Towards Robust Assessment of Pathological Voices via Combined Low-Level Descriptors and Foundation Model Representations
作者: Whenty Ariyanti, Kuan-Yu Chen, Sabato Marco Siniscalchi, Hsin-Min Wang, Yu Tsao
分类: cs.SD, cs.LG, eess.AS
发布日期: 2025-05-27 (更新: 2025-12-11)
💡 一句话要点
提出VOQANet+,结合底层声学特征与语音基础模型表征,提升病理嗓音评估的鲁棒性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 病理嗓音评估 语音质量评估 语音基础模型 深度学习 声学特征
📋 核心要点
- 传统病理嗓音评估依赖专家主观评价,存在评估者间差异,缺乏客观性。
- VOQANet+结合语音基础模型嵌入和底层声学特征,利用深度学习框架进行语音质量评估。
- 实验表明,VOQANet+在噪声环境下表现出更强的鲁棒性,且句子级别评估优于元音级别。
📝 摘要(中文)
感知语音质量评估在诊断和监测语音障碍中起着至关重要的作用。传统方法,如语音共识听觉感知评估(CAPE-V)和等级、粗糙度、气息声、无力感和紧张度(GRBAS)量表,依赖于专家评估者,容易出现评估者间差异,因此需要客观的解决方案。本研究引入了语音质量评估网络(VOQANet),这是一种深度学习框架,它采用注意力机制和语音基础模型(SFM)嵌入来提取高层特征。为了进一步提高性能,我们提出了VOQANet+,它将自监督SFM嵌入与低层声学描述符(即抖动、闪烁和谐波噪声比(HNR))相结合。与之前仅关注基于元音的发声的方法(PVQD-A)不同,我们的模型在元音级别和句子级别的语音(PVQD-S)上进行评估,以评估泛化能力。实验结果表明,基于句子的输入产生更高的准确率,尤其是在患者级别。总体而言,VOQANet在CAPE-V和GRBAS维度上的均方根误差(RMSE)和Pearson相关系数方面始终优于基线模型,而VOQANet+实现了更大的性能提升。此外,VOQANet+在噪声条件下保持一致的性能,表明增强了在现实世界和远程医疗应用中的鲁棒性。这项工作突出了结合SFM嵌入和低层特征对于准确和鲁棒的病理嗓音评估的价值。
🔬 方法详解
问题定义:论文旨在解决病理嗓音评估中主观性强、鲁棒性差的问题。现有方法依赖专家听觉感知,易受主观因素影响,且在噪声环境下性能下降。
核心思路:论文的核心思路是将语音基础模型(SFM)提取的高层语义特征与传统的低层声学特征相结合,利用深度学习模型自动学习语音质量的评估标准。这种结合旨在利用SFM的泛化能力和低层特征的细节信息,提高评估的准确性和鲁棒性。
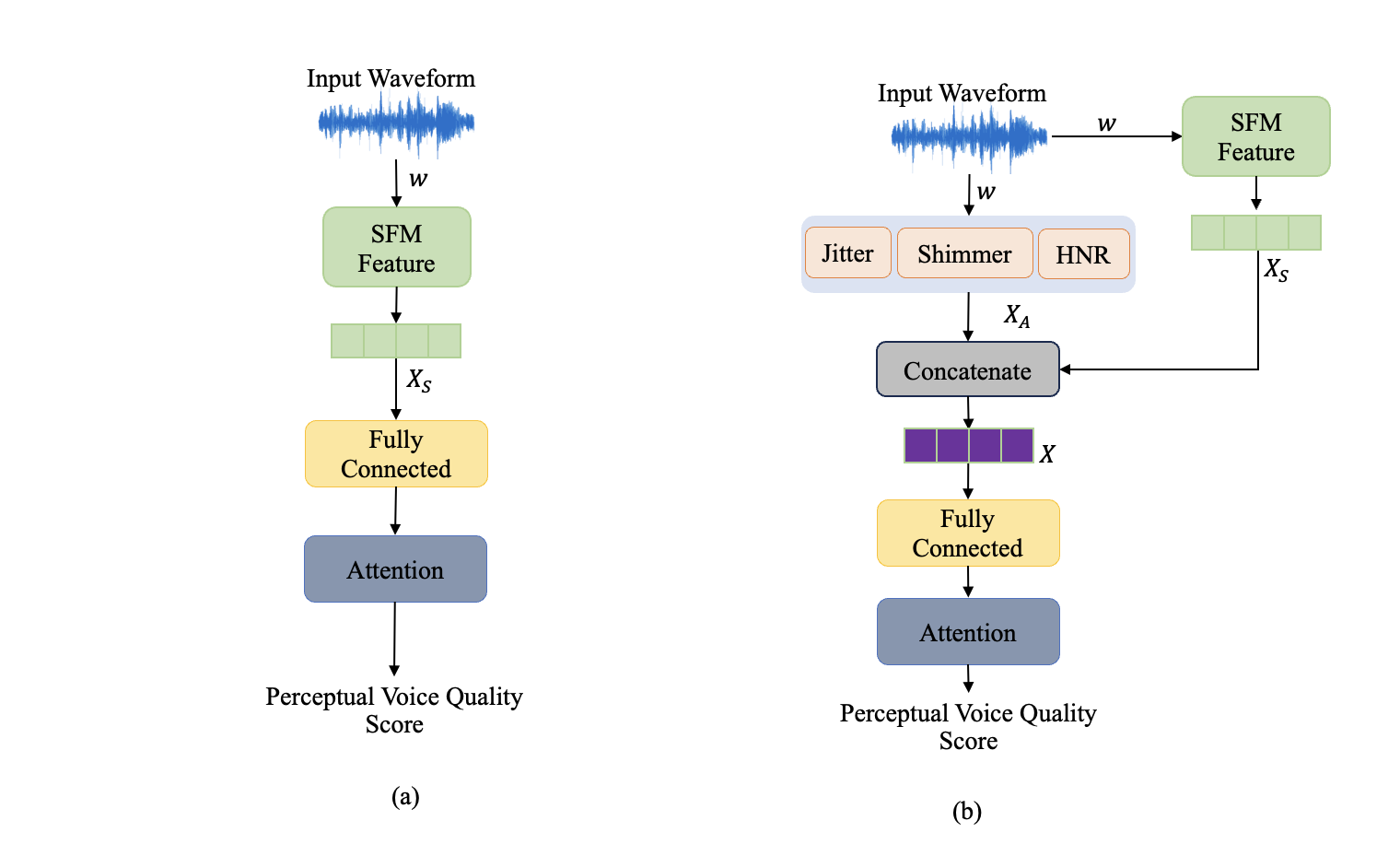
技术框架:VOQANet+模型主要包含以下几个模块:1) 语音输入:可以是元音级别的语音片段或句子级别的语音;2) 特征提取:利用预训练的语音基础模型提取语音嵌入,并计算抖动、闪烁和HNR等低层声学特征;3) 特征融合:将SFM嵌入和低层特征进行拼接或加权融合;4) 语音质量评估网络:使用深度神经网络(如带有注意力机制的循环神经网络或Transformer)对融合后的特征进行处理,预测CAPE-V和GRBAS等语音质量指标。
关键创新:论文的关键创新在于将自监督学习的语音基础模型(SFM)引入到病理嗓音评估中,并将其与传统的低层声学特征相结合。这种结合方式能够充分利用SFM的强大表征能力和低层特征的细节信息,从而提高评估的准确性和鲁棒性。与现有方法相比,VOQANet+无需人工设计的特征工程,能够自动学习语音质量的评估标准。
关键设计:VOQANet+的关键设计包括:1) 使用预训练的语音基础模型(如Wav2Vec 2.0、HuBERT等)提取语音嵌入;2) 选择合适的低层声学特征(如抖动、闪烁、HNR等),并进行归一化处理;3) 设计有效的特征融合策略,如拼接、加权平均等;4) 构建合适的深度学习模型,如带有注意力机制的LSTM或Transformer,用于语音质量评估;5) 使用均方根误差(RMSE)和Pearson相关系数等指标评估模型的性能。
🖼️ 关键图片


📊 实验亮点
