Reinforcement Learning for Out-of-Distribution Reasoning in LLMs: An Empirical Study on Diagnosis-Related Group Coding
作者: Hanyin Wang, Zhenbang Wu, Gururaj Kolar, Hariprasad Korsapati, Brian Bartlett, Bryan Hull, Jimeng Sun
分类: cs.LG, cs.AI
发布日期: 2025-05-28 (更新: 2025-10-14)
💡 一句话要点
提出DRG-Sapphire,利用强化学习解决LLM在DRG编码中的分布外推理难题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 分布外推理 DRG编码 监督微调
📋 核心要点
- LLM在DRG编码任务中面临分布外推理的挑战,因为预训练数据缺乏相关的临床和计费信息。
- DRG-Sapphire利用大规模强化学习,结合规则奖励和Group Relative Policy Optimization,提升DRG编码的准确性和可解释性。
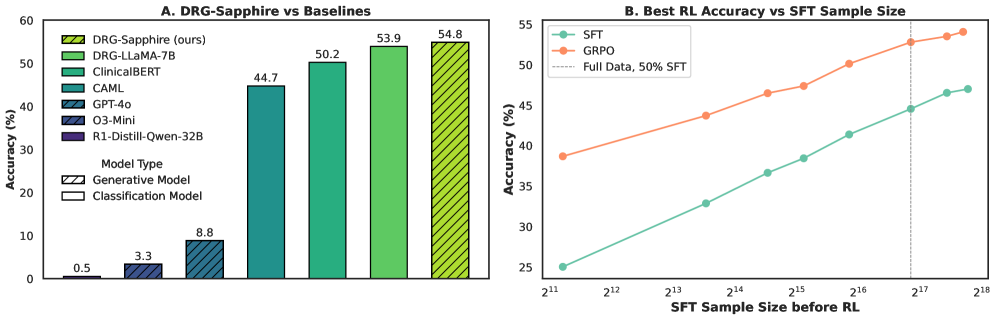
- 实验表明,DRG-Sapphire在MIMIC-IV基准测试中达到SOTA,并验证了SFT对OOD任务中RL性能的重要性。
📝 摘要(中文)
诊断相关组(DRG)编码对医院报销和运营至关重要,但需要大量人工。大型语言模型(LLM)在DRG编码方面表现不佳,因为该任务具有分布外(OOD)的性质:预训练语料库很少包含私有的临床或计费数据。我们引入了DRG-Sapphire,它使用大规模强化学习(RL)从临床笔记中自动进行DRG编码。DRG-Sapphire基于Qwen2.5-7B,并使用基于规则的奖励通过Group Relative Policy Optimization (GRPO)进行训练,引入了一系列RL增强功能,以解决先前数学任务中未见的特定领域挑战。我们的模型在MIMIC-IV基准测试中实现了最先进的准确性,并生成了医生验证的DRG分配推理,从而显著提高了可解释性。我们的研究进一步揭示了将RL应用于知识密集型OOD任务的更广泛挑战。我们观察到,RL性能与监督微调(SFT)示例数量的对数大致呈线性关系,这表明RL的有效性从根本上受到基础模型中编码的领域知识的限制。对于像DRG编码这样的OOD任务,强大的RL性能需要在RL之前注入足够的知识。因此,对于此类任务,扩展SFT可能比单独扩展RL更有效且计算效率更高。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在诊断相关组(DRG)编码任务中的表现不佳问题。DRG编码是医院报销和运营的关键环节,但现有LLM由于预训练数据中缺乏相关的临床和计费数据,导致在处理此类分布外(OOD)任务时效果不佳。现有方法依赖人工编码,效率低且成本高。
核心思路:论文的核心思路是利用强化学习(RL)来提升LLM在DRG编码任务中的OOD推理能力。通过强化学习,模型可以从与DRG编码相关的规则和奖励中学习,从而弥补预训练数据不足的缺陷。此外,论文强调了在进行强化学习之前,通过监督微调(SFT)注入足够的领域知识的重要性。
技术框架:DRG-Sapphire的整体框架包括以下几个主要阶段:1) 基于Qwen2.5-7B构建基础模型;2) 使用监督微调(SFT)注入领域知识;3) 使用Group Relative Policy Optimization (GRPO)进行强化学习,利用规则奖励来指导模型的学习过程;4) 生成医生验证的推理过程,提高模型的可解释性。
关键创新:论文的关键创新点在于将大规模强化学习应用于DRG编码这一知识密集型的OOD任务,并提出了一系列针对该领域特定挑战的RL增强方法。此外,论文还揭示了SFT在OOD任务中对RL性能的重要性,强调了在进行强化学习之前注入足够领域知识的必要性。
关键设计:DRG-Sapphire使用了Group Relative Policy Optimization (GRPO)作为强化学习算法,并设计了基于规则的奖励函数,以指导模型的学习过程。具体的技术细节包括:奖励函数的具体形式、GRPO算法的参数设置、以及如何利用医生验证的推理过程来进一步提升模型的可解释性。论文还分析了SFT样本数量与RL性能之间的关系,发现RL性能与SFT样本数量的对数大致呈线性关系。
🖼️ 关键图片


📊 实验亮点
DRG-Sapphire在MIMIC-IV基准测试中取得了最先进的准确性,显著优于现有的LLM方法。此外,该模型能够生成医生验证的推理过程,提高了DRG编码的可解释性。研究还发现,RL性能与SFT样本数量的对数大致呈线性关系,表明在OOD任务中,SFT对RL性能至关重要。
🎯 应用场景
DRG-Sapphire具有广泛的应用前景,可用于医院的自动化DRG编码,降低人工成本,提高编码效率和准确性。此外,该研究的方法和结论也适用于其他知识密集型的OOD任务,例如法律文件分析、金融报告解读等。未来,可以进一步探索如何将DRG-Sapphire与其他医疗信息系统集成,实现更智能化的医疗服务。
📄 摘要(原文)
Diagnosis-Related Group (DRG) codes are essential for hospital reimbursement and operations but require labor-intensive assignment. Large Language Models (LLMs) struggle with DRG coding due to the out-of-distribution (OOD) nature of the task: pretraining corpora rarely contain private clinical or billing data. We introduce DRG-Sapphire, which uses large-scale reinforcement learning (RL) for automated DRG coding from clinical notes. Built on Qwen2.5-7B and trained with Group Relative Policy Optimization (GRPO) using rule-based rewards, DRG-Sapphire introduces a series of RL enhancements to address domain-specific challenges not seen in previous mathematical tasks. Our model achieves state-of-the-art accuracy on the MIMIC-IV benchmark and generates physician-validated reasoning for DRG assignments, significantly enhancing explainability. Our study further sheds light on broader challenges of applying RL to knowledge-intensive, OOD tasks. We observe that RL performance scales approximately linearly with the logarithm of the number of supervised fine-tuning (SFT) examples, suggesting that RL effectiveness is fundamentally constrained by the domain knowledge encoded in the base model. For OOD tasks like DRG coding, strong RL performance requires sufficient knowledge infusion prior to RL. Consequently, scaling SFT may be more effective and computationally efficient than scaling RL alone for such tasks.