LaX: Boosting Low-Rank Training of Foundation Models via Latent Crossing
作者: Ruijie Zhang, Ziyue Liu, Zhengyang Wang, Zheng Zhang
分类: cs.LG
发布日期: 2025-05-27 (更新: 2025-10-24)
💡 一句话要点
提出LaX模块,通过潜在空间交叉提升低秩模型在预训练和微调中的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 低秩训练 基础模型 参数高效 潜在空间交叉 模型压缩
📋 核心要点
- 现有低秩矩阵分解方法虽然参数效率高,但因参数空间受限,导致模型性能下降。
- LaX通过允许低秩子空间之间的信息交互,增强低秩模型的表达能力,从而提升性能。
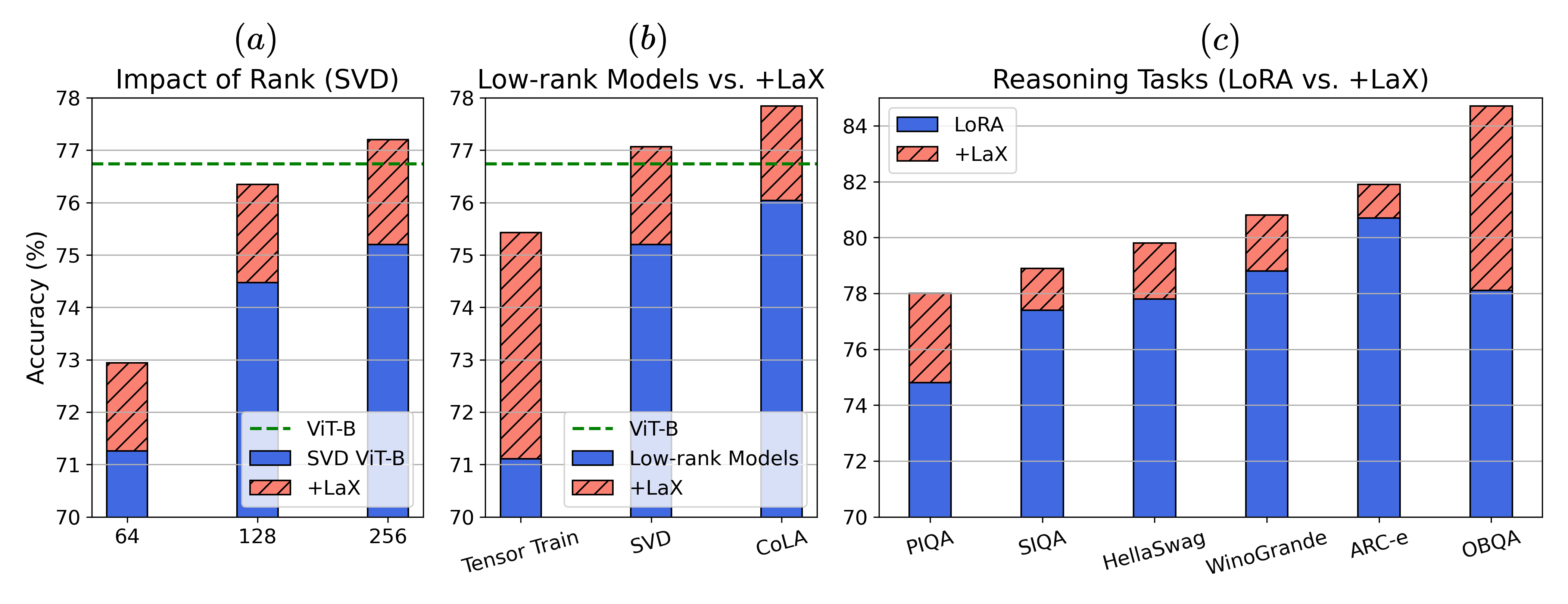
- 实验表明,LaX能使低秩模型在预训练和微调任务中达到甚至超过全秩模型的性能,同时显著减少参数量。
📝 摘要(中文)
训练诸如ViT和LLM等基础模型需要巨大的计算成本。低秩矩阵或张量分解提供了一种参数高效的替代方案,但由于参数空间的限制,通常会降低性能。本文提出了一种简单而有效的即插即用模块——潜在交叉(LaX),通过实现低秩子空间之间的信息流动来增强低秩模型的能力。在ViT-Base/Large和参数量从60M到1B的类LLaMA模型上的预训练任务中,LaX的优势得到了广泛验证。LaX提高了低秩模型的性能,使其达到或超过了全秩基线,同时使用的参数减少了2-3倍。当配备低秩适配器(即LoRA)用于微调LLaMA-7/13B时,LaX在算术和常识推理任务上始终如一地提高了性能,且成本可忽略不计。
🔬 方法详解
问题定义:论文旨在解决低秩模型在参数效率和性能之间的trade-off问题。现有低秩方法虽然减少了参数量,但由于其受限的参数空间,通常会导致模型性能显著下降,无法达到全秩模型的性能水平。因此,如何在保持参数效率的同时,提升低秩模型的表达能力是一个关键挑战。
