies to reveal the learning mechanisms. However, in the existing theoretical research, the role of data augmentation is still under-exploited, especially the effects of specific augmentation types. To fill in the blank, we for the first time propose an augmentation-aware error bound for self-supervised contrastive learning, showing that the supervised risk is bounded not only by the unsupervised risk, but also explicitly by a trade-off induced by data augmentation. Then, under a novel semantic label assumption, we discuss how certain augmentation methods affect the error bound. Lastly, we conduct both pixel- and representation-level experiments to verify our proposed theoretical results.