Towards Interpretability Without Sacrifice: Faithful Dense Layer Decomposition with Mixture of Decoders
作者: James Oldfield, Shawn Im, Sharon Li, Mihalis A. Nicolaou, Ioannis Patras, Grigorios G Chrysos
分类: cs.LG, cs.AI
发布日期: 2025-05-27 (更新: 2026-01-14)
备注: NeurIPS 2025 camera-ready version
🔗 代码/项目: GITHUB
💡 一句话要点
提出混合解码器(MxDs),实现语言模型中稠密层的忠实且可解释分解。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 可解释性 语言模型 稀疏化 模型分解 混合解码器 层级稀疏性 张量分解
📋 核心要点
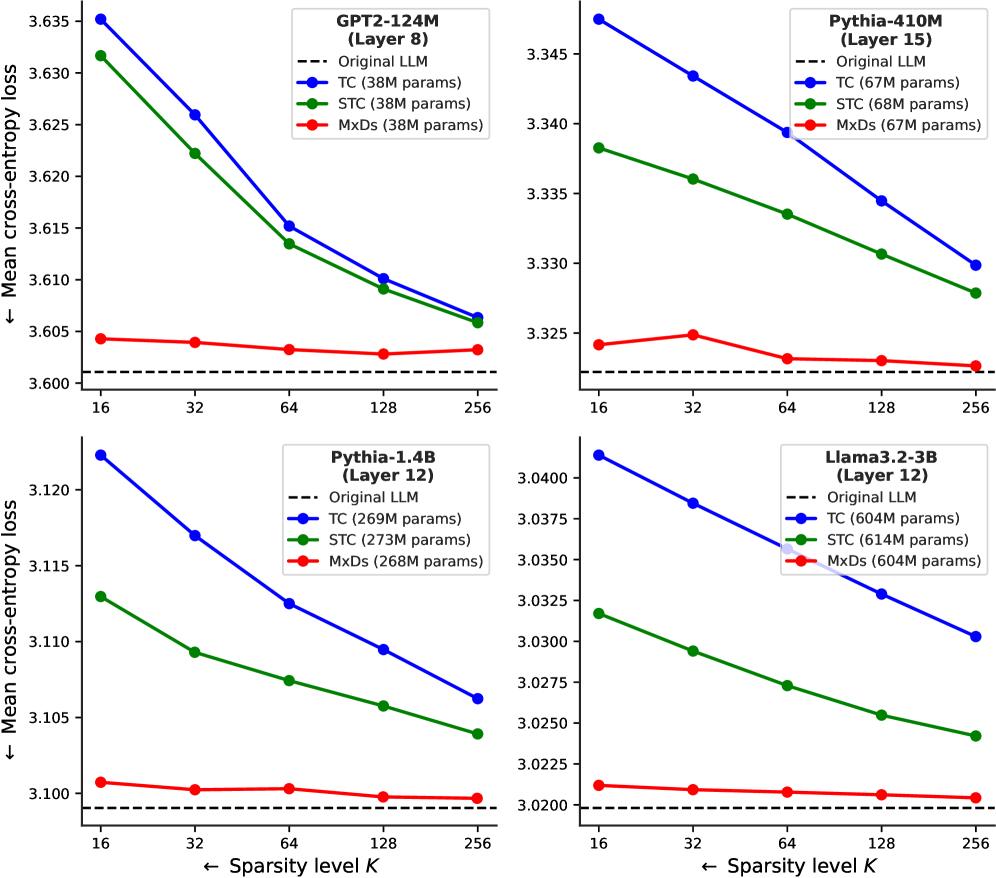
- 现有方法通过神经元稀疏化近似MLP,但牺牲了模型精度,导致交叉熵损失显著增加。
- 提出混合解码器(MxDs),通过层级稀疏化,将稠密层分解为大量专门的子层,保持表达能力。
- 实验表明,MxDs在稀疏性-精度权衡方面优于现有方法,并学习到自然语言的专门特征。
📝 摘要(中文)
多层感知机(MLP)是大型语言模型不可或缺的一部分,但其稠密表示使其难以理解、编辑和引导。最近的方法通过神经元级别的稀疏性来学习可解释的近似,但未能忠实地重建原始映射,从而显著增加了模型的下一个token交叉熵损失。本文提倡转向层级稀疏性,以克服稀疏层近似中的精度权衡。在此范式下,我们引入了混合解码器(MxDs)。MxDs推广了MLP和门控线性单元,将预训练的稠密层扩展到数万个专门的子层。通过一种灵活的张量分解形式,每个稀疏激活的MxD子层都实现了一个具有全秩权重的线性变换,即使在高度稀疏的情况下也能保持原始解码器的表达能力。实验表明,在参数高达3B的语言模型中,MxDs在稀疏性-精度方面显著优于最先进的方法(例如,Transcoders)。对稀疏探测和特征引导的进一步评估表明,MxDs学习了自然语言的类似专门的特征,为设计可解释但忠实的分解开辟了一条有希望的新途径。我们的代码已包含在:https://github.com/james-oldfield/MxD/。
🔬 方法详解
问题定义:现有大型语言模型中的多层感知机(MLP)层由于其稠密的表示,难以理解、编辑和控制。虽然一些方法尝试通过神经元级别的稀疏化来提高可解释性,但这些方法通常会牺牲模型的准确性,导致性能显著下降。因此,如何在保证模型精度的前提下,提高MLP层的可解释性是一个关键问题。
核心思路:本文的核心思路是采用层级稀疏化的方法,将MLP层分解为多个专门的子层,每个子层负责处理特定的特征或模式。通过这种方式,可以实现对MLP层的细粒度控制和理解,同时避免因过度稀疏化而导致的精度损失。这种分解方式允许模型在保持整体表达能力的同时,实现更高的可解释性。
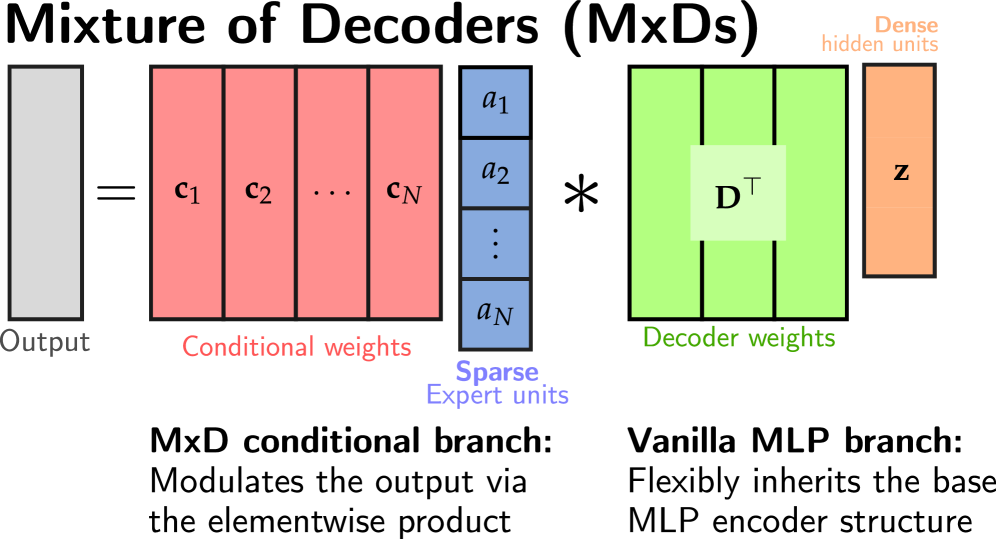
技术框架:MxDs的核心在于将一个稠密的MLP层分解为多个稀疏激活的子层,每个子层被称为一个解码器。整体框架包含以下几个主要步骤:1) 将预训练的稠密层扩展为数万个专门的子层;2) 通过一种灵活的张量分解形式,每个稀疏激活的MxD子层实现一个具有全秩权重的线性变换;3) 通过稀疏门控机制,控制每个子层的激活,使得只有少数子层参与到每次前向传播中。
关键创新:该方法最重要的创新点在于从神经元级别的稀疏化转向了层级别的稀疏化。与传统的神经元稀疏化方法相比,层级别的稀疏化能够更好地保持模型的表达能力,避免因过度稀疏化而导致的精度损失。此外,MxDs采用了一种灵活的张量分解形式,使得每个子层都能够学习到不同的特征或模式,从而提高了模型的可解释性。
