LLMs Judging LLMs: A Simplex Perspective
作者: Patrick Vossler, Fan Xia, Yifan Mai, Adarsh Subbaswamy, Jean Feng
分类: cs.LG, cs.AI, stat.ML
发布日期: 2025-05-28 (更新: 2025-12-05)
💡 一句话要点
提出几何贝叶斯方法以评估大型语言模型的输出质量
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 自动评估 几何贝叶斯 认知不确定性 模型排名
📋 核心要点
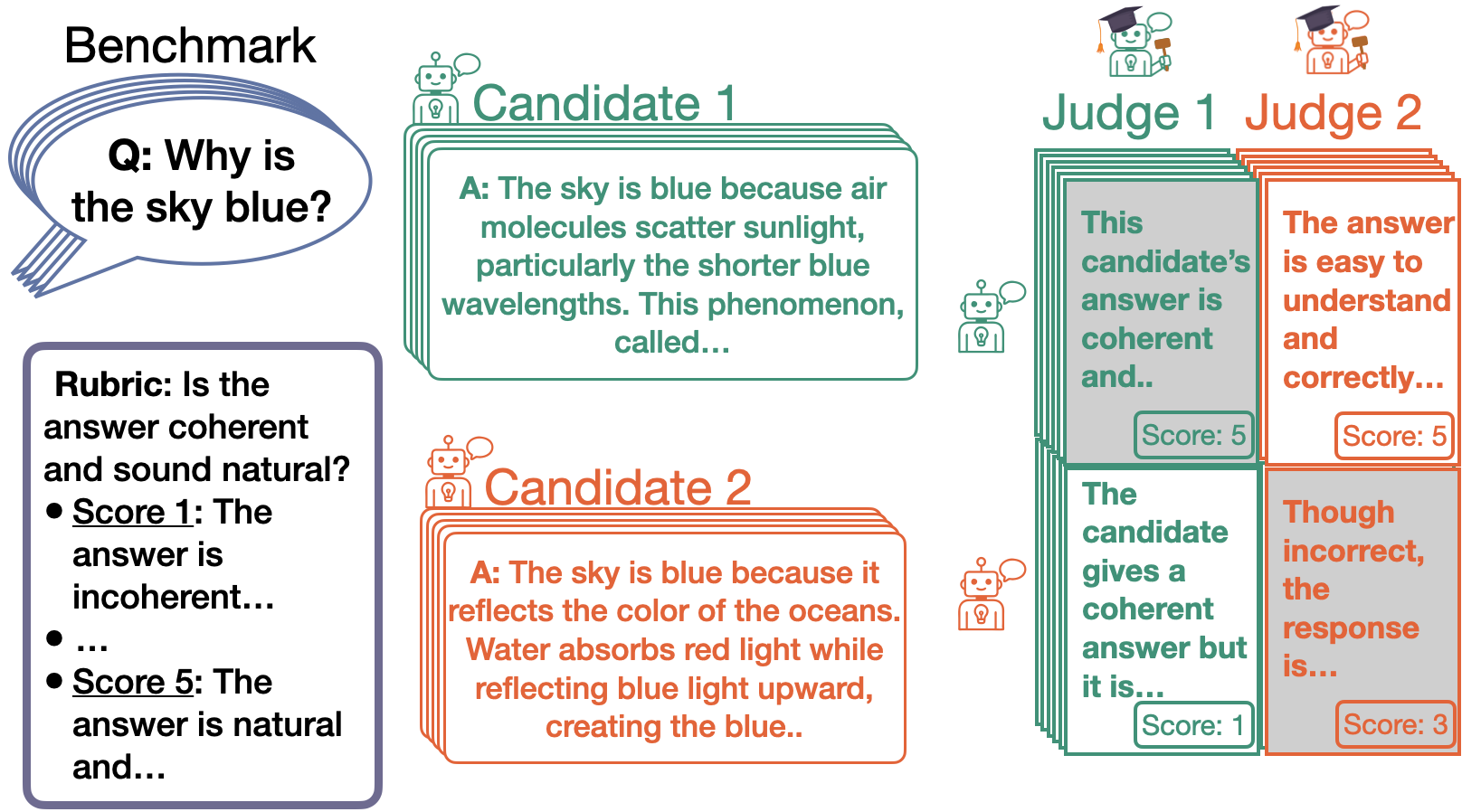
- 现有方法在评估LLMs输出时仅考虑随机不确定性,忽视了评判者质量的不确定性,导致评估结果的可靠性不足。
- 本文提出了一种几何视角,通过将评判者和候选者表示为概率单纯形上的点,设计了几何贝叶斯先验以编码评判质量的不确定性。
- 实验表明,基于LLM评判者的排名在多个数据集上表现出稳健性,且我们的贝叶斯方法在覆盖率上显著优于现有方法。
📝 摘要(中文)
针对自动评估大型语言模型(LLMs)自由形式输出的挑战,本文探讨了使用LLMs自身作为评判机制的有效性。现有方法仅考虑了采样变异性(随机不确定性),忽略了评判质量的不确定性(认知不确定性)。通过将LLM评判者和候选者视为概率单纯形上的点,本文提供了理论条件和可视化证明,阐明了何时排名是可识别的。实验结果表明,基于LLM评判者的排名在许多数据集上是稳健的,但也存在局限性。我们的贝叶斯方法在覆盖率上显著高于现有程序,强调了建模认知不确定性的重要性。
🔬 方法详解
问题定义:本文旨在解决如何有效评估大型语言模型(LLMs)输出的问题。现有方法仅关注随机不确定性,未能充分考虑评判者质量的认知不确定性,可能导致评估结果的不可靠性。
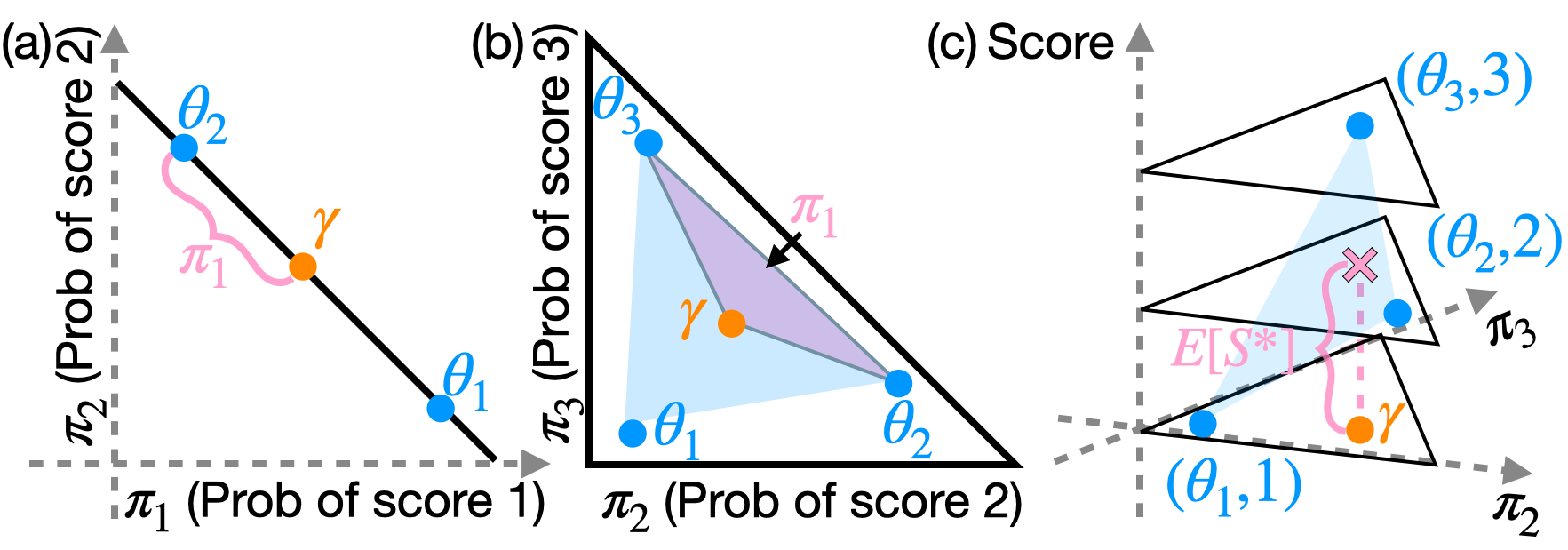
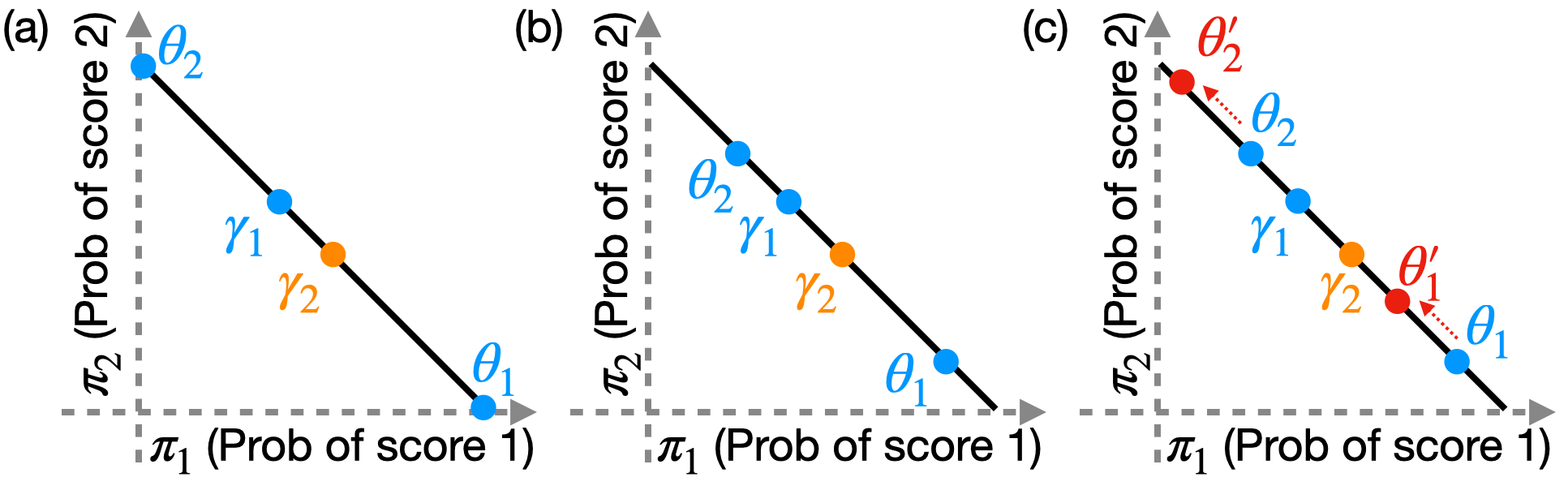
核心思路:论文提出了一种几何视角,将LLM评判者和候选者视为概率单纯形上的点,利用几何概念来分析排名的可识别性,并设计几何贝叶斯先验以处理评判质量的不确定性。
