Practical Adversarial Attacks on Stochastic Bandits via Fake Data Injection
作者: Qirun Zeng, Eric He, Richard Hoffmann, Xuchuang Wang, Jinhang Zuo
分类: cs.LG, cs.AI, cs.CR
发布日期: 2025-05-28 (更新: 2025-05-31)
💡 一句话要点
提出基于伪数据注入的随机Bandit算法对抗攻击方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 对抗攻击 随机Bandit算法 伪数据注入 UCB算法 Thompson Sampling算法
📋 核心要点
- 现有Bandit算法对抗攻击研究依赖不现实的假设,如无限扰动和逐轮奖励操控,脱离实际应用场景。
- 提出伪数据注入攻击模型,限制攻击者注入数据的数量和幅度,更贴近实际对抗环境。
- 实验证明,该攻击能有效误导UCB和Thompson Sampling算法,使其选择目标臂,揭示了算法的脆弱性。
📝 摘要(中文)
针对随机Bandit算法,传统对抗攻击依赖于不切实际的假设,如每轮奖励操纵和无界扰动,限制了其在实际系统中的应用。本文提出了一种更实际的威胁模型:伪数据注入,它反映了现实的对抗约束:攻击者只能将有限数量的有界伪反馈样本注入到学习者的历史中,模拟合法的交互。我们设计了该模型下的有效攻击策略,明确地解决了幅值约束(关于奖励值)和时间约束(关于何时以及多久可以注入数据)。理论分析表明,这些攻击可以误导UCB和Thompson Sampling算法在几乎所有轮次中选择目标臂,同时仅产生亚线性攻击成本。在合成和真实数据集上的实验验证了我们策略的有效性,揭示了在实际对抗场景中广泛使用的随机Bandit算法的显著漏洞。
🔬 方法详解
问题定义:论文旨在解决随机Bandit算法在实际对抗场景下的安全性问题。现有对抗攻击方法通常假设攻击者可以随意操纵每轮的奖励或施加无界的扰动,这在现实系统中往往是不成立的。实际场景中,攻击者可能只能注入有限数量的、幅度受限的伪造数据,例如虚假的用户反馈或传感器数据。因此,如何在这种更实际的威胁模型下有效地攻击Bandit算法是一个重要的挑战。
核心思路:论文的核心思路是设计一种伪数据注入策略,通过在学习者的历史数据中插入精心构造的伪造反馈样本,来影响算法对各个臂的奖励估计,从而诱导算法选择攻击者期望的目标臂。这种策略需要同时考虑注入数据的幅值限制(奖励值不能超过某个范围)和时间限制(注入数据的频率和时间点需要合理),以避免被检测为异常。
技术框架:该攻击框架主要包含以下几个阶段:1) 目标臂选择:攻击者首先确定要攻击的目标臂。2) 伪数据生成:根据目标臂的特性和算法的内在机制(如UCB或Thompson Sampling),生成能够有效影响算法决策的伪造数据。这些数据需要满足幅值和时间约束。3) 数据注入:将生成的伪造数据注入到学习者的历史数据中,模拟真实的交互过程。4) 算法评估:评估攻击效果,即算法选择目标臂的频率。如果攻击效果不理想,可以调整伪数据生成策略。
关键创新:该论文的关键创新在于提出了一个更贴近实际的对抗模型——伪数据注入,并针对该模型设计了有效的攻击策略。与传统的对抗攻击方法相比,该方法考虑了幅值和时间约束,使得攻击更难被检测,也更具有实际意义。此外,论文还对攻击策略进行了理论分析,证明了其在亚线性攻击成本下能够有效误导算法。
关键设计:在伪数据生成方面,论文针对UCB和Thompson Sampling算法分别设计了不同的策略。对于UCB算法,攻击者可以通过注入高奖励的伪数据来提高目标臂的置信上界,使其更容易被选择。对于Thompson Sampling算法,攻击者可以通过注入符合目标臂奖励分布的伪数据来改变算法的后验分布,从而增加目标臂被采样的概率。关键参数包括注入数据的数量、幅值和时间点。这些参数需要根据具体的算法和数据集进行调整,以达到最佳的攻击效果。
