Efficient Large Language Model Inference with Neural Block Linearization
作者: Mete Erdogan, Francesco Tonin, Volkan Cevher
分类: cs.LG, cs.AI
发布日期: 2025-05-27 (更新: 2025-10-19)
🔗 代码/项目: GITHUB
💡 一句话要点
提出神经块线性化(NBL)加速LLM推理,无需微调且精度损失小
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 模型推理 模型加速 线性化 典型相关分析 自注意力机制 无需微调
📋 核心要点
- Transformer LLM推理计算需求高,部署面临挑战,现有方法难以兼顾效率与精度。
- NBL用线性近似替换自注意力层,利用典型相关分析计算误差上界,指导层选择。
- 实验表明,NBL无需微调即可显著加速推理,例如DeepSeek-R1-Distill-Llama-8B加速32%。
📝 摘要(中文)
本文提出了一种名为神经块线性化(NBL)的新框架,旨在加速基于Transformer的大型语言模型(LLM)的推理过程。NBL通过使用线性最小均方误差估计器导出的线性近似来替换自注意力层,从而实现加速。该方法利用典型相关分析(Canonical Correlation Analysis)来计算近似误差的理论上限,并以此作为替换标准,选择线性化误差最小的LLM层。NBL可以直接应用于预训练的LLM,无需进行微调。实验结果表明,NBL在多个推理基准测试中实现了显著的计算加速,同时保持了具有竞争力的准确性。例如,将NBL应用于DeepSeek-R1-Distill-Llama-8B中的12个自注意力层,可以将推理速度提高32%,而准确性损失小于1%。这使得NBL成为一种灵活且有前景的解决方案,可以提高LLM的推理效率。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)推理过程中计算量大、速度慢的问题。现有的方法,如模型压缩、量化等,虽然可以加速推理,但往往会带来较大的精度损失,或者需要耗时的微调过程。因此,如何在保证精度的情况下,高效地进行LLM推理是一个重要的挑战。
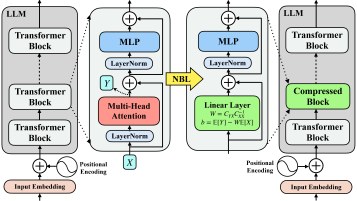
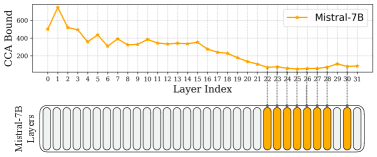
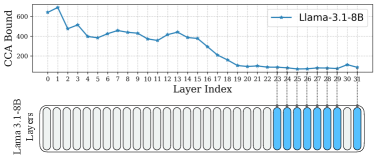
核心思路:论文的核心思路是用线性近似来替换Transformer模型中的自注意力层。自注意力层是Transformer模型中计算量最大的部分,通过将其替换为计算复杂度更低的线性层,可以显著加速推理过程。论文通过理论分析,利用典型相关分析(CCA)来估计线性近似的误差上界,并以此为依据选择需要替换的层,从而在精度和速度之间取得平衡。
技术框架:NBL框架主要包含以下几个阶段:1) 误差估计:使用CCA计算每个自注意力层线性近似的误差上界。2) 层选择:根据误差上界,选择误差最小的若干层进行替换。3) 线性化:使用线性最小均方误差(LMMSE)估计器计算选定层的线性近似。4) 模型替换:将原始模型中选定的自注意力层替换为对应的线性近似层。整个过程无需对模型进行微调。
关键创新:NBL最重要的技术创新点在于利用CCA来估计线性近似的误差上界。这种方法可以在不实际进行推理的情况下,预测线性近似对模型性能的影响,从而指导层的选择,避免了盲目替换可能带来的精度损失。此外,NBL无需微调,可以直接应用于预训练的LLM,降低了使用门槛。
关键设计:论文的关键设计包括:1) 使用CCA计算误差上界,具体而言,是将自注意力层的输入和输出视为两个随机变量,然后计算它们之间的典型相关系数,从而得到误差上界的估计。2) 使用LMMSE估计器计算线性近似,LMMSE估计器可以最小化线性近似的均方误差,从而保证近似的精度。3) 论文没有详细说明具体的参数设置,但强调了层选择的重要性,需要根据实际模型的结构和任务特点进行调整。
🖼️ 关键图片
📊 实验亮点
NBL在DeepSeek-R1-Distill-Llama-8B模型上进行了实验,结果表明,替换12个自注意力层可以将推理速度提高32%,而准确性损失小于1%。此外,NBL在多个推理基准测试中也取得了具有竞争力的结果,证明了其有效性和通用性。重要的是,NBL无需微调,可以直接应用于预训练的LLM,这大大降低了使用成本。
🎯 应用场景
NBL具有广泛的应用前景,可以应用于各种需要快速推理的场景,例如:实时对话系统、在线翻译、智能客服等。通过降低LLM的推理延迟,可以提升用户体验,并降低部署成本。此外,NBL还可以应用于资源受限的设备上,例如移动设备、嵌入式系统等,使得这些设备也能运行复杂的LLM模型。未来,NBL可以与其他模型压缩技术相结合,进一步提高LLM的推理效率。
📄 摘要(原文)
The high inference demands of transformer-based Large Language Models (LLMs) pose substantial challenges in their deployment. To this end, we introduce Neural Block Linearization (NBL), a novel framework for accelerating transformer model inference by replacing self-attention layers with linear approximations derived from Linear Minimum Mean Squared Error estimators. NBL leverages Canonical Correlation Analysis to compute a theoretical upper bound on the approximation error. Then, we use this bound as a criterion for substitution, selecting the LLM layers with the lowest linearization error. NBL can be efficiently applied to pre-trained LLMs without the need for fine-tuning. In experiments, NBL achieves notable computational speed-ups while preserving competitive accuracy on multiple reasoning benchmarks. For instance, applying NBL to 12 self-attention layers in DeepSeek-R1-Distill-Llama-8B increases the inference speed by 32% with less than 1% accuracy trade-off, making it a flexible and promising solution to improve the inference efficiency of LLMs. The implementation is available at: https://github.com/LIONS-EPFL/NBL.