技术框架:整体框架包括将评判者和候选者映射到单纯形,利用几何方法分析排名的可识别性,并通过贝叶斯推断处理评判者质量的不确定性。主要模块包括数据映射、几何分析和贝叶斯推断。
关键创新:最重要的创新在于将评判者和候选者的评估视为几何问题,提供了理论基础和可视化证明,明确了在不同评分级别下评判者的有效性差异。
关键设计:设计了几何贝叶斯先验以编码评判者质量的不确定性,并进行了灵敏度分析。实验中使用的参数设置和损失函数经过精心选择,以确保模型的稳健性和准确性。
🖼️ 关键图片
📊 实验亮点
实验结果显示,基于LLM评判者的排名在多个数据集上表现出稳健性,尤其在二级评分(M=2)时效果显著优于多级评分(M>2)。我们的贝叶斯方法在覆盖率上比现有程序提高了显著比例,强调了认知不确定性建模的重要性。
🎯 应用场景
该研究的潜在应用领域包括自然语言处理中的模型评估、自动化内容生成和人机交互等。通过提供更可靠的评估机制,能够提升LLMs在实际应用中的表现和用户体验,未来可能对AI系统的评估标准产生深远影响。
📄 摘要(原文)
Given the challenge of automatically evaluating free-form outputs from large language models (LLMs), an increasingly common solution is to use LLMs themselves as the judging mechanism, without any gold-standard scores. Implicitly, this practice accounts for only sampling variability (aleatoric uncertainty) and ignores uncertainty about judge quality (epistemic uncertainty). While this is justified if judges are perfectly accurate, it is unclear when such an approach is theoretically valid and practically robust. We study these questions for the task of ranking LLM candidates from a novel geometric perspective: for $M$-level scoring systems, both LLM judges and candidates can be represented as points on an $(M-1)$-dimensional probability simplex, where geometric concepts (e.g., triangle areas) correspond to key ranking concepts. This perspective yields intuitive theoretical conditions and visual proofs for when rankings are identifiable; for instance, we provide a formal basis for the ``folk wisdom'' that LLM judges are more effective for two-level scoring ($M=2$) than multi-level scoring ($M>2$). Leveraging the simplex, we design geometric Bayesian priors that encode epistemic uncertainty about judge quality and vary the priors to conduct sensitivity analyses. Experiments on LLM benchmarks show that rankings based solely on LLM judges are robust in many but not all datasets, underscoring both their widespread success and the need for caution. Our Bayesian method achieves substantially higher coverage rates than existing procedures, highlighting the importance of modeling epistemic uncertainty.