🖼️ 关键图片
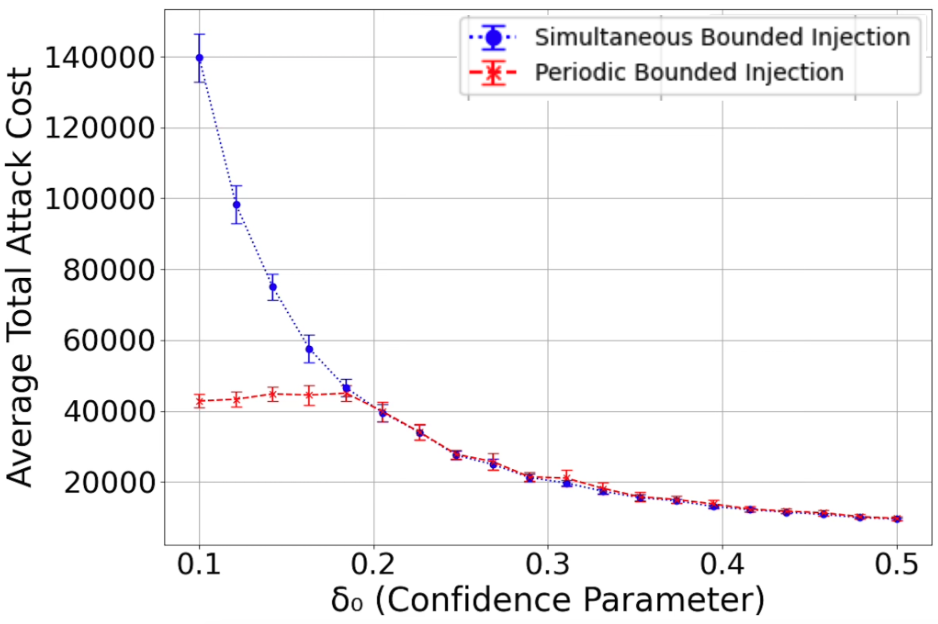
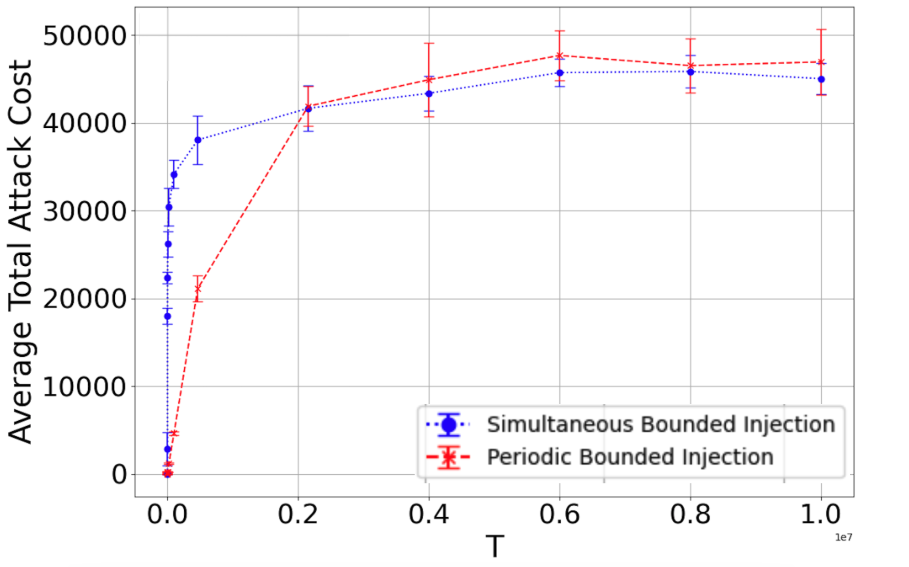
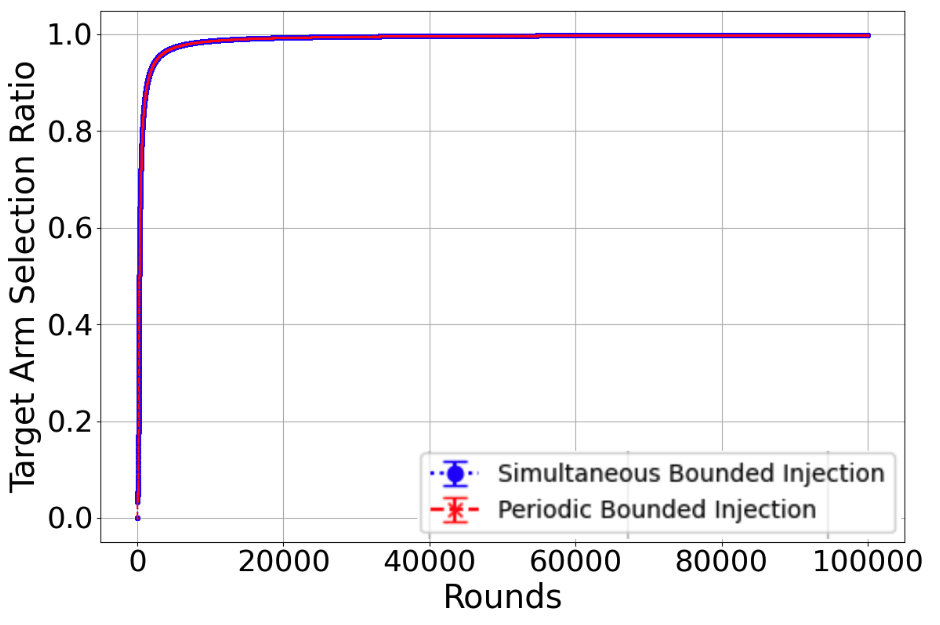
📊 实验亮点
实验结果表明,所提出的伪数据注入攻击策略能够有效地误导UCB和Thompson Sampling算法。在合成数据集上,攻击者可以在仅注入少量伪数据的情况下,使算法在几乎所有轮次中选择目标臂。在真实数据集上,攻击也取得了显著的效果,证明了该攻击策略的有效性和实用性。攻击成本保持在亚线性级别。
🎯 应用场景
该研究成果可应用于评估和增强推荐系统、在线广告、医疗诊断等领域中Bandit算法的安全性。通过模拟实际的对抗场景,可以发现算法的潜在漏洞,并开发相应的防御机制,提高系统的鲁棒性和可靠性。未来的研究可以进一步探索更复杂的攻击策略和更有效的防御方法。
📄 摘要(原文)
Adversarial attacks on stochastic bandits have traditionally relied on some unrealistic assumptions, such as per-round reward manipulation and unbounded perturbations, limiting their relevance to real-world systems. We propose a more practical threat model, Fake Data Injection, which reflects realistic adversarial constraints: the attacker can inject only a limited number of bounded fake feedback samples into the learner's history, simulating legitimate interactions. We design efficient attack strategies under this model, explicitly addressing both magnitude constraints (on reward values) and temporal constraints (on when and how often data can be injected). Our theoretical analysis shows that these attacks can mislead both Upper Confidence Bound (UCB) and Thompson Sampling algorithms into selecting a target arm in nearly all rounds while incurring only sublinear attack cost. Experiments on synthetic and real-world datasets validate the effectiveness of our strategies, revealing significant vulnerabilities in widely used stochastic bandit algorithms under practical adversarial scenarios.