Multi-level Certified Defense Against Poisoning Attacks in Offline Reinforcement Learning
作者: Shijie Liu, Andrew C. Cullen, Paul Montague, Sarah Erfani, Benjamin I. P. Rubinstein
分类: cs.LG, cs.AI
发布日期: 2025-05-27
💡 一句话要点
提出多层认证防御机制,提升离线强化学习抵抗投毒攻击的鲁棒性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 投毒攻击 认证防御 差分隐私 鲁棒性
📋 核心要点
- 离线强化学习依赖外部数据集,易受投毒攻击,现有防御方法鲁棒性不足。
- 利用差分隐私特性,提出多层认证防御机制,为状态动作和累积奖励提供鲁棒性保证。
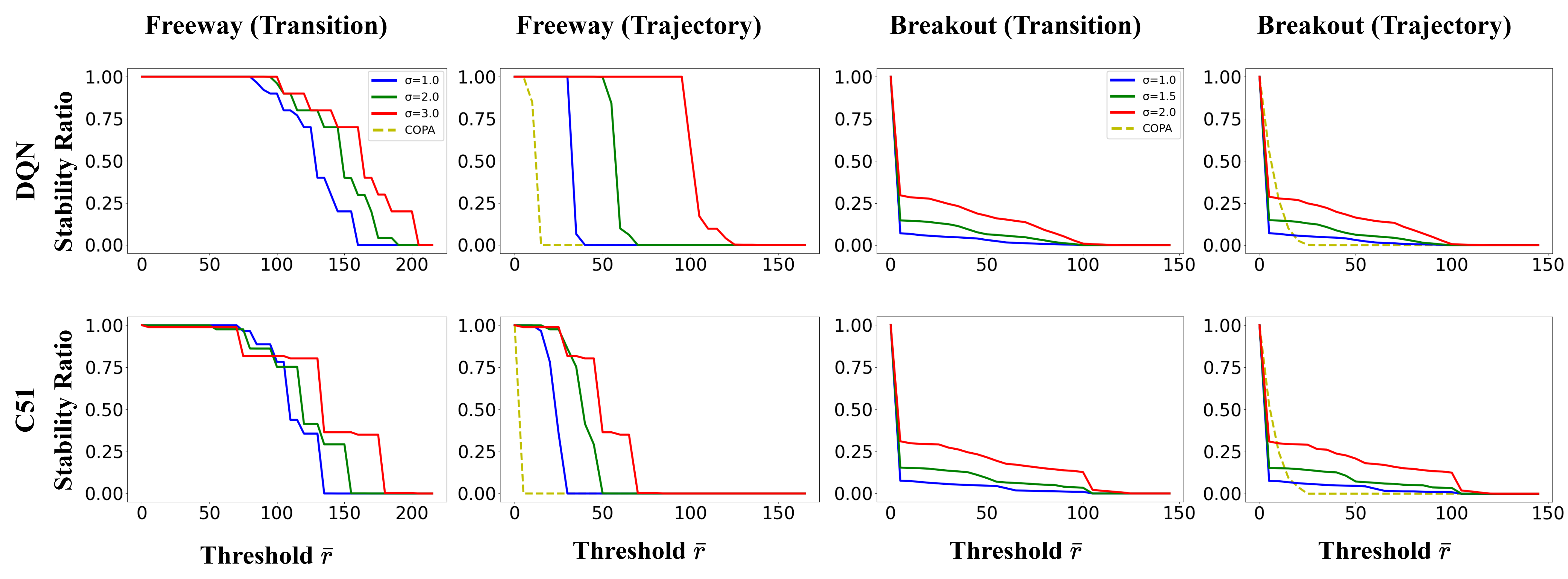
- 实验表明,该方法在更高比例投毒数据下性能下降更少,认证半径更大,提升了安全性和可靠性。
📝 摘要(中文)
本文研究了离线强化学习(RL)中存在的投毒攻击问题,由于离线RL依赖外部数据集,其顺序特性加剧了这种脆弱性。为了缓解RL投毒带来的风险,本文扩展了认证防御机制,为对抗性操纵提供更大的保证,确保了每个状态动作和整体预期累积奖励的鲁棒性。该方法利用差分隐私的特性,使其能够跨越连续和离散空间,以及随机和确定性环境,从而显著扩大了可实现保证的范围和适用性。实验评估表明,该方法确保了在高达7%的训练数据被投毒的情况下,性能下降不超过50%,显著优于先前工作中的0.008%,同时产生的认证半径也扩大了5倍。这突出了该框架在增强离线RL安全性和可靠性方面的潜力。
🔬 方法详解
问题定义:离线强化学习由于依赖外部数据集,容易受到投毒攻击,攻击者可以通过篡改训练数据来影响最终策略的性能。现有防御方法在面对高比例的投毒数据时,鲁棒性较差,认证半径较小,难以提供可靠的性能保证。因此,需要一种更有效的防御机制,能够在更强的攻击下保证离线RL策略的安全性。
核心思路:本文的核心思路是利用差分隐私的特性,对离线数据集进行处理,从而限制攻击者通过投毒数据对策略的影响。通过差分隐私,可以量化数据集中单个样本对最终策略的影响程度,从而为策略的鲁棒性提供认证保证。此外,本文还提出了多层认证防御机制,分别对每个状态动作和整体预期累积奖励进行认证,从而提供更全面的保护。
技术框架:该方法主要包含以下几个阶段:1) 数据预处理:对离线数据集进行差分隐私处理,例如添加噪声或进行数据聚合,以限制单个样本的影响。2) 策略学习:使用经过差分隐私处理的数据集训练离线RL策略。3) 认证:利用差分隐私的性质,计算策略的认证半径,即在一定范围内的投毒攻击下,策略性能的保证下限。4) 多层认证:分别对每个状态动作和整体预期累积奖励进行认证,提供更细粒度的保护。
关键创新:本文最重要的技术创新点在于将差分隐私与认证防御相结合,并将其扩展到离线强化学习中。与现有方法相比,该方法能够提供更强的鲁棒性保证,并且适用于连续和离散空间,以及随机和确定性环境。此外,多层认证防御机制能够提供更全面的保护,确保策略在不同层面上都具有鲁棒性。