关键设计:MxDs的关键设计包括:1) 子层的数量:需要根据具体的任务和数据集进行调整,以达到最佳的稀疏性-精度权衡;2) 稀疏门控机制:用于控制每个子层的激活,可以使用不同的门控函数,例如sigmoid或softmax;3) 损失函数:除了传统的交叉熵损失外,还可以添加一些正则化项,例如L1正则化,以进一步提高稀疏性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在参数高达3B的语言模型中,MxDs在稀疏性-精度方面显著优于最先进的方法(例如,Transcoders)。具体来说,MxDs能够在保持与原始模型相近的精度水平下,实现更高的稀疏度。此外,对稀疏探测和特征引导的进一步评估表明,MxDs学习了自然语言的类似专门的特征。
🎯 应用场景
该研究成果可应用于提升大型语言模型的可解释性和可控性,例如,通过编辑或引导特定的子层,可以实现对模型行为的干预和定制。此外,该方法还可以用于模型压缩和加速,通过去除不重要的子层,可以减小模型的大小和计算复杂度。该技术在自然语言处理、智能对话系统等领域具有广泛的应用前景。
📄 摘要(原文)
Multilayer perceptrons (MLPs) are an integral part of large language models, yet their dense representations render them difficult to understand, edit, and steer. Recent methods learn interpretable approximations via neuron-level sparsity, yet fail to faithfully reconstruct the original mapping--significantly increasing model's next-token cross-entropy loss. In this paper, we advocate for moving to layer-level sparsity to overcome the accuracy trade-off in sparse layer approximation. Under this paradigm, we introduce Mixture of Decoders (MxDs). MxDs generalize MLPs and Gated Linear Units, expanding pre-trained dense layers into tens of thousands of specialized sublayers. Through a flexible form of tensor factorization, each sparsely activating MxD sublayer implements a linear transformation with full-rank weights--preserving the original decoders' expressive capacity even under heavy sparsity. Experimentally, we show that MxDs significantly outperform state-of-the-art methods (e.g., Transcoders) on the sparsity-accuracy frontier in language models with up to 3B parameters. Further evaluations on sparse probing and feature steering demonstrate that MxDs learn similarly specialized features of natural language--opening up a promising new avenue for designing interpretable yet faithful decompositions. Our code is included at: https://github.com/james-oldfield/MxD/.