Breaking AR's Sampling Bottleneck: Provable Acceleration via Diffusion Language Models
作者: Gen Li, Changxiao Cai
分类: cs.LG, cs.IT, math.ST, stat.ML
发布日期: 2025-05-27 (更新: 2026-01-08)
备注: This is the full version of a paper published at NeurIPS 2025
💡 一句话要点
利用扩散语言模型加速AR采样:可证明的加速框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 扩散模型 语言模型 文本生成 并行采样 信息论
📋 核心要点
- 自回归模型生成文本受限于从左到右的顺序约束,采样效率低。
- 论文提出利用扩散模型并行采样的特性,突破自回归模型的采样瓶颈。
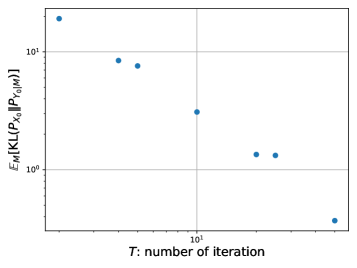
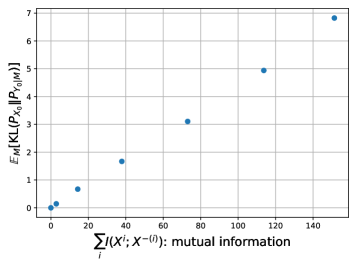
- 论文从信息论角度证明了扩散语言模型的收敛性,并给出了采样误差的上下界。
📝 摘要(中文)
扩散模型已成为现代生成建模的强大范例,并在大型语言模型(LLM)中展现出强大的潜力。与传统的自回归(AR)模型按顺序生成token不同,扩散模型允许并行采样,从而为加速生成和消除从左到右的生成约束提供了一条有希望的途径。尽管扩散语言模型在经验上取得了成功,但对其理论理解仍然不充分。本文从信息论的角度为扩散语言模型建立了收敛性保证。我们的分析表明,采样误差(以Kullback-Leibler(KL)散度衡量)与迭代次数T成反比衰减,并与目标文本序列中token之间的互信息成线性比例。重要的是,我们的理论涵盖了T<L的情况,其中L是文本序列的长度。这证明了可以用少于L的迭代次数生成高质量的样本,从而打破了AR模型所需的L步的基本采样瓶颈。我们进一步建立了匹配的上限和下限(直到某个常数因子),表明了我们的收敛分析的紧密性。这些结果为扩散语言模型的实际有效性提供了新的理论见解。
🔬 方法详解
问题定义:论文旨在解决自回归(AR)语言模型在文本生成过程中存在的采样瓶颈问题。传统的AR模型需要按顺序逐个生成token,这导致生成速度慢,尤其是在处理长文本序列时。现有的AR模型难以实现并行生成,效率提升受限。
核心思路:论文的核心思路是利用扩散模型进行文本生成,因为扩散模型允许并行采样。通过将文本生成过程建模为扩散过程,可以同时生成多个token,从而显著加速生成过程。此外,论文还从理论上分析了扩散语言模型的收敛性,为该方法的有效性提供了理论支撑。
技术框架:论文的技术框架主要包括以下几个部分:1)将文本生成问题转化为扩散过程;2)设计合适的扩散模型架构,用于文本数据的生成;3)从信息论的角度分析扩散语言模型的收敛性,推导出采样误差的上下界;4)通过实验验证理论分析的正确性和方法的有效性。
关键创新:论文的关键创新在于:1)首次从理论上分析了扩散语言模型在文本生成中的收敛性,并给出了采样误差的上下界;2)证明了扩散模型可以在少于文本序列长度的迭代次数内生成高质量的样本,从而突破了AR模型的采样瓶颈;3)为扩散模型在自然语言处理领域的应用提供了新的理论依据。
关键设计:论文的关键设计包括:1)选择合适的扩散模型架构,例如去噪扩散概率模型(DDPM),并针对文本数据进行调整;2)设计合适的损失函数,用于训练扩散模型,例如变分下界(VLB);3)选择合适的采样策略,例如DDIM,以加速采样过程;4)针对文本序列的离散特性,设计合适的噪声添加和去除策略。
🖼️ 关键图片
📊 实验亮点
论文从信息论角度证明了扩散语言模型的收敛性,并给出了采样误差的上下界。理论分析表明,采样误差与迭代次数成反比,与token之间的互信息成正比。更重要的是,论文证明了扩散模型可以在少于文本序列长度的迭代次数内生成高质量的样本,从而突破了AR模型的采样瓶颈。这些理论结果为扩散语言模型的实际应用提供了有力的支持。
🎯 应用场景
该研究成果可应用于各种需要快速文本生成的场景,例如机器翻译、文本摘要、对话生成等。通过利用扩散模型进行并行采样,可以显著提高文本生成的效率,从而提升用户体验。此外,该研究的理论分析为扩散模型在自然语言处理领域的应用提供了新的指导,有助于推动相关技术的发展。
📄 摘要(原文)
Diffusion models have emerged as a powerful paradigm for modern generative modeling, demonstrating strong potential for large language models (LLMs). Unlike conventional autoregressive (AR) models that generate tokens sequentially, diffusion models allow for parallel sampling, offering a promising path to accelerate generation and eliminate the left-to-right generation constraints. Despite their empirical success, theoretical understandings of diffusion language models remain underdeveloped. In this work, we develop convergence guarantees for diffusion language models from an information-theoretic perspective. Our analysis demonstrates that the sampling error, measured by the Kullback-Leibler (KL) divergence, decays inversely with the number of iterations $T$ and scales linearly with the mutual information between tokens in the target text sequence. Crucially, our theory covers the regime $T<L$, where $L$ is the text sequence length. This justifies that high-quality samples can be generated with fewer iterations than $L$, thereby breaking the fundamental sampling bottleneck of $L$ steps required by AR models. We further establish matching upper and lower bounds, up to some constant factor, that shows the tightness of our convergence analysis. These results offer novel theoretical insights into the practical effectiveness of diffusion language models.