关键设计:在数据预处理阶段,需要选择合适的差分隐私机制,例如高斯机制或拉普拉斯机制,并设置合适的隐私预算。在策略学习阶段,可以使用各种离线RL算法,例如Q-learning或Actor-Critic方法。在认证阶段,需要根据差分隐私的性质,计算策略的认证半径。多层认证防御机制需要分别设计针对状态动作和累积奖励的认证方法。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在高达7%的训练数据被投毒的情况下,性能下降不超过50%,显著优于先前工作中的0.008%。同时,该方法产生的认证半径也扩大了5倍,这意味着该方法能够提供更强的鲁棒性保证。这些结果表明,该方法能够有效地防御离线RL中的投毒攻击,并提高策略的安全性。
🎯 应用场景
该研究成果可应用于各种需要安全可靠的离线强化学习场景,例如自动驾驶、医疗诊断、金融交易等。在这些场景中,数据可能受到恶意攻击或污染,因此需要一种能够提供鲁棒性保证的防御机制。该方法可以提高离线RL策略的安全性,降低因数据投毒而导致的风险,从而促进离线RL在实际应用中的推广。
📄 摘要(原文)
Similar to other machine learning frameworks, Offline Reinforcement Learning (RL) is shown to be vulnerable to poisoning attacks, due to its reliance on externally sourced datasets, a vulnerability that is exacerbated by its sequential nature. To mitigate the risks posed by RL poisoning, we extend certified defenses to provide larger guarantees against adversarial manipulation, ensuring robustness for both per-state actions, and the overall expected cumulative reward. Our approach leverages properties of Differential Privacy, in a manner that allows this work to span both continuous and discrete spaces, as well as stochastic and deterministic environments -- significantly expanding the scope and applicability of achievable guarantees. Empirical evaluations demonstrate that our approach ensures the performance drops to no more than $50\%$ with up to $7\%$ of the training data poisoned, significantly improving over the $0.008\%$ in prior work~\citep{wu_copa_2022}, while producing certified radii that is $5$ times larger as well. This highlights the potential of our framework to enhance safety and reliability in offline RL.