实验结果表明,VOQANet+在CAPE-V和GRBAS维度上的RMSE和Pearson相关系数方面均优于基线模型,尤其是在句子级别评估中表现更佳。VOQANet+在噪声环境下也表现出更强的鲁棒性,证明了结合SFM嵌入和低层特征的有效性。具体性能提升数据需要在论文中查找。
🎯 应用场景
该研究成果可应用于远程医疗、语音治疗和语音疾病的早期诊断。通过客观、准确的语音质量评估,医生可以远程监测患者的病情变化,语音治疗师可以评估治疗效果,从而提高医疗效率和患者的生活质量。此外,该技术还可用于开发智能语音助手,帮助用户改善发音和语音表达。
📄 摘要(原文)
Perceptual voice quality assessment plays a vital role in diagnosing and monitoring voice disorders. Traditional methods, such as the Consensus Auditory-Perceptual Evaluation of Voice (CAPE-V) and the Grade, Roughness, Breathiness, Asthenia, and Strain (GRBAS) scales, rely on expert raters and are prone to inter-rater variability, emphasizing the need for objective solutions. This study introduces the Voice Quality Assessment Network (VOQANet), a deep learning framework that employs an attention mechanism and Speech Foundation Model (SFM) embeddings to extract high-level features. To further enhance performance, we propose VOQANet+, which integrates self-supervised SFM embeddings with low-level acoustic descriptors-namely jitter, shimmer, and harmonics-to-noise ratio (HNR). Unlike previous approaches that focus solely on vowel-based phonation (PVQD-A), our models are evaluated on both vowel-level and sentence-level speech (PVQD-S) to assess generalizability. Experimental results demonstrate that sentence-based inputs yield higher accuracy, particularly at the patient level. Overall, VOQANet consistently outperforms baseline models in terms of root mean squared error (RMSE) and Pearson correlation coefficient across CAPE-V and GRBAS dimensions, with VOQANet+ achieving even greater performance gains. Additionally, VOQANet+ maintains consistent performance under noisy conditions, suggesting enhanced robustness for real-world and telehealth applications. This work highlights the value of combining SFM embeddings with low-level features for accurate and robust pathological voice assessment.