核心思路:论文的核心思路是通过引入“潜在交叉”(Latent Crossing)机制,允许低秩子空间之间进行信息交互。这种交互能够增强低秩模型的表达能力,使其能够学习到更复杂的特征表示,从而弥补因低秩分解带来的性能损失。LaX的设计目标是在不显著增加计算成本的前提下,提升低秩模型的性能。
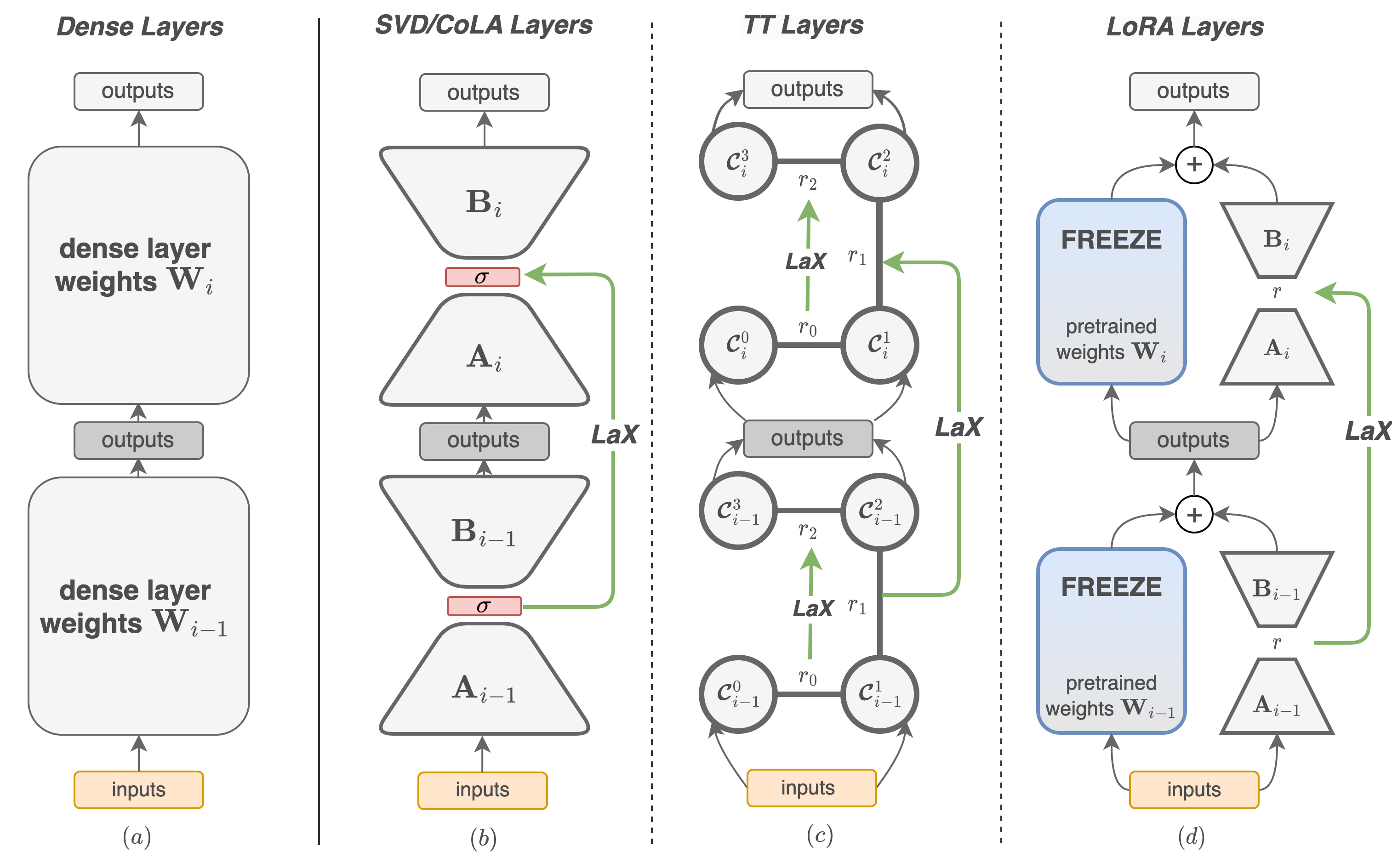
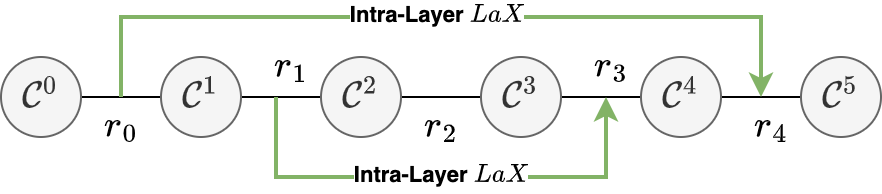
技术框架:LaX是一个即插即用的模块,可以方便地集成到现有的低秩模型中。其基本流程是:首先,将输入数据投影到多个低秩子空间;然后,在这些低秩子空间之间进行交叉操作,以实现信息共享;最后,将交叉后的信息重新组合,得到最终的输出。该模块可以被添加到Transformer模型的不同层中,例如注意力层或前馈网络层。
关键创新:LaX的关键创新在于其潜在空间交叉机制。与传统的低秩方法不同,LaX不是简单地对原始矩阵进行低秩分解,而是通过允许不同低秩子空间之间的信息交互,来增强模型的表达能力。这种交叉机制能够捕捉到不同子空间之间的相关性,从而学习到更丰富的特征表示。
关键设计:LaX的关键设计包括:1) 如何选择合适的低秩维度;2) 如何设计有效的交叉操作。论文中可能探讨了不同的低秩维度选择策略,以及不同的交叉操作实现方式,例如线性组合、非线性变换等。此外,损失函数的设计也可能考虑了如何鼓励不同子空间之间的信息共享,例如通过引入正则化项来约束子空间之间的相关性。
🖼️ 关键图片
📊 实验亮点
LaX在ViT-Base/Large和类LLaMA模型上的预训练任务中表现出色,能够在参数量减少2-3倍的情况下,达到或超过全秩模型的性能。在微调LLaMA-7/13B时,LaX与LoRA结合,在算术和常识推理任务上始终如一地提高了性能,且计算成本几乎没有增加。这些实验结果表明,LaX是一种有效的低秩模型增强方法。
🎯 应用场景
LaX具有广泛的应用前景,尤其是在资源受限的场景下。例如,它可以用于在移动设备或边缘设备上部署大型语言模型,或者用于在计算资源有限的实验室中进行基础模型的研究。此外,LaX还可以应用于各种需要参数高效模型的任务,例如图像识别、自然语言处理等。通过LaX,可以在保持模型性能的同时,显著降低计算成本和存储需求。
📄 摘要(原文)
Training foundation models such as ViTs and LLMs requires tremendous computing cost. Low-rank matrix or tensor factorization offers a parameter-efficient alternative, but often downgrades performance due to the restricted parameter space. In this work, we introduce {\textbf{Latent Crossing (LaX)}} -- a simple yet effective plug-and-play module that enhances the capacity of low-rank models by enabling information flow across low-rank subspaces. We extensively validate the benefits of LaX on pre-training tasks with ViT-Base/Large and LLaMA-like models ranging from 60M to 1B parameters. LaX boosts low-rank model performance to match or exceed the full-rank baselines while using 2-3(\times) fewer parameters. When equipped with low-rank adapters (i.e., LoRA) for fine-tuning LLaMA-7/13B, LaX consistently improves performance on arithmetic and common sense reasoning tasks with negligible cost.